




Hop介绍
Apache Hop,Hop Orchestration Platform的缩写,是一个数据编排和数据工程平台,旨在简化数据和元数据编排的各个方面。Hop可以让你专注于你试图解决的问题,而不会受到技术的阻碍。简单的任务应该是容易的,复杂的任务必须是可能的。

Hop允许数据专业人员直观地工作,使用元数据来描述应该如何处理数据。可视化设计使数据开发人员能够专注于他们想做什么,而不是需要如何完成任务。这种对手头任务的关注让Hop开发人员比编写代码时更有效率。

Hop 的设计尽可能灵活:核心是小巧但功能强大的 Hop 引擎。所有功能都是通过插件添加的:默认的 Hop 安装带有大约 400 个插件。您可以根据需要删除或添加第三方插件,使 Hop 完全符合您的需要。Hop 设计用于任何场景,从物联网到海量数据、本地、云端、裸操作系统或容器和 kubernetes。
Hop 开发人员在称为 Hop Gui 的可视化开发环境中创建工作流和管道。这些工作流和管道可以在各种引擎上执行:工作流和管道可以在本地和远程的本地 Hop 引擎上运行。管道还可以通过 Apache Beam 运行时配置在 Apache Spark、Apache Flink 和 Google Dataflow 上运行。
在工作流和管道中,可以对数据应用数百种操作:从各种源和目标平台读取和写入,还可以组合、丰富、清理和以许多其他方式操作数据。根据引擎和所选功能,您的数据可以批处理、流式处理或批处理/流式混合处理。
Hop常见用例
1.利用云、集群和大规模并行处理环境将大型数据集加载到数据库中。
2.内置支持缓慢变化维度(SCD)、变更数据捕获(CDC)和代理密钥创建的数据仓库填充。
3.在不同的数据架构之间集成,结合关系数据库、文件、NoSQL数据库,如Neo4j、MongoDB、Cassandra等。
4.不同数据库和应用程序之间的数据迁移。
5.数据分析和数据清理。
Hop概念
元数据是迄今为止所有 Hop 中最重要的概念。
Hop 与数据架构中其他组件之间的所有交互都是通过元数据完成的。元数据是Hop中一切的核心。
1.Pipelines是转换的集合,通过Hop连接。管道中的所有转换并行运行。
2.Workflows是动作的集合,由Hop连接。默认情况下,工作流中的所有操作都按顺序运行。
3.Projects是Hop代码和配置的逻辑集合。Environments包含特定于环境(例如 dev、uat、prd)的元数据。
Action

Action 是在 Workflow 中执行的一项操作。默认情况下,操作按顺序执行,并行执行作为配置选项。Action 返回 true 或 false 退出代码,可以在 Workflow 的执行中使用(或忽略)。
Hop
Hop链接Workflow中的操作或管道中的转换。在Workflows中,Hops根据之前Actions的退出状态进行操作,Pipelines中的Hops在Transforms之间传递数据。
Pipeline
Pipeline是实际的数据工作者。Pipeline中的操作读取、修改、丰富、清理和写入数据。Pipelines的编排是通过其他Pipelines和/或Workflows完成的。
Transform
Transform 是在管道中执行的工作单元。典型的转换操作是从文件、数据库中读取数据、执行查找或连接、丰富、清理数据等等。管道中的所有转换都是并行执行的。转换处理数据并在 Hops 上移动成批处理的数据,以供后续 Action 处理。
Workflow
Workflow是默认按顺序执行的一系列操作(可选择并行执行)。Workflow通常不直接对数据进行操作,而是执行编排任务。Workflow中的典型任务包括检索和归档数据、发送电子邮件、错误处理等。
Project
Hop 项目是配置、变量、元数据对象以及工作流和管道的概念性分组。项目可以从父项目继承元数据。一个项目包含一个或多个环境,其中定义了实际配置。
Environment
Hop Environments 是项目的实例,其中包含项目的实际运行时配置和其他元数据对象。示例:“Sales”项目的“dev”环境指定从主机“10.0.0.1”读取“customers”数据库连接。
HOP VS KETTLE
Hop 最初(2019 年底)开始作为 Kettle(又名 Pentaho 数据集成或 PDI)的一个分支。但是 Hop 和 Kettle/PDI 各自是独立的项目,每个项目都有自己的路线图和优先级。鉴于这些不同的路线图、架构愿景和发展轨迹,Hop 和 Kettle/PDI 是不兼容的。然而,由于 Hop 与 Kettle/PDI 有着共同的历史, Hop 社区还是提供了一种尽可能无缝地将现有 PDI/Kettle 项目导入 Hop 的方法。
Hop vs Kettle/PDI 详见:
https://hop.apache.org/tech-manual/latest/hop-vs-kettle/index.html
安装Hop
Hop 被设计为尽可能灵活和轻便,旨在与您的架构融为一体,而不是相反,这使得基本安装过程非常简单。Hop 对任何支持的操作系统的唯一要求是 Java 运行时环境。Hop 官方 Java 版本是 11。
Hop下载地址: https://hop.apache.org/download/
HOP TOOLS
01
HOP GUI
Hop Gui 是可视化 IDE,Hop 数据开发人员可以在其中创建、测试、运行和管理工作流和管道的生命周期。除了用于开发和生命周期管理的功能之外,Hop Gui 还包含用于管理项目和环境、搜索和管理元数据、管理和版本控制大量文件以及探索 Neo4j 图形中的日志记录的工具和透视图。
Apache Hop GUI 是您的本地开发环境,用于构建、运行、预览和调试工作流和管道。
注意:Hop Gui被设计为独立于平台。Hop-Web是Hop-Gui的一个版本,适用于浏览器和移动设备。

02
HOP Conf
Hop Conf 是一个命令行工具,用于管理 Hop 配置的各个方面:项目、环境、云配置等。
03
Hop Encrypt
Hop Encrypt是一种命令行工具,用于混淆或加密纯文本密码,以便在XML、密码或元数据文件中使用。请确保还复制密码加密前缀,以指示密码的模糊性质。然后,Hop将能够区分普通的纯文本密码和模糊的密码。
04
Hop Run
Hop Run 是一个命令行工具,用于运行工作流和管道,具有(列出或)指定项目、环境、属性和运行配置的选项。
05
Hop Search
Hop Search 是一个命令行工具,用于搜索特定项目或环境中可用的所有元数据。
06
Hop Server
Hop Server 是一个 Web 服务接口,用于管理和运行工作流和管道。
07
Hop Import
Hop Import 是一个命令行工具,用于将 PDI/Kettle 作业和转换导入 Apache Hop。
Hop Import 所做的不仅仅是从作业到工作流和转换到管道的代码转换:数据库连接被转换为 Apache Hop rdbms 连接,变量被解析和导入,所有东西都被捆绑到一个完整的 Apache Hop 项目中。
08
Hop Translator
Hop Translator 是一个图形用户界面工具,允许非技术用户将 Hop 翻译成他们的母语。
09
Hop Metadata
Hop Metadata 是共享元数据(如关系数据库连接、运行配置、服务器、git 存储库等)的中央存储库。元数据以 json 格式保存,默认情况下存储在项目的基本文件夹中。
启动 APACHE HOP GUI
在 Linux 或 Mac 上:./hop-gui.sh
在 Windows 上:hop-gui.bat
同时HOP也支持docker容器。
docker 容器运行一个名为Alpine的最小 Linux 系统,然后使用 OpenJDK 版本 11 执行 Apache Hop。
用于在容器中执行的 Linux 用户是hop,组也是hop。
相关详情参见: https://hop.apache.org/tech-manual/latest/docker-container.html
HOP还支持自行构建,需使用JDK11以及Maven 3.6.3及以上版本进行构建。
可以构建Client,也可以构建成War包。Client通过GUI启用,War通过Tomcat使用web启用。
Pipelines(管道)
Pipelines 与 Workflows 是 Hop的主要模块。Pipelines执行繁重的数据提取:在Pipelines中,从一个或多个源读取数据,执行一系列操作(连接、查找、筛选等),最后将处理后的数据写入一个或多个目标平台。
Pipelines是一个由跃点连接的转换网络。就像Workflows中的操作一样,每个转换都是一小部分功能。许多转换的组合允许 Hop 开发人员构建强大的数据处理,并结合工作流、编排解决方案。
管道由读取、处理或写入数据的一系列转换组成。转换通过跃点连接。跃点有方向但不能创建循环,这有效地使管道 DAG(有向无环图)。管道的核心原则是:
1.管道是网络。管道中的每个转换都是网络的一部分。
2.转换是管道中的每个基本操作。每个转换对数据执行一个操作:从源读取、对管道中的数据进行操作或写入目标。管道并行运行其所有转换。所有转换都已启动并同时处理数据。
3.数据通过跃点流过管道中的各种转换。与Workflows跃点相反,Pipelines跃点通常没有退出状态。
相关详情参见: https://hop.apache.org/manual/latest/pipeline/pipelines.html
Workflows(工作流)
Workflows是 Apache Hop 的核心模块之一。在管道进行繁重的数据提取的地方,工作流负责编排工作:准备环境、获取远程文件、执行错误处理以及执行子工作流和管道。
工作流运行方式:
1.工作流执行编排任务。工作流中的操作通常不直接对数据进行操作(即使可以更改数据,例如通过SQL)。
2.工作流有且只有一个强制性起点(Start操作),但可以有多个结束操作。
3.默认情况下,工作流按顺序工作。工作流中的每个动作在工作流序列中都有一个位置,需要等待前面的动作完成后才能开始。
4.工作流操作不会通过跃点传递数据。每个工作流操作都有一个success或failure退出状态。此退出状态用于选择通过工作流的路由。
5.工作流中操作之间的跳转具有状态:根据前一个操作的退出状态,工作流跳转可以遵循成功(绿色)、失败(橙色)或无条件(黑色)跳转。无条件跳转忽略先前操作的退出状态,并且无论先前操作失败还是成功都遵循。
相关详情参见:
https://hop.apache.org/manual/latest/workflow/workflows.html
Metadata(元数据)
元数据是 Hop 的基石之一,可以定义为工作流、管道和任何其他类型的元数据对象。
Hop Gui 有一个元数据透视图来管理所有类型的元数据:运行配置、数据库(关系和 NoSQL)连接、日志记录和管道探测等等。
元数据通常作为 json 文件存储在项目的元数据文件夹中,作为一组 json 文件,在每个元数据类型的子文件夹中。该规则的唯一例外是工作流和管道,它们被定义为 XML(目前,由于历史原因)。由于工作流和管道是 Hop 的全部内容,因此它们通常存储在您的项目文件夹中,而不是项目的元数据文件夹中。
默认情况下,Hop 包含以下元数据类型:
1.Asynchronous Web Service:通过 Web 服务异步执行和查询工作流。
2.Beam File Definition:描述 Beam 管道中的文件布局
3.Cassandra Connection: 描述与 Cassandra 集群的连接
4.Data Set: 定义一个数据集,一个静态的预定义行集合
5.Hop Server: Hop服务器
6.MongoDB Connection: MongoDB 连接
7.Neo4j Connection: 与 Neo4j 服务器的共享连接
8.Neo4j Graph Model: Neo4j 图的节点、关系、索引等的描述
9.Partition Schema: 描述分区模式
10.Pipeline Log: 允许使用另一个管道记录管道的活动
11.Pipeline Probe: 允许将管道的输出行流式传输到另一个管道
12.Pipeline Run Configuration: 描述如何以及使用哪个引擎执行管道
13.Pipeline Unit Test: 描述了管道测试,其中替代数据集作为来自特定转换的输入和针对黄金数据的测试输出
14.Relational Database Connection: 描述连接到关系数据库所需的所有元数据
15.Splunk Connection: Splunk 连接
16.Web Service: 允许运行管道为 Hop 服务器上的 servlet 生成输出
17.Workflow Log: 允许使用管道记录工作流的活动
18.Workflow Run Configuration: 描述如何运行工作流
数据库连接

Metadata元数据-Relational Database Connections数据库连接
1
连接保存在一个中心位置,然后可以由所有管道和工作流使用。如果已在Hop项目中设置,则数据库信息将位于${project_HOME}/metadata/rdbms文件夹中。创建的每个连接都会在此文件夹中生成一个.json文件,该文件具有连接的名称,包含连接信息。
2
如果许可证允许,则在分发中包含一个 jdbc 驱动程序,在每个驱动程序特定的文件夹中,一般路径: Installation directory/plugins/databases/Database type/lib。
3
HOP_SHARED_JDBC_FOLDER变量可以在启动 Hop 之前设置为指向所需 jdbc 驱动程序的集中位置。这可以设置为 OS 环境变量或作为导出变量添加到 Hop 启动脚本。将此变量设置为与 Hop 安装文件夹分开的文件夹,无论使用哪个 Hop 版本,都可以保留驱动程序版本。
4
为了避免冲突,请确保对于每类驱动程序,在任何文件夹中都只有一个,即HOP_SHARED_JDBC_FOLDER、HOP/plugins/databases/Database-type/lib或HOP/lib文件夹。
配置源数据库相关信息

定时同步单表数据
定时同步Workflows
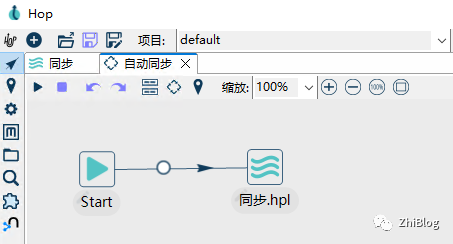
数据同步Pipelines
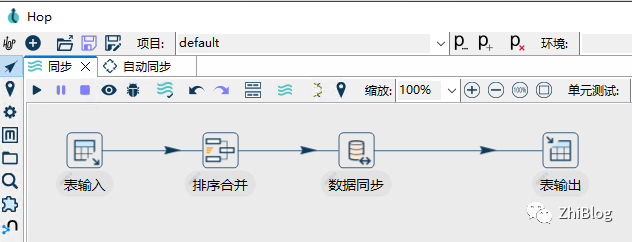
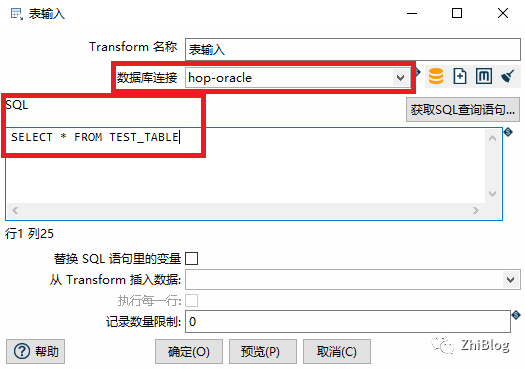
表输入
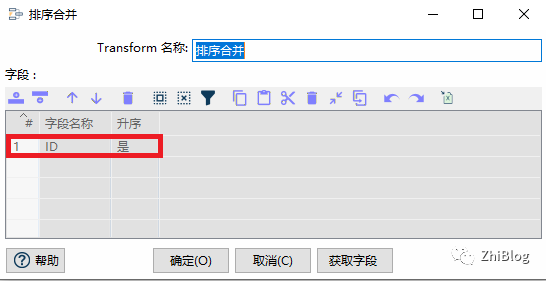
排序合并
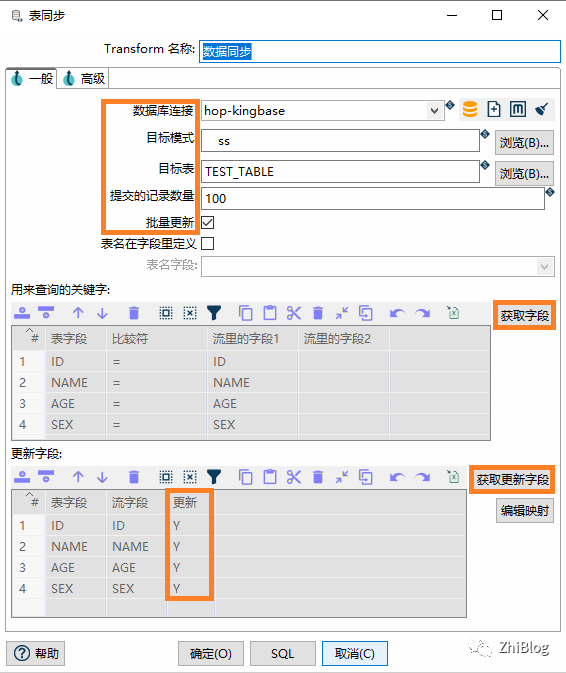
表同步
表输出

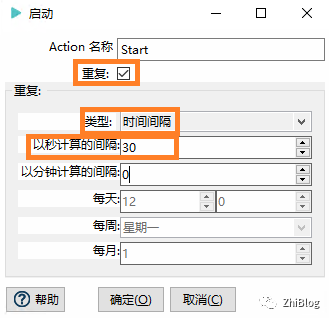
工作流-Start-每30秒同步一次
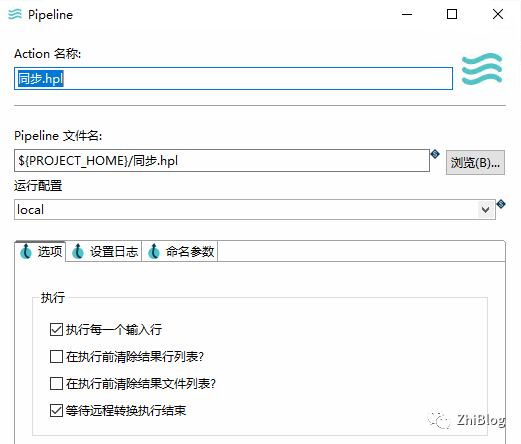
工作流-指定运行的Pipeline
点击紫色箭头启动工作流并查看目标数据库
ssss=> select * from TEST_TABLE;ID | NAME | AGE | SEX----+--------+-----+-----1 | 张晓明 | 18 | 女2 | 秦杰宏 | 25 | 男3 | 杜秀英 | 16 | 女(3 行记录)
源数据库INSERT
INSERT INTO "TEST"."TEST_TABLE" ("ID", "NAME", "AGE", "SEX") VALUES ('4', '姜致远', '20', '男');INSERT INTO "TEST"."TEST_TABLE" ("ID", "NAME", "AGE", "SEX") VALUES ('5', '陶子异', '21', '男');
目标库查看
ssss=> select * from TEST_TABLE;ID | NAME | AGE | SEX----+--------+-----+-----4 | 姜致远 | 20 | 男5 | 陶子异 | 21 | 男1 | 张晓明 | 18 | 女2 | 秦杰宏 | 25 | 男3 | 杜秀英 | 16 | 女(5 行记录)
源库UPDATE
UPDATE "TEST"."TEST_TABLE" SET "NAME" = '陈岚', "AGE" = '27', "SEX" = '女' WHERE "ID" = '1';
目标库查看
ssss=> select * from TEST_TABLE;ID | NAME | AGE | SEX----+--------+-----+-----4 | 姜致远 | 20 | 男5 | 陶子异 | 21 | 男1 | 陈岚 | 27 | 女2 | 秦杰宏 | 25 | 男3 | 杜秀英 | 16 | 女(5 行记录)
源库DELETE
DELETE "TEST"."TEST_TABLE" WHERE "SEX" = '男';
目标库查看
ssss=> select * from TEST_TABLE;ID | NAME | AGE | SEX----+--------+-----+-----1 | 陈岚 | 27 | 女3 | 杜秀英 | 16 | 女(2 行记录)
多表定时同步数据
工作流-数据迁移-主任务
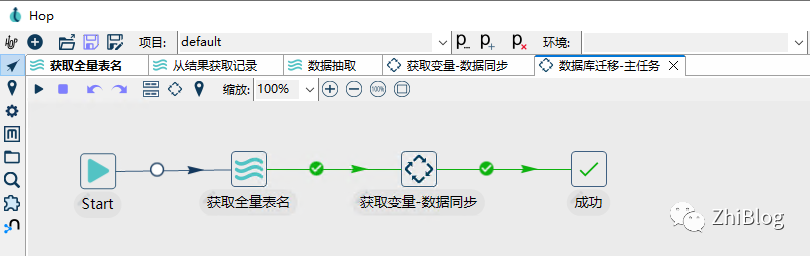
工作流-获取变量并进行数据抽取
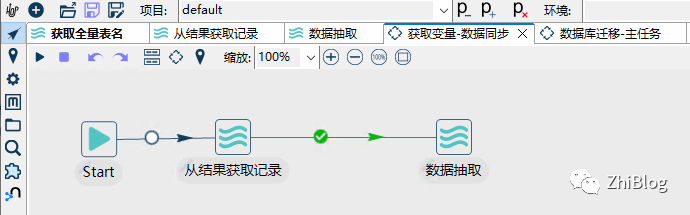
管道-获取全量变量

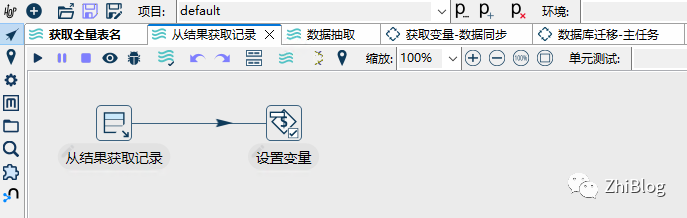
管道-从结果中获取记录
管道-数据抽取

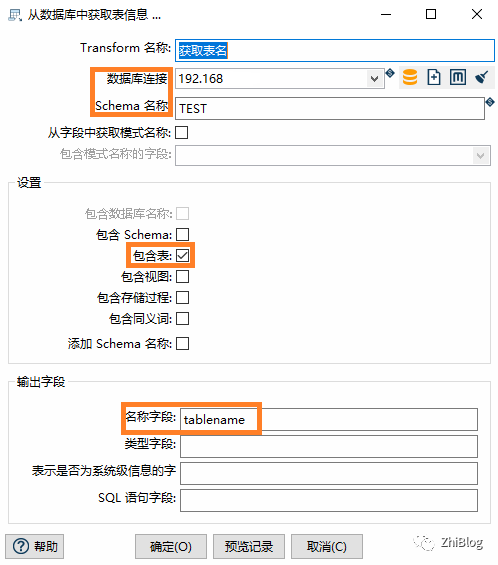
获取表名-指定输出的名称字段(源数据库)
字段选择-获取选择的字段

复制记录到结果

从结果中获取记录-指定要获取的字段名称

设置变量-设置需要获取的变量

表输入-配置SQL(源数据库)

表输出-配置目标表为变量获取

工作流-获取变量并进行数据抽取-Start(不做任何配置)
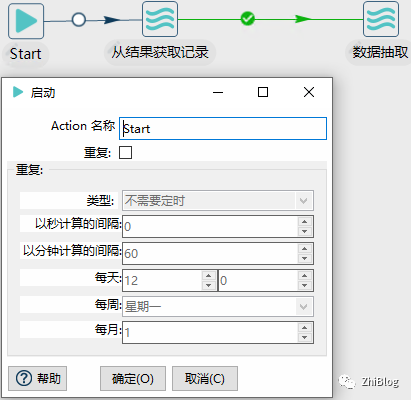
工作流-获取变量并进行数据抽取-指定Pipeline
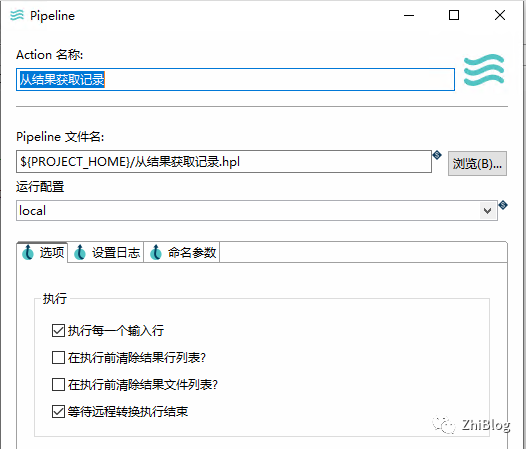
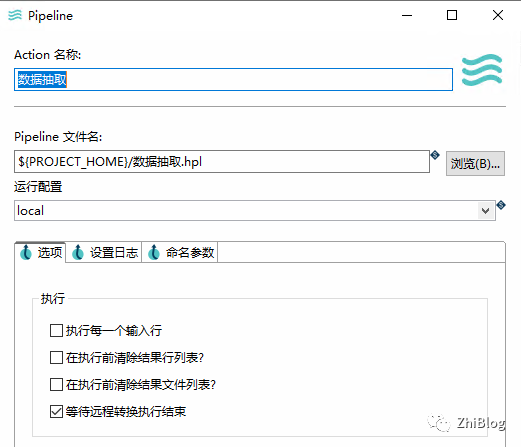
工作流-获取变量并进行数据抽取-指定Pipeline
工作流-数据迁移-主任务-Start(配置定时任务)
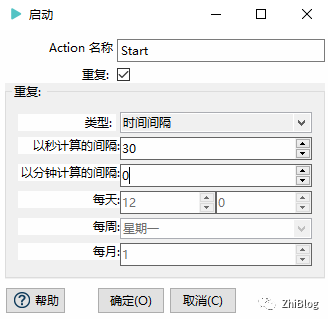
工作流-数据迁移-主任务-指定pipeline
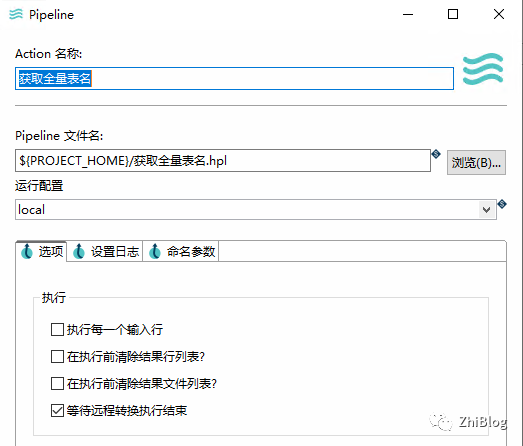
工作流-数据迁移-主任务-指定Workflow
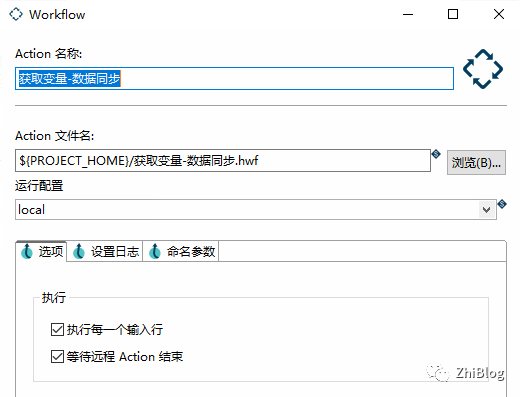
工作流-数据迁移-主任务-配置动作

运行Workflow
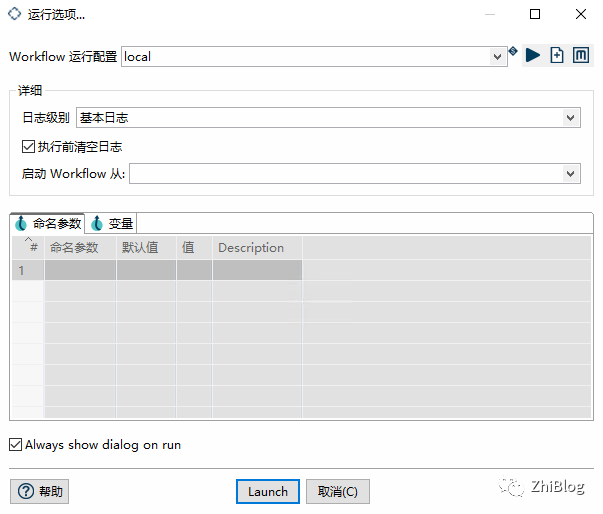
查看同步情况





注意:Hop跟Kettle一样,是不能迁移以及同步表结构、索引、约束等的,现只能同步表数据
