





文 吴宇昊(宇毅),负责AnalyticDB PostgreSQL版查询优化研发工作
前言
01. 一站式全文检索业务痛点
通常情况下,我们在使用数据仓库进行文本数据的加工和分析业务时,离不开数据仓库的数据实时写入、全文检索及任务调度等能力。但是如何使用一套数仓系统完成上述所有功能,往往面临以下几个挑战:
● 如何使用全文检索功能,数据仓库内核的全文检索功能足够全面吗?部分数据仓库在全文检索功能上的的缺失,导致用户往往需要对文本数据做大量开发后才能将数据导入数据仓库;
● 如何调度大批量的全文检索、文本数据加工任务?任务调度依赖数据仓库内核的SQL标准支持能力,以及强大的外部工具支持;
● 如何保证全文检索的性能?全文检索涉及大量的文本数据,而数据仓库在处理文本数据时性能往往不如数字类型的数据;
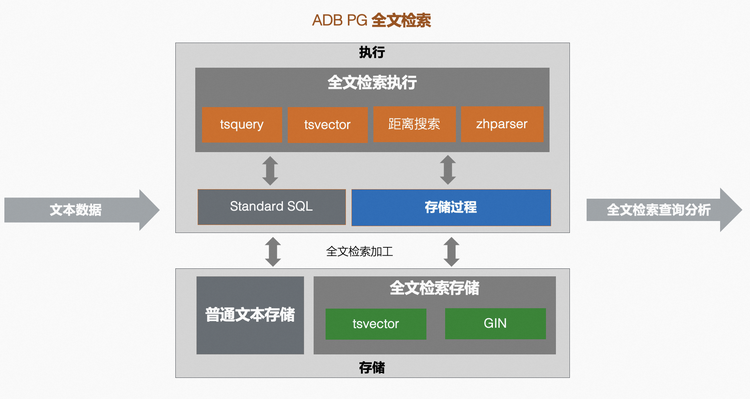
02. 全文检索
● 数据库常用的表达式查询方法无法处理派生词等语法,例如英文单词satisfy和它的第三人称形式satisfies。我们如果使用satisfy作为关键词查询,查询结果可能遗漏satisfies,这不是全文检索所期望看到的结果。当然我们可以使用表达式OR去同时匹配satisfy和satisfies,但是这样做非常低效率且容易出错(某些单词存在大量的派生词);
● 无法对根据匹配结果进行有效地排序,当查询结果较多时,筛选结果将变得非常低效;
2.1 全文检索的基本功能
2. 将符号转换为词语。相比较符号,词语经过了归一化(normalized)操作,将单词的不同形式进行了合并(例如上文提到的单词satisfy和satisfies),让全文检索功能可以根据语义高效检索。PG内核使用dictionaries(词典)进行这一步工作,同样提供了自定义dictionaries功能;
3. 优化词语存储,高效查询。例如,PG内核提供tsvector(text search vector)数据类型,将文本解析转换为带有词语信息的有序数据,并通过tsquery(text search query)语法对这类数据进行查询,实现高效的全文检索。
▶︎ tsvecyor
tsvector用于存放一系列去重(distinct)的词语和它们的顺序、位置等信息,使用PG提供的to_tsvector方法可以自动完成文本至tsvector的转换。我们以英文语句'a fat cat jumped on a mat and ate two fat rats'为例:
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats');to_tsvector---------------------------------------------------------------'ate':9 'cat':3 'fat':2,11 'jump':4 'mat':7 'rat':12 'two':10(1 row)
tsvector将文本完成了预计算和转换,接下来我们需要tsquery来查询分析tsvector。
▶︎ tsquery
tsquery用于存放查询tsvector的词语,PG同样提供to_tsquery方法将文本转换为tsquery,结合tsvector及全文检索操作符,就可以完成全文检索查询。
例如,我们可以使用 @@ 操作符查找tsvector中是否包含tsquery的词语:
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat');?column?----------t(1 row)postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cats');?column?----------t(1 row)
tsquery支持Boolean操作符 & (AND)、| (OR) 和 ! (NOT),可以方便地构建组合条件的检索查询:
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat | dog');?column?----------t(1 row)postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat & dog');?column?----------f(1 row)
▶︎ 距离搜索
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1>jump');?column?----------t(1 row)
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<2>mat');?column?----------f(1 row)postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<4>mat');?column?----------t(1 row)
postgres=# select to_tsvector('a fat cat jumped on a mat and ate two fat rats') @@ to_tsquery('cat<1,5>mat');?column?----------t(1 row)
2.2 中文全文检索功能
postgres=# select to_tsvector('你好,这是一条中文测试文本');to_tsvector-----------------------------------'你好':1 '这是一条中文测试文本':2(1 row)
▶︎ 中文分词:zhparser插件
zhparser插件是一个基于SCWS能力开发的PG中文分词插件,在兼容PG已有全文检索能力的基础上,提供丰富的功能配置选项,同时也提供用户自定义词典功能。
在ADB PG中,zhparser插件已完成默认安装,用户可以根据中文分词需求自定义配置zhparser,例如创建一个名为"zh_cn"的中文分词解析器并配置分词策略:
--- 创建分词解析器CREATE TEXT SEARCH CONFIGURATION zh_cn (PARSER = zhparser);--- 添加名词(n)、动词(v)、形容词(a)、成语(i)、叹词(e)和习用语(l)、自定义(x)分词策略ALTER TEXT SEARCH CONFIGURATION zh_cn ADD MAPPING FOR n,v,a,i,e,l,x WITH simple;
更多的插件使用方法可以参考:
https://help.aliyun.com/document_detail/209458.html
完成基本配置后,我们可以使用中文分词能力开发中文检索业务,使用示例如下:
postgres=# select to_tsvector('zh_cn','你好,这是一条中文测试文本');to_tsvector----------------------------------------------'中文':3 '你好':1 '文本':5 '测试':4 '这是':2(1 row)
postgres=# select to_tsvector('zh_cn','你好,这是一条中文测试文本') @@ to_tsquery('zh_cn','中文<1,3>文本');?column?----------t(1 row)
▶︎ 自定义词库
Table "zhparser.zhprs_custom_word"Column | Type | Collation | Nullable | Default--------+------------------+-----------+----------+-----------------------word | text | | not null |tf | double precision | | | '1'::double precisionidf | double precision | | | '1'::double precisionattr | character(1) | | | '@'::bpcharIndexes:"zhprs_custom_word_pkey" PRIMARY KEY, btree (word)Check constraints:"zhprs_custom_word_attr_check" CHECK (attr = '@'::bpchar OR attr = '!'::bpchar)
在ADB PG中,自定义词库是数据库级别的,存放于每个数据节点对应数据库的数据目录下。下面展示如何在ADB PG中使用自定义词库功能。
以前文示例语句'你好,这是一条中文测试文本’为例,如果我们期望'测试'和'文本'不要拆分为两个词语,而是以'测试文本'作为一个单独的分词,那么只需要在zhparser.zhprs_custom_word系统表中插入对应分词,重载后即可生效:
postgres=# insert into zhparser.zhprs_custom_word values('测试文本');INSERT 0 1postgres=# select sync_zhprs_custom_word(); --加载自定义分词sync_zhprs_custom_word------------------------(1 row)postgres=# \q --重新建立连接postgres=# select to_tsvector('zh_cn','你好,这是一条中文测试文本');to_tsvector-----------------------------------------'中文':3 '你好':1 '测试文本':4 '这是':2(1 row)
postgres=# insert into zhparser.zhprs_custom_word(word, attr) values('这是','!');INSERT 0 1postgres=# select sync_zhprs_custom_word();sync_zhprs_custom_word------------------------(1 row)postgres=# \q --重新建立连接postgres=# select to_tsvector('zh_cn','你好,这是一条中文测试文本');to_tsvector---------------------------------------'中文':3 '你好':1 '是':2 '测试文本':4(1 row)
2.3 全文检索索引
现在存在一张数据表(Document),存放了一系列的文本(Text),同时每条文本都有一个对应的编号(ID),这张表的结构如下:
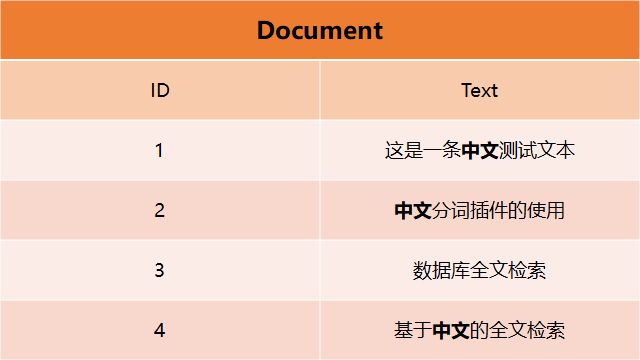
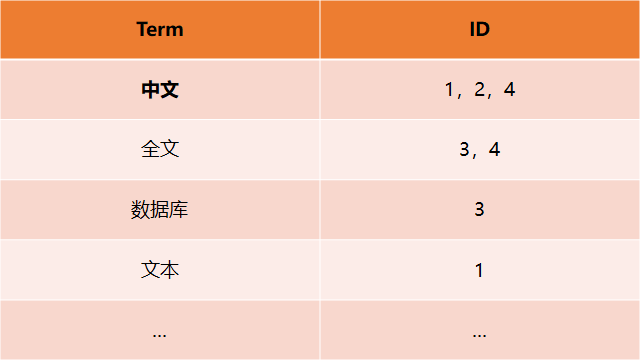
当我们想查找出所有包含"中文"这个词语的文本,在这个数据结构下需要逐条检索Text的全部内容。当数据量大时,做这一步查询将会有非常大的代价。而通过建立倒排索引可以解决此问题,其索引结构包含每条文本中的词语,及词语对应出现的文本位置。一个可能的倒排索引数据结构如下:
CREATE INDEX text_idx ON document USING GIN (to_tsvector('zh_cn',text));
03. 存储过程
3.1 存储过程的特性
● 存储过程整合了一些列SQL,并分隔不同业务的SQL。这种特性使得存储过程易于维护,极大地提升数据库开发者的效率;
● 调用存储过程非常简单,数据库开发者可以高效地在不同业务场景中复用存储过程;
ADB PG存储过程语法与SQL标准基本相同,如下:
CREATE [ OR REPLACE ] PROCEDUREname ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] ){ LANGUAGE lang_name| TRANSFORM { FOR TYPE type_name } [, ... ]| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER| SET configuration_parameter { TO value | = value | FROM CURRENT }| AS 'definition'| AS 'obj_file', 'link_symbol'} ...
3.2 存储过程与函数
在ADB PG 6.0版本中,函数(Function)可以实现大部分的存储过程功能,我们通常建议用户使用函数来实现存储过程业务,但是存储过程仍然是许多ADB PG用户、及PostgresSQL从业者们期待已久的功能,具体原因主要为:
● 存储过程使用CREATE PROCEDURE语法,并通过CALL调用,符合SQL语法标准,减少用户从其它支持存储过程数据库的业务迁移至ADB PG的工作量;
● 存储过程支持内部开启事务块,进行事务提交(Commit)或者事务回滚(Rollback),而函数无此功能,只能整体提交或回滚一个事务;
● 存储过程无类似Function的返回值,但是可以通过output参数获取返回结果。
04. 分布式数据仓库
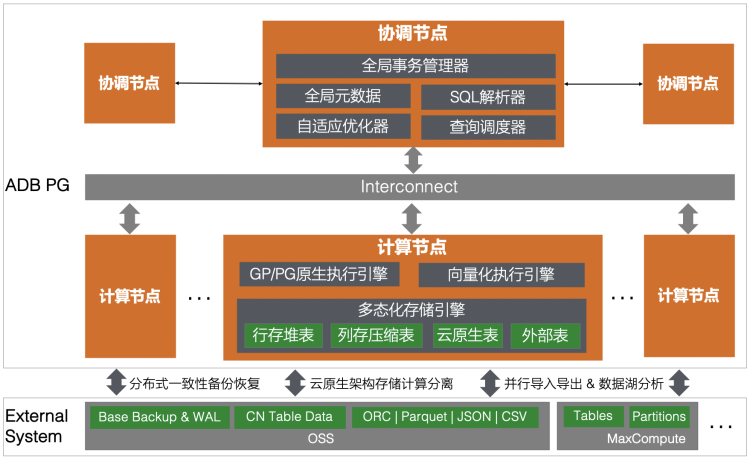
ADB PG由协调节点和计算节点两大组件构成,协调节点负责全局事务管理,全局元数据存储,SQL解析,重写,执行计划生成及计划自适应优化、计算调度等功能;计算节点主要包含执行引擎和存储引擎,其中执行引擎既支持Greenplum/PostgreSQL功能强大的原生引擎,又支持数据分析场景性能优化的自研向量化引擎,多态化存储引擎则支持本地行存堆表、列存压缩表,和外部表,以及基于存储计算分离架构下的云原生表。协调节点和计算节点通过双副本保障高可用,同时通过水平和垂直扩展提供计算和存储资源的线性扩容。
05. 案例:ADB PG助力彩数实现全文检索加工及分析
接来下我们以彩数的业务场景做示例案例,展示ADB PG如何实现一站式全文检索实时分析业务,该示例的业务背景为:某产品销售平台经过长时间经营,存在大量产品A的使用评价历史数据,同时每日还会不断收到该产品新的评价数据,也称为每日增量数据。现在该平台希望将每日新评价与历史评价信息写入ADB PG,进行数据加工并从多维度分析客户对产品的评价。
* 注:实际业务场景可能比本文案例复杂许多,本案例仅做示范使用。
5.1 数据写入/同步
CREATE TABLE product_customer_reply (customer_id INTEGER, -- 用户IDgender INTEGER, -- 性别age INTEGER, -- 年龄------ 可包含用户的相关信息---reply_time TIMESTAMP, -- 评论时间reply TEXT -- 评论内容) DISTRIBUTED BY(customer_id);
\COPY product_customer_reply FROM '/path/localfile' DELIMITER as '|';
增量数据部分,我们同样可以使用COPY方法批量攒批数据加载,也可以结合应用程序使用ADB PG client-SDK攒批写入,具体可参考:
https://help.aliyun.com/document_detail/126644.html
此外,如果业务数据已使用TP数据库,那么可以通过DTS服务进行表结构/全量数据同步,也可以配置增量同步实时更新数据。
5.2 全文检索
使用全文检索功能前,首先要对中文分词进行配置。ADB PG默认对中文分词做了基本配置,一般情况下用户可以直接使用中文分词功能即可,当然用户应结合业务对中文分词进行定制化配置。例如,本案例中我们期望中文分词能将产品名,品牌名这些非默认分词加入自定义词库:
-- 添加自定义分词INSERT INTO zhparser.zhprs_custom_word VALUES('产品A');INSERT INTO zhparser.zhprs_custom_word VALUES('品牌A');
SELECT count(*) from product_customer_reply where to_tsvector('zh_cn', reply) @@ to_tsquery('zh_cn','产品A<1,10>购买') AND to_tsvector('zh_cn', reply) @@ to_tsquery('zh_cn','产品A<1,10>好');
SELECT count(*) FROM product_customer_reply WHERE reply_ts @@ to_tsquery('zh_cn','产品A<1,10>购买') AND reply_ts @@ to_tsquery('zh_cn','产品A<1,10>好');count--------428571(1 row)Time: 7625.684 ms (00:07.626)
CREATE INDEX on product_customer_reply USING GIN (to_tsvector('zh_cn',reply));
SELECT count(*) FROM product_customer_reply WHERE to_tsvector('zh_cn', reply) @@ to_tsquery('zh_cn','产品A<1,10>购买') AND to_tsvector('zh_cn', reply) @@ to_tsquery('zh_cn','产品A<1,10>好');count--------428571(1 row)Time: 4539.930 ms (00:04.540)
ALTER TABLE product_customer_reply ADD COLUMN reply_ts tsvector;
CREATE INDEX ON product_customer_reply USING GIN (reply_ts);
SELECT count(*) FROM product_customer_reply WHERE reply_ts @@ to_tsquery('zh_cn','产品A’<1,10>‘购买') AND reply_ts @@ to_tsquery('zh_cn','产品A’<1,10>‘好');count--------428571(1 row)Time: 465.849 ms
5.3 数据加工
完成全文检索设计后,我们可以批量加工产品的所有评论数据,将文本数据的特征、分组特性提取出来哦用户分析查询。数据加工任务可能涉及到全量数据的大量SQL处理,因此可以使用存储过程来控制加工任务。例如,我们可以建立ts_search_detail表,存放一些列的全文检索查询条件:
CREATE TABLE ts_search_detail (search_id INTEGER,ts_search_text TEXT) DISTRIBUTED BY(id);
此外建立proc_results表用于存放加工后的结果,这里我们建立了一张经过全文检索分析后的,用户id、性别、年龄信息的明细表:
CREATE TABLE proc_results (id INTEGER,gender INTEGER,age INTEGER,search_id INTEGER) DISTRIBUTED BY(id);
CREATE OR REPLACE PROCEDURE ts_proc_jobs()AS $$DECLAREts_search record;proc_query text;BEGINFOR ts_search IN (SELECT ts_search_text, search_id FROM ts_search_detail) LOOPproc_query := '';proc_query := 'INSERT INTO proc_results (id, gender, age, search_id)SELECT customer_id, gender, age, '|| ts_search.search_id|| 'FROM product_customer_reply WHERE '|| ts_search.ts_search_text;execute(proc_query);commit;raise notice 'search id % finish', ts_search.search_id;END LOOP;END;$$LANGUAGE 'plpgsql';




 点击「阅读原文」了解云原生数据仓库AnalyticDB PostgreSQL更多信息
点击「阅读原文」了解云原生数据仓库AnalyticDB PostgreSQL更多信息
