




每个数据库索引结构不尽相同,根据各官方文档的介绍整理,对比各个数据库的索引便于牢记。
一、Oracle 索引
官方文档:
1、索引详解
索引是依赖表创建的对象。您可以在表上创建索引以提高查询性能。正如索引可以帮助您快速定位信息一样,通过索引可以快速访问表数据。您可以根据需要在表上创建任意数量的索引。您可以在表的一列或多列上创建每个索引。对表的数据或结构所做的更改,如添加新行、更新行或删除行,都会自动合并到所有相关索引中。一些索引是通过放置在表上的约束隐式创建的。例如,数据库会自动在主键约束或唯一键约束的列上创建索引。索引通常可以提高对单个现有行或少量现有行进行操作的查询和DML语句的性能。但是,索引过多会增加添加、修改或删除行的语句的处理开销。
2、索引类型
- 标准的B树索引包含索引键中每个值的一个条目,以及存储该值的行的磁盘地址。B树索引是Oracle数据库中默认的也是最常见的索引类型。索引组织表、反转键索引、降序索引、B树簇索引都是B树索引结构。
- 位图索引使用位字符串来封装值和潜在的行地址。它比B树索引更紧凑,并且可以更有效地执行某些类型的检索。然而,对于一般用途,位图索引在表的行操作过程中需要更多的开销,并且应该主要用于数据仓库环境。在位图索引中,索引项使用位图指向多行。相比之下,B树索引条目指向一行。位图连接索引是用于连接两个或多个表管理查询的索引。
- 升序ASC和降序DESC:索引的默认搜索是从最低值到最高值,默认也就是ASC排序,其中字符数据按ASCII值排序,数字数据按最小值到最大值排序,日期按最早值到最新值排序。此默认搜索方法在创建为升序索引的索引中执行。通过使用降序DESC选项创建相关索引,可以使索引搜索颠倒搜索顺序。
- 函数索引:在列上加上函数的结果索引。
- 分区索引:与表一样,您可以对索引进行分区,也就是本地索引。可以在分区表上创建非分区索引或全局索引。
B-Tree Index Subtypes
| B-Tree Index Subtype | Description | To Learn More |
|---|---|---|
Index-organized tables | An index-organized table differs from a heap-organized because the data is itself the index. | "Overview of Index-Organized Tables" |
Reverse key indexes | In this type of index, the bytes of the index key are reversed, for example, 103 is stored as 301. The reversal of bytes spreads out inserts into the index over many blocks. | "Reverse Key Indexes" |
Descending indexes | This type of index stores data on a particular column or columns in descending order. | "Ascending and Descending Indexes" |
B-tree cluster indexes | This type of index stores data on a particular column or columns in descending order. | "Ascending and Descending Indexes" |
Indexes Not Using a B-Tree Structure
| Type | Description | To Learn More |
|---|---|---|
Bitmap and bitmap join indexes | In a bitmap index, an index entry uses a bitmap to point to multiple rows. In contrast, a B-tree index entry points to a single row. A bitmap join index is a bitmap index for the join of two or more tables. | "Overview of Bitmap Indexes" |
Function-based indexes | This type of index includes columns that are either transformed by a function, such as the | "Overview of Function-Based Indexes" |
Application domain indexes | A user creates this type of index for data in an application-specific domain. The physical index need not use a traditional index structure and can be stored either in the Oracle database as tables or externally as a file. | "Overview of Application Domain Indexes" |
(原文:Space available for index data in a data block is the data block size minus block overhead, entry overhead, rowid, and one length byte for each value indexed.)
索引块包括:Root block、Branch blocks、Leaf blocks
根块:此块标识索引的入口点。
分支块:在搜索索引键时,数据库会在分支块中确定叶块位置。
叶块:这些块包含指向关联行的索引键值rowid。叶块按排序顺序存储键值,以便数据库可以有效地搜索键值范围内的所有行。
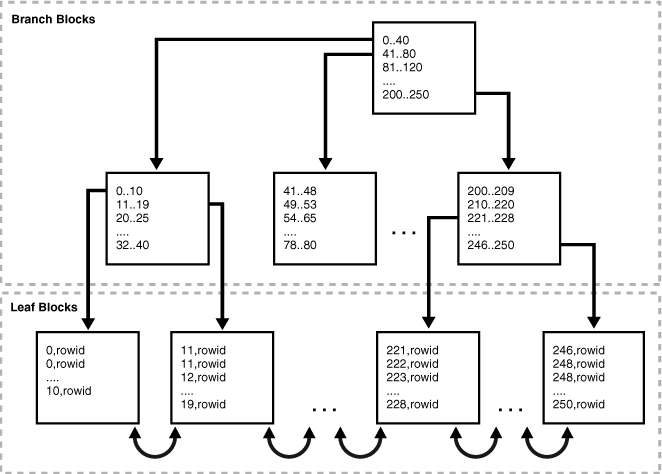
索引条目的存储
索引条目与数据块中的表行相同的方式存储在索引块中。块部分中的索引条目不是以二进制顺序存储的,而是以堆的形式存储的。
数据库管理索引块中的行目录不同于数据块中的目录。行目录中的条目(而不是索引块主体中的条目)是按键值排序的。例如,在行目录中,索引键000000的目录条目在索引键111111的目录条目之前,依此类推。
行目录中条目的排序提高了索引扫描的效率。在范围扫描中,数据库必须读取范围中指定的所有索引键。数据库遍历分支块以识别包含第一个关键字的叶块。由于行目录中的条目是经过排序的,因此数据库可以使用二进制搜索来查找该范围中的第一个索引键,然后按顺序遍历行目录的条目,直到找到最后一个键。通过这种方式,数据库可以避免读取叶块主体中的所有键。
索引块中插槽的重用
数据库可以重用索引块内的空间。
例如,应用程序可以在列中插入一个值,然后删除该值。当一行需要空间时,数据库可以重用以前被删除值占用的索引槽。
索引块通常比堆组织的表块具有更多的行。在单个索引块中存储多行的能力使数据库更容易维护索引,因为它避免了频繁拆分块来存储新数据。
虽然可以使用ALTER INDEX语句REBUILD或coalesce选项手动合并索引,但索引本身无法自己合并。例如,如果用值1到500000填充一列,然后删除包含偶数的行,则索引将包含250000个空槽。只有当数据库可以插入适合包含空槽的索引块的数据时,它才会重用槽。
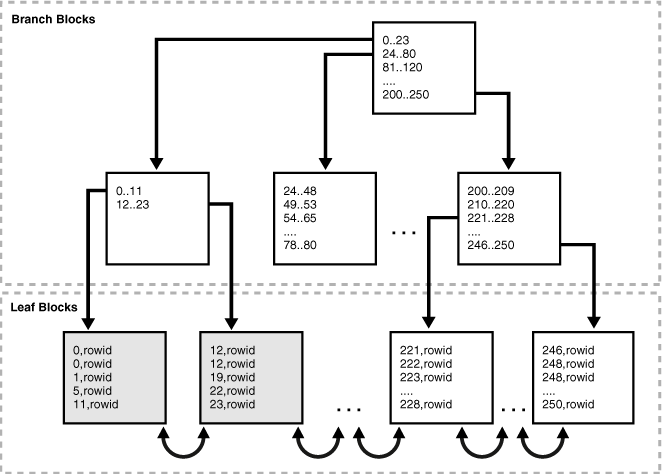
合并索引块
索引合并将现有索引数据压缩到适当的位置,如果重组释放块,则将空闲块留在索引结构中。因此,合并不会释放索引块用于其他用途,也不会导致索引重新分配块。
Oracle数据库不会自动压缩索引:使用ALTER INDEX语句REBUILD或coalesce选项手动合并索引。
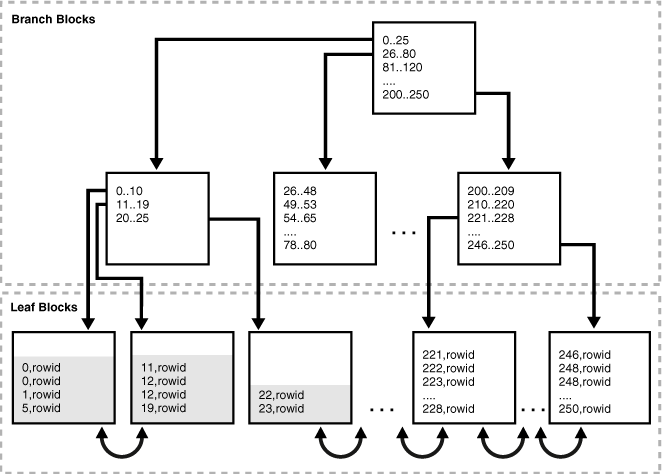
合并之后:
二、MySQL索引
官方文档:
https://dev.mysql.com/doc/refman/8.0/en/innodb-physical-structure.html
https://dev.mysql.com/doc/refman/8.0/en/glossary.html#glos_b_tree
https://dev.mysql.com/doc/refman/8.0/en/innodb-physical-structure.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-fulltext-index.html
1、索引详解
众所周知,MySQL数据库是B+树索引结构。一种常用于数据库索引的树型数据结构。该结构始终保持排序,从而能够快速查找精确匹配( = ) 和范围(例如,>、<和BETWEEN运算符)。这种类型的索引可用于大多数存储引擎,如InnoDB和MyISAM。由于B+树节点可以有许多子节点,因此B+树与二叉树不同,二叉树每个节点只能有2个子节点。与HASH索引形成对比,HASH索引仅在MEMORY存储引擎中可用,仅用于使用=或<=>运算符的相等比较(但速度非常快)。HASH index不用于查找值范围的比较运算符,如<。依赖这种类型的单值查找的系统被称为“键值存储”;要将MySQL用于此类应用程序,请尽可能使用HASH index ;优化器无法使用HASH index来加快ORDER BY操作的速度(这种类型的索引不能用于按顺序搜索下一个条目。)MEMORY存储引擎也可以使用B树索引,如果某些查询使用范围运算符,则应该为MEMORY表选择B树索引。MySQL存储引擎使用的B树结构可能被视为变体,因为经典的B树设计中没有复杂的结构。B树索引可用于使用=、>、>=、<、<=或BETWEEN运算符的表达式中的列比较。如果LIKE的参数是一个不以通配符开头的常量字符串,则索引也可以用于LIKE比较。如果对col_name列创建了索引,则col_name IS NULL的搜索也会使用索引。有时MySQL不使用索引,即使有可用的索引。发生这种情况的一种情况是,优化器估计使用索引需要MySQL访问表中很大比例的行。(在这种情况下,全表扫描可能会更快,因为它需要更少的回表。)然而,如果这样的查询使用LIMIT只检索其中的一些行,MySQL无论如何都会使用索引,因为它可以更快地找到结果中返回的少数行。
每个InnoDB表都有一个特殊的索引,称为CLUSTER INDEX,用于存储行数据。CLUSTER INDEX等同于主键。为了从查询、插入和其他数据库操作中获得最佳性能,InnoDB使用CLUSTER INDEX来优化公共查找和DML操作是很重要的。当在表上定义PRIMARY KEY时,InnoDB会将其作为CLUSTER INDEX。应该为每个表定义一个主键。如果没有逻辑唯一、非null列、主键列,请添加一个自增列。自动递增列值是唯一的,并且在插入新行时自动添加。如果没有为表定义PRIMARY KEY,InnoDB将使用第一个UNIQUE索引作为CLUSTER INDEX,其中所有键列都定义为not NULL。如果表没有PRIMARY KEY或合适的UNIQUE索引,InnoDB会在包含行ID值的合成列上生成一个名为GEN_CLUST_index的隐藏聚集索引。这些行按照InnoDB分配的行ID进行排序。行ID是一个6字节的字段,随着新行的插入而单调增加。因此,按行ID排序的行在物理上是按插入顺序排列的。
CLUSTER INDEX如何加速查询,通过聚集索引访问行很快,因为索引搜索会直接指向包含行数据的页面。如果表很大,与使用不同于索引记录的页面存储行数据的存储组织相比,CLUSTER INDEX体系结构通常会保存磁盘I/O操作。
Secondary Indexes与CLUSTER INDEX的关系,CLUSTER INDEX以外的索引称为Secondary Indexes。在InnoDB中,Secondary Indexe中的每条记录都包含该行的主键列,以及为二级索引指定的列。InnoDB使用这个主键值来搜索CLUSTER INDEX中的行。如果主键很长,则辅助索引会占用更多空间,因此要使用短主键。InnoDB支持虚拟列上建Secondary Indexes,在虚拟列上定义的secondary index有时被称为“virtual index”,
2、索引类型
Table 15.1 InnoDB Storage Engine Features
Feature Support B-tree indexes Yes Backup/point-in-time recovery (Implemented in the server, rather than in the storage engine.) Yes Cluster database support No Clustered indexes Yes Compressed data Yes Data caches Yes Encrypted data Yes (Implemented in the server via encryption functions; In MySQL 5.7 and later, data-at-rest encryption is supported.) Foreign key support Yes Full-text search indexes Yes (Support for FULLTEXT indexes is available in MySQL 5.6 and later.) Geospatial data type support Yes Geospatial indexing support Yes (Support for geospatial indexing is available in MySQL 5.7 and later.) Hash indexes No (InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature.) Index caches Yes Locking granularity Row MVCC Yes Replication support (Implemented in the server, rather than in the storage engine.) Yes Storage limits 64TB T-tree indexes No Transactions Yes Update statistics for data dictionary Yes
Full-text:
其他索引已做了对比和介绍,下面主要介绍一下文本类型的FULL-TEXT索引。在基于文本的列(CHAR、VARCHAR或text列)上创建全文索引,以加快对这些列中包含的数据的查询和DML操作。
InnoDB全文索引采用反向索引设计。反向索引存储word列表,对于每个word,存储该word出现的文件列表。为了支持邻近搜索,还存储每个单词的位置信息,作为字节偏移量。
InnoDB Full-Text Index Tables:
mysql> CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200),
FULLTEXT idx (opening_line)
) ENGINE=InnoDB;
mysql> SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES
WHERE name LIKE 'test/%';
+----------+----------------------------------------------------+-------+
| table_id | name | space |
+----------+----------------------------------------------------+-------+
| 333 | test/fts_0000000000000147_00000000000001c9_index_1 | 289 |
| 334 | test/fts_0000000000000147_00000000000001c9_index_2 | 290 |
| 335 | test/fts_0000000000000147_00000000000001c9_index_3 | 291 |
| 336 | test/fts_0000000000000147_00000000000001c9_index_4 | 292 |
| 337 | test/fts_0000000000000147_00000000000001c9_index_5 | 293 |
| 338 | test/fts_0000000000000147_00000000000001c9_index_6 | 294 |
| 330 | test/fts_0000000000000147_being_deleted | 286 |
| 331 | test/fts_0000000000000147_being_deleted_cache | 287 |
| 332 | test/fts_0000000000000147_config | 288 |
| 328 | test/fts_0000000000000147_deleted | 284 |
| 329 | test/fts_0000000000000147_deleted_cache | 285 |
| 327 | test/opening_lines | 283 |
+----------+----------------------------------------------------+-------+mysql> SELECT index_id, name, table_id, space from INFORMATION_SCHEMA.INNODB_INDEXES
WHERE index_id=457;
+----------+------+----------+-------+
| index_id | name | table_id | space |
+----------+------+----------+-------+
| 457 | idx | 327 | 283 |
+----------+------+----------+-------+
前六个索引表包括反向索引,并且被称为辅助索引表。当新的文件被标记时,个别单词(也称为“tokens”)与位置信息和相关的DOC_ID一起被插入索引表中。根据单词第一个字符的字符集排序权重,在六个索引表中对单词进行完全排序和分区。反向索引被划分为六个辅助索引表,以支持并行索引创建。默认情况下,两个线程对索引表中的单词和相关数据进行标记、排序和插入。执行这项工作的线程数可以使用innodb_ft_sort_pll_degree变量进行配置。在大型表上创建全文索引时,请考虑增加线程数。辅助索引表名称以fts_为前缀,以index_#为后缀。每个辅助索引表通过与索引表的table_id匹配的辅助索引表名称中的十六进制值与索引表相关联。例如,test/opening_lines表的table_id为327,其十六进制值为0x147。如前一示例所示,“147”十六进制值出现在与test/opening_lines表关联的辅助索引表的名称中。表示全文索引的index_id的十六进制值也出现在辅助索引表名称中。例如,在辅助表名test/fts_0000000000000147_00000000000001c9_index_1中,十六进制值1c9的十进制值为457。opening_lines表(idx)上定义的索引可以通过查询Information_Schema.INNODB_INDEXES表中的该值来识别(457)。如果主表是file-per-table表空间中创建,则索引表存储自己的表空间中。否则,索引表将存储在主表所在的表空间中。
前面示例中显示的其他索引表被称为通用索引表,用于删除处理和存储全文索引的内部状态。与为每个全文索引创建的反向索引表不同,这组表对于在特定表上创建的所有全文索引都是通用的。即使删除了全文索引,也会保留通用索引表。删除全文索引时,会保留为索引创建的FTS_DOC_ID列,因为删除FTS_DOC_ID列需要重新生成以前的索引表。需要通用索引表来管理FTS_DOC_ID列。
fts_*_deleted and fts_*_deleted_cache
包含已删除但其数据尚未从全文索引中删除的文件ID(DOC_ID)。fts_*_deleted_cache是fts_*_deleted表的内存版本。
fts_*_being_deleted and fts_*_being_deleted_cache
包含已删除文件ID(DOC_ID),这些文档的数据当前正在从全文索引中删除。fts_*_being_deleted_cache表是fts_*_being_deleted表的内存版本。
fts_*_config
存储有关全文索引的内部状态的信息。最重要的是,它存储FTS_SYNCED_DOC_ID,用于标识已解析并刷新到磁盘的文件。在崩溃恢复的情况下,FTS_SYNCED_DOC_ID值用于标识尚未刷新到磁盘的文件,以便可以重新解析这些文件并将其添加回全文索引缓存。要查看此表中的数据,请查询Information Schema INNODB_FT_CONFIG表。
InnoDB全文索引由于其缓存和批处理行为而具有特殊的事务处理特性。具体来说,全文索引上的更新和插入是在事务提交时处理的,这意味着全文搜索只能看到提交的数据。
3、索引存储结构
除了空间索引之外,InnoDB索引是B-树数据结构。空间索引使用R树,这是用于索引多维数据的专用数据结构。索引数据存储在其B树或R树数据结构的叶节点页中。索引页的默认大小为16KB。MySQL实例初始化时,页面大小由innodb_page_size设置决定。
当新的记录被插入到InnoDB cluster index中时,InnoDB会尝试留出1/16的页面,以供将来插入和更新索引记录。如果按顺序(升序或降序)插入索引记录,则索引页写约15/16。如果按随机顺序插入记录,则索引页写1/2到15/16。
InnoDB在创建或重建B树索引时执行大容量加载。这种创建索引的方法被称为排序索引构建。innodb_fill_actor变量定义了在排序索引构建过程中每个B树页面上填充的空间百分比,剩余空间保留用于未来索引增长。空间索引不支持排序索引创建方式。innodb_fill_actor设置为100会使聚集索引页中的1/16空间为将来的索引增长留出空间。保留的空间量可能会与参数配置的不完全一样,因为innodb_fill_actor值不是硬限制。
如果InnoDB索引页的数据低于MERGE_THRESHOLD(如果未指定,默认为50%),InnoDB会尝试收缩索引树以释放该页。MERGE_THRESHOLD设置适用于B树索引和R树索引。当降低MERGE_THRESHOLD值时,减少页面合并尝试次数并使成功率提高,MERGE_THRESHOLD设置太小可能会产生过多的空页面空间而导致数据文件过大。
InnoDB在创建或重建索引时执行大容量加载,而不是一次插入一个索引记录。这种创建索引的方法也称为排序索引构建。空间索引不支持排序索引生成。
索引构建分为三个阶段。
在第一阶段,扫描clustered index,生成索引条目并将其添加到sort buffer。当排序缓冲区已满时,将对条目进行排序并将其写入临时中间文件。这个过程也称为“run”。
在第二阶段,将一个或多个runs写入临时中间文件,对文件中的所有条目执行合并排序。
在第三个也是最后一个阶段,已排序的条目被插入到B-树中。
在引入排序索引构建之前,索引条目是使用insert API一次一条记录地插入到B树中的。这种方法包括打开B-tree cursor以找到插入位置,然后使用乐观插入将条目插入到B树页面中。如果由于页面已满而导致插入失败,则将执行悲观插入,这包括打开B-tree cursor,并根据需要拆分和合并B树节点以查找条目的空间。这种“自上而下”的索引构建方法的缺点是搜索插入位置的成本以及B树节点的不断拆分和合并。
排序索引构建使用“自下而上”的方法来构建索引。通过这种方法,在B树的所有级别上都保留了对最右侧叶子节点页的引用。在B-树深处的最右边的叶子节点页被分配,并且条目根据它们的排序顺序被插入。一旦一个叶子节点页已满,就会将这个节点指针附加到父节点,并为下一次插入分配一个同级叶子节点页。此过程一直持续到插入所有条目,也可能插入到根节点。分配同级页时,将释放对先前固定的叶页的引用,并且新分配的叶页将成为最右侧的叶页和新的默认插入位置。
排序索引创建方式也适用FULL-TEXT索引创建。
在排序索引生成过程中,将禁用重做日志记录。相反,有一个检查点来确保索引构建能够承受意外退出或失败。检查点强制将所有脏页写入磁盘。在排序索引构建过程中,会定期向页面清理线程发出信号,以清除脏页面,从而确保可以快速处理检查点操作。通常,当干净页面的数量低于设置的阈值时,页面清理线程会清除脏页面。对于排序的索引构建,脏页会被迅速刷新,以减少检查点开销,并使I/O和CPU活动并行化。
********************未完待续********************
