





测试概况
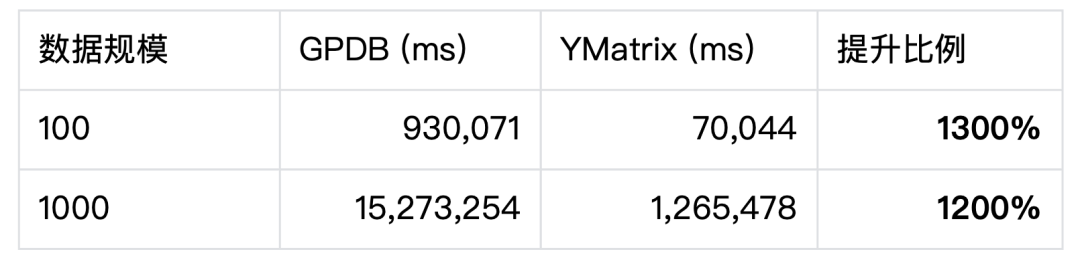
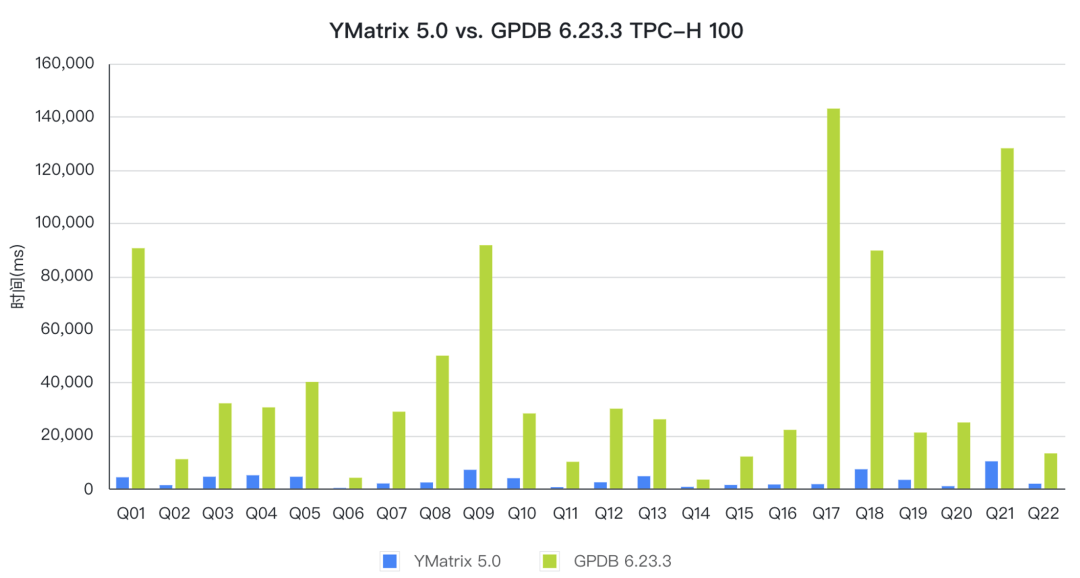
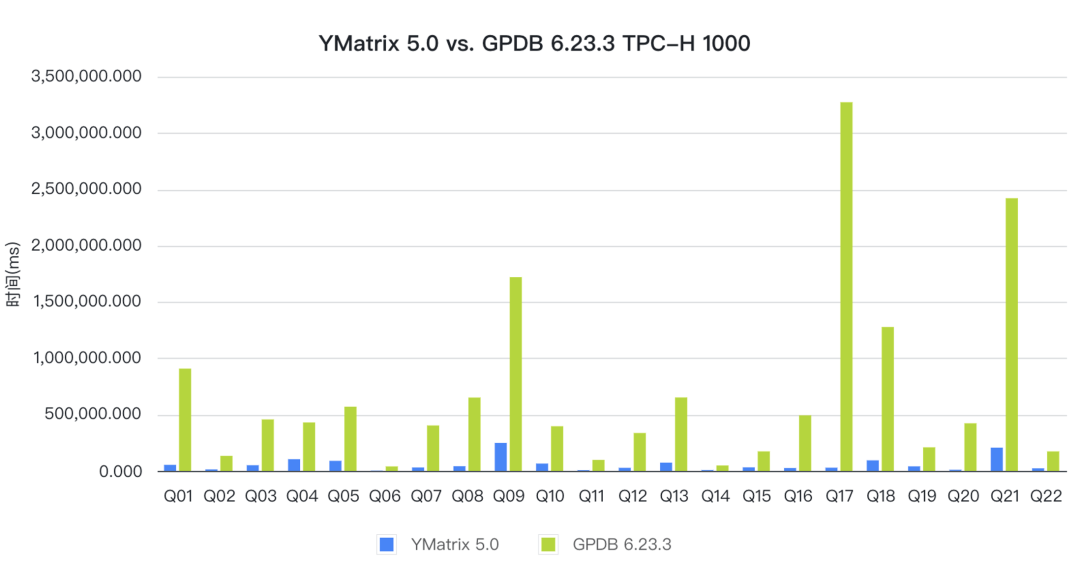
本次性能报告对比了 YMatrix 和 Greenplum (简称 GPDB) 在 TPC-H 分析型查询场景下的性能表现。测试结果显示,YMatrix 在 100 倍和 1000 倍两种数据规模下的表现远远优于 GPDB,分别提升了 13 倍和 12 倍。
TPC-H 是一个决策支持基准测试,包含一组业务导向的即席查询和并发数据修改。所选查询和数据库中的数据具有广泛的行业适用性。这个基准测试展示了决策支持系统的能力,可以检查大量数据、执行高度复杂的查询,并回答关键的业务问题,同时反映了数据库系统处理查询的多方面能力。

测试环境
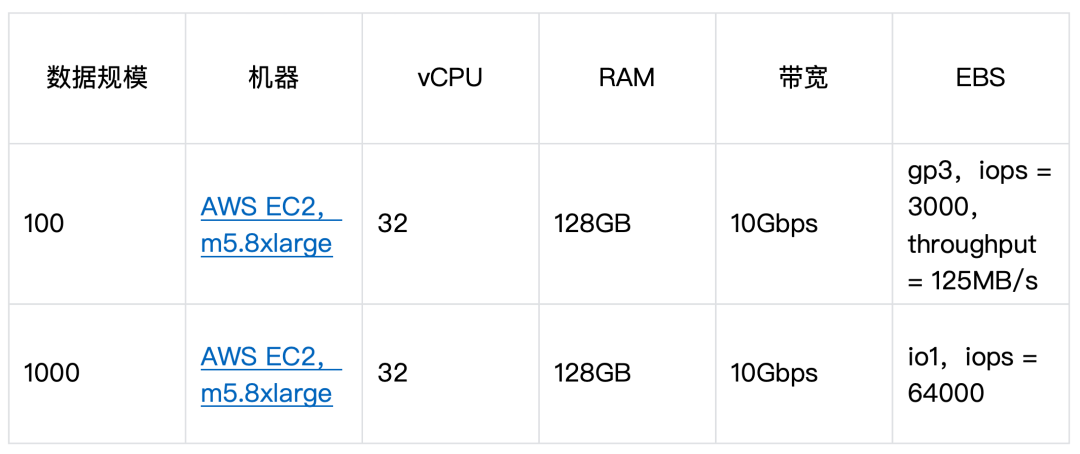
硬件环境
软件环境
操作系统内核: 3.10.0-1160.66.1.el7.x86_64 操作系统版本: CentOS Linux release 7.9.2009 YMatrix: 企业版 matrixdb5-5.0.0+enterprise_5.0.0,其中 YMatrix 集群部署参见官方文档及 YMatrix 的 TPC-H 基准测试工具 Greenplum: open-source-greenplum-db-6.23.3-rhel7-x86_64

测试方案
分别在 100 倍和 1000 倍数据规模下进行 YMatrix 和 GPDB 的测试,YMatrix 和 GPDB 都配置为 6 个 segments,所有测试结果均由 YMatrix 工程师采用同等机器配置实测得到。
100 倍和 1000 倍的数据规模测试有如下区别:
因为 100 倍规模的数据在 128GB 内存的配置下能全部缓存,所以 100 倍测试使用了 gp3 类型的磁盘,并且 YMatrix 同时测试了 lz4 和 zstd 压缩格式,zstd 的 compresslevel=1 ;开源版本 GPDB 因为不支持 quicklz 压缩格式,所以只采用的是 zstd 压缩, compresslevel=1 。 1000 倍数据规模下,使用的是性能更好的 io1 类型的磁盘,并且 YMatrix 和 GPDB 均采用了 zstd 压缩, compresslevel=1 。 本文测试中 100 倍数据规模下 statement_mem=1GB ,1000 倍数据规模下 statement_mem=2GB 。

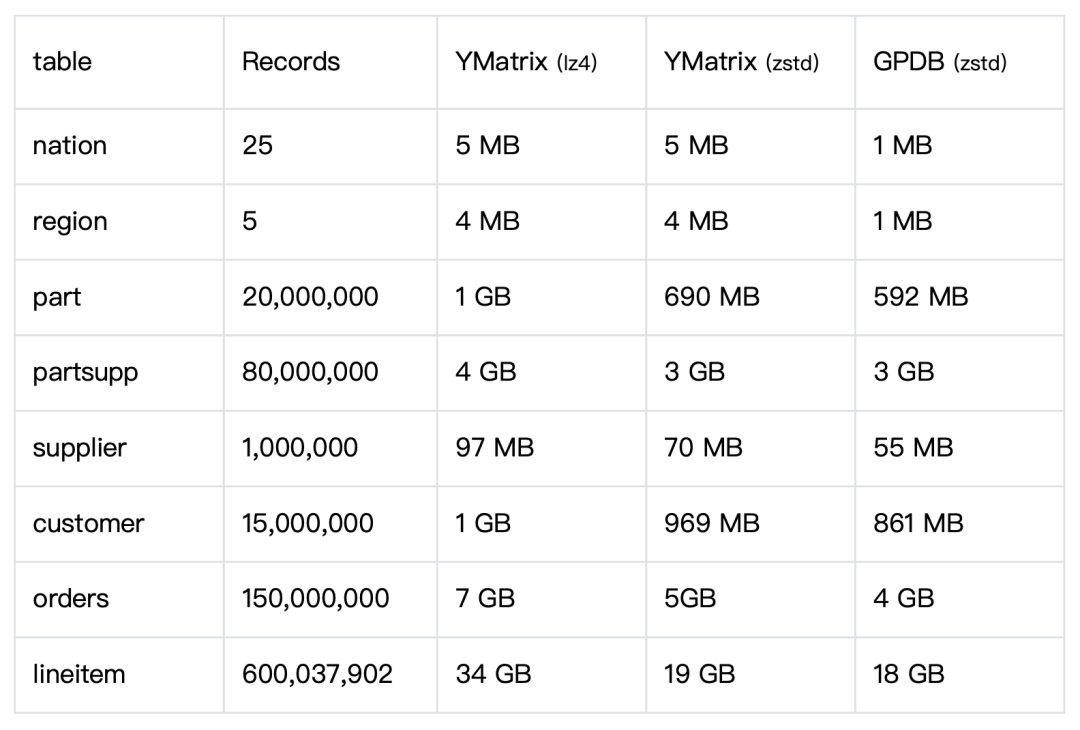
测试数据
TPC-H 100倍规模数据:


测试步骤
1. 准备测试环境:
如上文“硬件环境”一节,初始化 AWS 上的虚拟机环境。 按照 YMatrix 官网文档安装 YMatrix 测试集群。 下载 GPDB 6.23.3 版本,安装并初始化 GPDB 集群。 建议按照服务器硬件环境合理的配置数据库的 gp_vmem_protect_limit 和 statement_mem 。
git clone https://github.com/ymatrix-data/TPC-H.git
配置数据库环境变量,指定数据库端口,指定 DATABASE。
export PGPORT=5432export PGDATABASE=tpch_s100mxgate start --config mxgate.con
执行 tpch.sh 脚本,生成 tpch_variable.sh 配置文件, -d 参数可以选择数据库类型,比如 matrixdb , greenplum ; -s 参数可以指定数据规模。
./tpch.sh -d matrixdb -s 100rt --config mxgate.con
完成配置文件修改之后,一键执行 tpch.sh ,该脚本会自动生成数据、创建表、加载数据及执行 TPC-H 所有查询,并生成查询执行的时间。
./tpch.sh
注意: tpch.sh 脚本执行数据加载的时候,对 YMatrix 采用的是基于 matrixgate 工具的加载方式,对 GPDB 采用的是基于 gpfdist 工具的加载方式。
配置RUN_GEN_DATA="true" ,表示生成数据。 配置RUN_DDL="true" ,表示创建表和索引。 配置RUN_LOAD="true" ,表示加载数据。 配置RUN_SQL="true" ,表示执行 TPC-H 所有查询。 配置PREHEATING_DATA="true" ,表示需要预热轮次对数据文件进行缓存。 配置SINGLE_USER_ITERATIONS="2",如果上述配置项 PREHEATING_DATA="true",则表示 TPC-H 查询会执行 3 次, 其中有一次预热结果,排除预热结果,取后两次结果中的最小值。
`RUN_COMPILE_TPCH="false"``RUN_GEN_DATA="false"``RUN_INIT="false"``RUN_LOAD="false"``RUN_SQL="true"``RUN_SINGLE_USER_REPORT="true"`

测试结论
此次测试分别对 YMatrix 和 GPDB 进行了多组测试,采用各自最好的成绩进行性能对比。
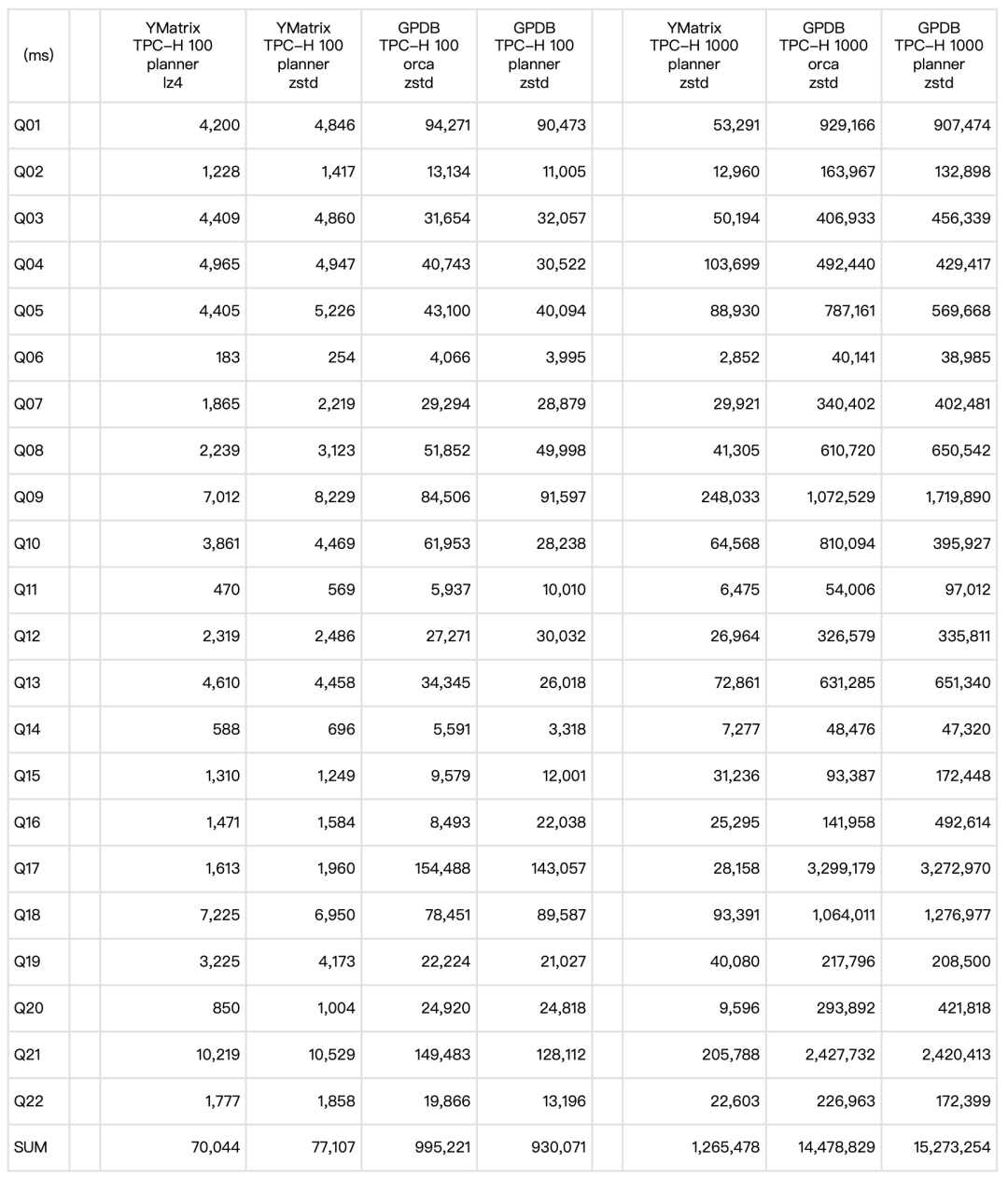
YMatrix 的 TPC-H 100 的性能数据采用的是 lz4 的压缩格式;GPDB 的 TPC-H 100 的性能数据采用的是 zstd 压缩, compresslevel=1 ,因为开源的 GPDB 不支持 quicklz 压缩格式,所以目前只能采用 zstd 压缩来进行对比;YMatrix 和 GPDB 的 TPC-H 1000 性能数据都是采用的 zstd 压缩, compresslevel=1 。
从性能对比来看,YMatrix 的性能远远好于 GPDB,TPC-H 100 和 1000 都比 GPDB 快了 10 倍以上。
附录
- 报告原文:(点击阅读原文)
https://ymatrix.cn/doc/5.0/what_is_ymatrix/tpch_performance_report
https://github.com/ymatrix-data/TPC-H
https://ymatrix.cn/doc/5.0/install/mx5_cluster/mx5_cluster
https://github.com/greenplum-db/gpdb/releases/tag/6.23.3
https://docs.vmware.com/en/VMware-Tanzu-Greenplum/6/greenplum-database/GUID-install_guide-init_gpdb.html
一条有爱的分割线
感谢你的阅读,YMatrix 期待与志同道合的你一起同行。




