





本篇文章由得物数据库团队基于业务实践总结输出
1. 背景
2. 基本概念
2.1 物理内存地址
也即实际的物理内存地址空间。
2.2 虚拟地址空间
虚拟地址空间(Virtual Address Space)是每一个程序被加载运行起来后,操作系统为进程分配的虚拟内存,它为每个进程提供了一个假象,即每个进程都在独占地使用主存。
每个进程所能访问的最大的虚拟地址空间由计算机的硬件平台决定,具体地说是由CPU的位数决定的。比如32位的CPU就是我们常说的4GB虚拟内存空间。
程序访问内存地址使用虚拟地址空间,然后由操作系统将这个虚拟地址映射到适当的物理内存地址上。这样,只要操作系统处理好虚拟地址到物理内存地址的映射,就可以保证不同的程序最终访问的内存地址位于不同的区域,彼此没有重叠,就可以达到内存地址空间隔离的效果。
当进程创建时,每个进程都会有一个自己的4GB虚拟地址空间。要注意的是这个4GB的地址空间是“虚拟”的,并不是真实存在的,而且每个进程只能访问自己虚拟地址空间中的数据,无法访问别的进程中的数据,通过这种方法实现了进程间的地址隔离。
对于Linux,4GB的虚拟地址空间包含用户态虚拟内存空间和内核态虚拟内存空间两部分,默认分配状态如下:
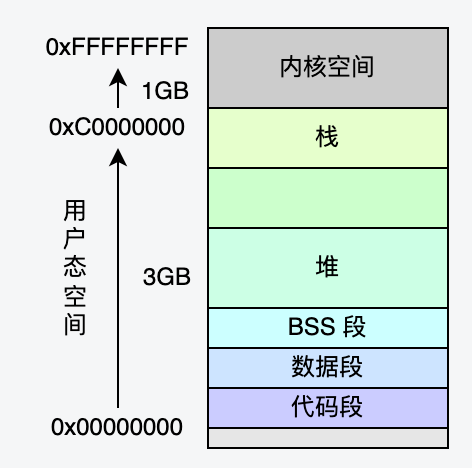
2.3 内存页表
CPU访问数据的时候,CPU发出的地址是虚拟地址,CPU中内存管理单元(MMU)通过查询页表,把虚拟地址转换为物理地址,再去访问物理内存条。
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小,这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在Linux下,每一页的大小为4KB。
在32位的环境下,虚拟地址空间共有4GB,假设一个页的大小是4KB(2^12),那么就需要大约100万(2^20)个页,每个「页表项」需要4个字节大小来存储,那么整个4GB空间的映射就需要有4MB的内存来存储页表。
这4MB大小的页表,看起来也不是很大。但是每个进程都是有自己的虚拟地址空间,也就说都有自己的页表。每个机器上同时运行多个进程,页表将占用大量内存。
2.3.2 多级页表
要解决上面提到的存储进程页表项占用大量内存空间的问题,就需要采用一种叫作多级页表(Multi-Level Page Table)的解决方案。
我们把这个100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为1024个页表(二级页表),每个二级页表中包含1024个「页表项」,形成二级分页。这样,一级页表就可以覆盖整个4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。也就是,内存中只需要保存一级页表以及使用到的二级页表,大量的未被使用的二级页表则不需要分配内存并加载在内存中,因此,达到节省页表占用内存空间的目的。
对于64位的系统,使用四级分页目录,分别是:
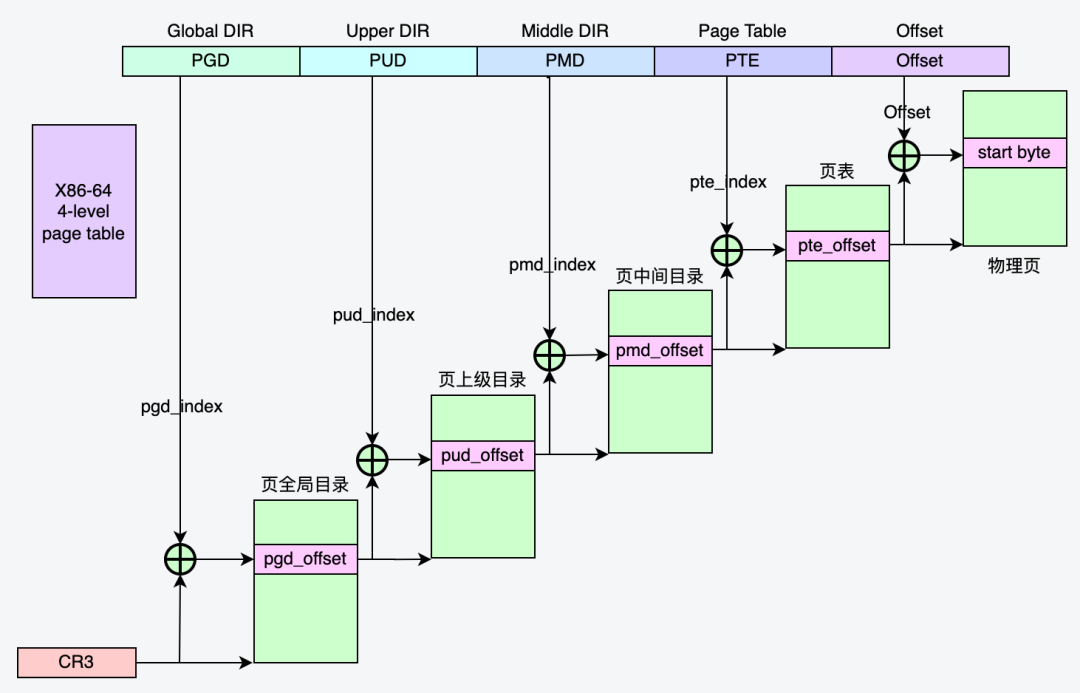
2.4 虚拟内存区域(VMA)
3. Fork原理
在默认fork的调用过程中,父进程需要将许多进程元数据(例如文件描述符、信号量、页表等)复制到子进程,而页表的复制是其中最耗时的部分(占据fork调用耗时的97%以上)。
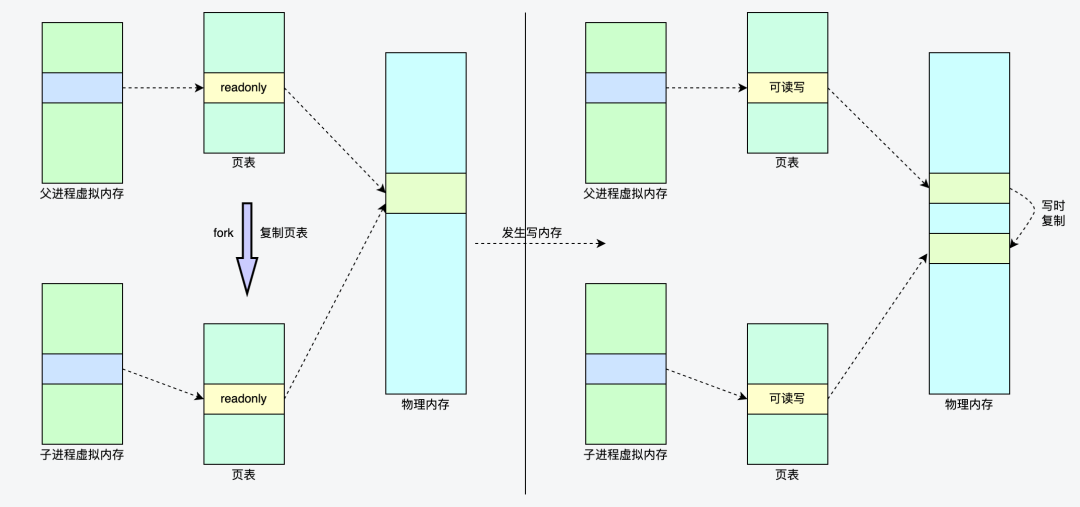
Linux的fork()使用写时拷贝 (copy-on-write) 页的方式实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。在创建子进程的过程中,操作系统会把父进程的「页表」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,此时,操作系统并不复制整个进程的物理内存,而是让父子进程共享同一个物理内存。同时,操作系统内核会把共享的所有的内存页的权限都设为read-only。
那什么时候会发生物理内存的复制呢?
当父进程或者子进程在向共享内存发起写操作时,内存管理单元MMU检测到内存页是read-only的,于是触发缺页中断异常(page-fault),处理器会从中断描述符表(IDT)中获取到对应的处理程序。在中断程序中,内核就会把触发异常的物理内存页复制一份,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写,于是父子进程各自持有独立的一份,之后进程才会对内存进行写操作,这个过程也被称为写时复制(Copy On Write)。
4. Fork的痛点
在原生fork下,在父进程调用fork()创建子进程的过程中,虽然使用了写时复制页表的方式进行优化,但由于要复制父进程的页表,还是会造成父进程出现短时间阻塞,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长。
我们在测试中很容易观察到fork产生的阻塞现象,以及fork造成的Redis访问抖动现象。
4.1 测试环境
Redis版本:优化前Redis-server
机器操作系统:无Async-fork特性的系统
127.0.0.1:6380> info memory# Memoryused_memory:23220597688used_memory_human:21.63G
4.2 阻塞现象复现
在使用Redis-benchmark压测的过程中,手动执行bgsave命令,观察fork耗时和压测指标TP100。
使用 info stats 返回上次fork耗时:latest_fork_usec:183632,可以看到fork耗时183毫秒。
在压测过程中分别不执行bgsave和执行bgsave,结果如下:
# 压测过程中未执行 bgsave[root@xxx bin]# Redis-benchmark -d 256 -t set -n 1000000 -a xxxxxx -p 6380====== SET ======1000000 requests completed in 8.15 seconds50 parallel clients256 bytes payloadkeep alive: 199.90% <= 1 milliseconds100.00% <= 1 milliseconds122669.27 requests per second# 压测过程中执行 bgsave[root@xxx bin]# Redis-benchmark -d 256 -t set -n 1000000 -a xxxxxx -p 6380====== SET ======1000000 requests completed in 13.97 seconds50 parallel clients256 bytes payloadkeep alive: 186.41% <= 1 milliseconds86.42% <= 2 milliseconds99.95% <= 3 milliseconds99.99% <= 4 milliseconds99.99% <= 10 milliseconds99.99% <= 11 milliseconds99.99% <= 12 milliseconds100.00% <= 187 milliseconds100.00% <= 187 milliseconds71561.47 requests per second
4.3 Strace跟踪fork过程耗时
$ strace -p 32088 -T -tt -o strace00.out14:01:33.623495 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fbe5242fa50) = 37513 <0.183533>14:01:33.807142 open("/data1/6380/6380.log", O_WRONLY|O_CREAT|O_APPEND, 0666) = 60 <0.000018>14:01:33.807644 lseek(60, 0, SEEK_END) = 8512 <0.000017>14:01:33.807690 stat("/etc/localtime", {st_mode=S_IFREG|0644, st_size=528, ...}) = 0 <0.000010>14:01:33.807732 fstat(60, {st_mode=S_IFREG|0644, st_size=8512, ...}) = 0 <0.000007>14:01:33.807756 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fbe52437000 <0.000009>14:01:33.807787 write(60, "35994:M 21 Mar 14:01:33.807 * Ba"..., 69) = 69 <0.000015>14:01:33.807819 close(60) = 0 <0.000008>14:01:33.807845 munmap(0x7fbe52437000, 4096) = 0 <0.000013>
由于Linux中通过clone()系统调用实现fork();我们可以看到追踪到clone系统调用,并且耗时183毫秒,与 info stats 统计的fork耗时一致。
5. Async-fork
鉴于以上linux原生fork系统调用的痛点,对于像Redis这样的高性能内存数据库,将会增加fork期间的用户访问延迟,论文中设计了一个新的fork(称为Async-fork)来解决上述问题。
Async-fork设计的核心思想是将fork调用过程中最耗时的页表拷贝工作从父进程移动到子进程,缩短父进程调用fork时陷入内核态的时间,父进程因而可以快速返回用户态处理用户查询,子进程则在此期间完成页表拷贝。与Linux中的默认原生fork相比,Async-fork显著减少了Redis快照期间到达请求的尾延迟。
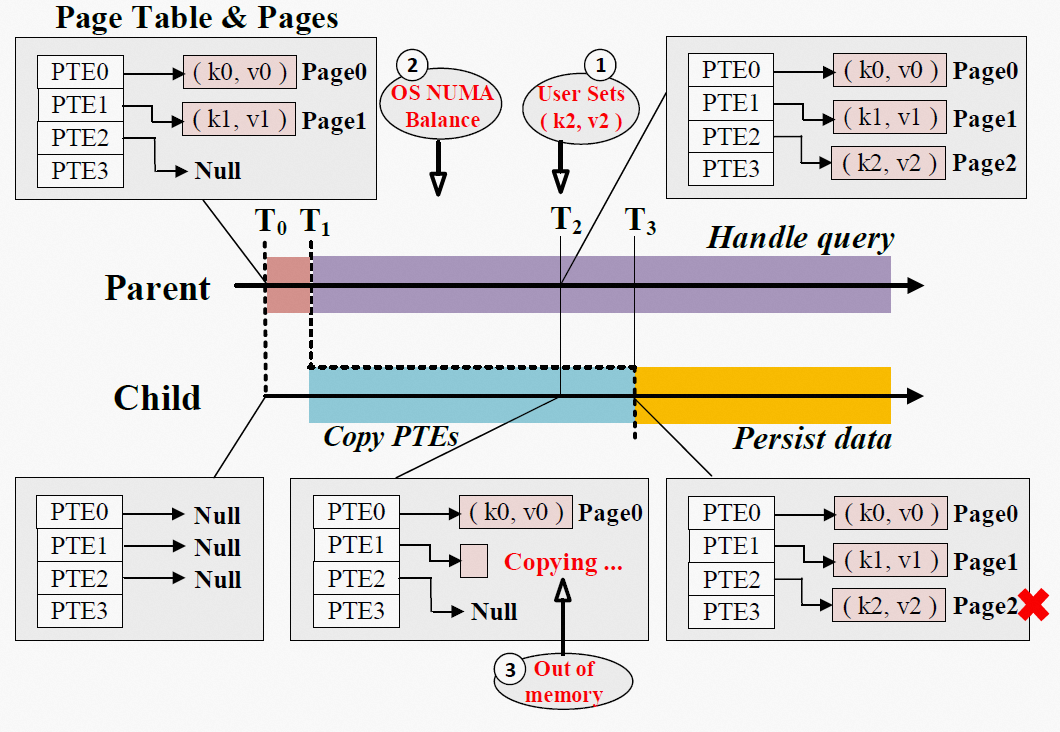
5.1 Async-fork 的挑战
5.2 Async-fork详解
在默认fork中,父进程遍历每个VMA,将每个VMA复制到子进程,并自上而下地复制该VMA对应的页表项到子进程,对于64位的系统,使用四级分页目录,每个VMA包括PGD、PUD、PMD、PTE,都将由父进程逐级复制完成。在Async-fork中,父进程同样遍历每个VMA,但只负责将PGD、PUD这两级页表项复制到子进程。
随后,父进程将子进程放置到某个CPU上使子进程开始运行,父进程返回到用户态,继续响应用户请求。由子进程负责每个VMA剩下的PMD和PTE两级页表的复制工作。
如果在父进程返回用户态后,子进程复制内存页表期间,父进程需要修改还未完成复制的页表项,怎样避免上述提到的破坏快照一致性问题呢?
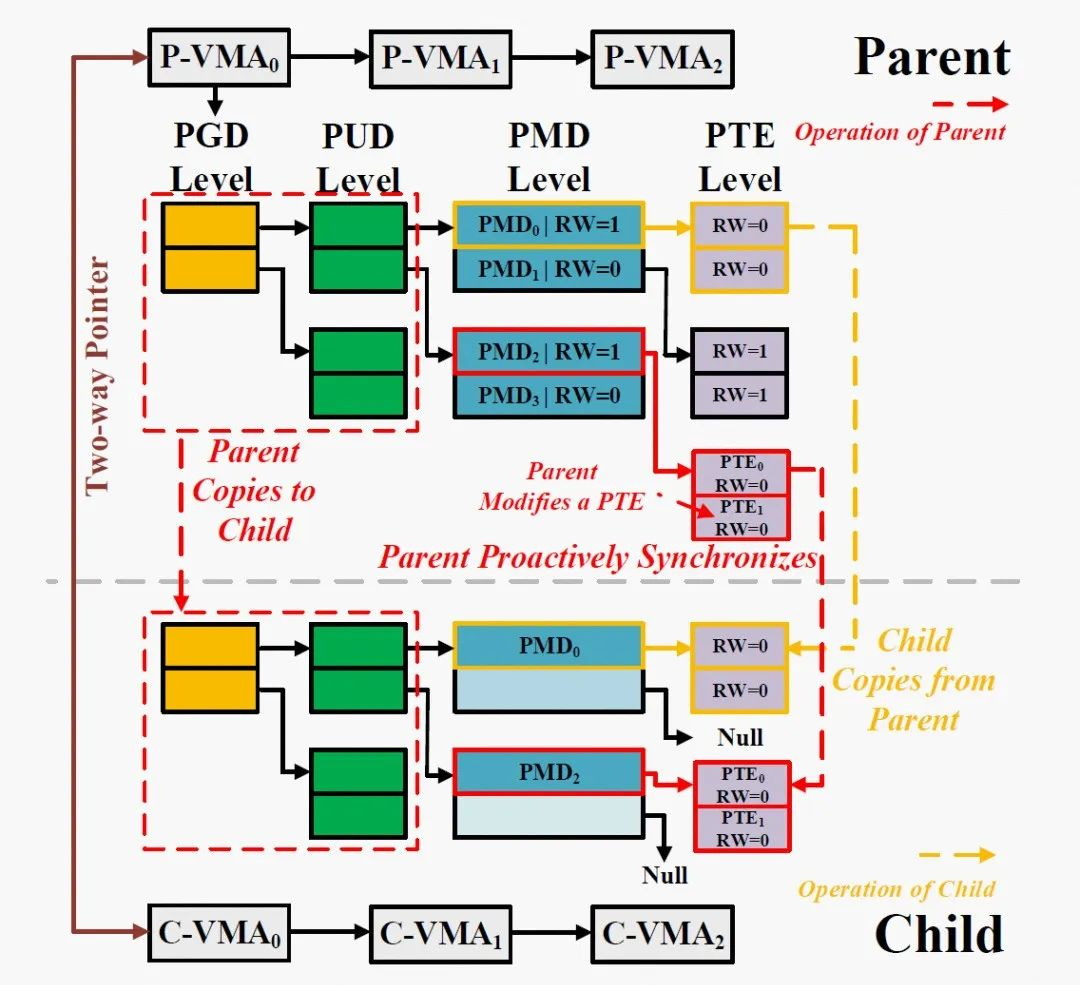
图片来源于:参考资料[1] 第7页
5.2.1 主动同步机制
父进程返回用户态后,父进程的PTE可能被修改。如果在子进程复制内存页表期间,父进程检测到了PTE修改,则会触发主动同步机制,也就是父进程也加入页表复制工作,来主动完成被修改的相关页表复制,该机制用来确保PTE在修改前被复制到子进程。
当一个PTE将被修改时,父进程不仅复制这一个PTE,还同时将位于同一个页表上的所有PTE(一共512个PTE),连同它的父级PMD项复制到子进程。
父进程中的PTE发生修改时,如果子进程已经复制过了这个PTE,父进程就不需要复制了,否则会发生重复复制。怎么区分PTE是否已经复制过?
Async-fork使用PMD项上的RW位来标记是否被复制。具体而言,当父进程第一次返回用户态时,它所有PMD项被设置为写保护(RW=0),代表这个PMD项以及它指向的512个PTE还没有被复制到子进程。当子进程复制一个PMD项时,通过检查这个PMD是否为写保护,即可判断该PMD是否已经被复制到子进程。如果还没有被复制,子进程将复制这个PMD,以及它指向的512个PTE。
在完成PMD及其指向的512个PTE复制后,子进程将父进程中的该PMD设置为可写(RW=1),代表这个PMD项以及它指向的512个PTE已经被复制到子进程。当父进程触发主动同步时,也通过检查PMD项是否为写保护判断是否被复制,并在完成复制后将PMD项设置为可写。同时,在复制PMD项和PTE时,父进程和子进程都锁定PTE表,因此它们不会出现同时复制同一PMD项指向的PTE。
在操作系统中,PTE的修改分为两类:
● PMD级的修改。PMD级的修改仅涉及一个PMD。
5.2.2 错误处理
Async-fork在复制页表时涉及到内存分配,难免会发生错误。例如,由于内存不足,进程可能无法申请到新的PTE表。当错误发生时,应该将父进程恢复到它调用Async-fork之前的状态。
6. Redis优化实践
6.1 Async-fork 阻塞现象
127.0.0.1:6679> info memory# Memoryused_memory:58385641120used_memory_human:54.38G
# 压测过程中执行 bgsave[root@xxx ~]# usr/bin/Redis-benchmark -d 256 -t set -n 1000000 -a xxxxxx -p 6679====== SET ======1000000 requests completed in 7.88 seconds50 parallel clients256 bytes payloadkeep alive: 1100.00% <= 411 milliseconds100.00% <= 412 milliseconds100.00% <= 412 milliseconds126871.35 requests per second
使用 strace 命令进行分析,结果如下:
$ strace -p 32088 -T -tt -o strace00.out14:18:12.933441 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f461c0daa50) = 13772 <0.000380>14:18:12.933884 open("/data1/6679/6679.log", O_WRONLY|O_CREAT|O_APPEND, 0666) = 60 <0.000019>14:18:12.933948 lseek(60, 0, SEEK_END) = 11484 <0.000013>14:18:12.933983 stat("/etc/localtime", {st_mode=S_IFREG|0644, st_size=556, ...}) = 0 <0.000016>14:18:12.934032 fstat(60, {st_mode=S_IFREG|0644, st_size=11484, ...}) = 0 <0.000014>14:18:12.934062 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f461c0e4000 <0.358768>14:18:13.292883 write(60, "32088:M 21 Mar 14:18:12.933 * Ba"..., 69) = 69 <0.000032>14:18:13.292951 close(60) = 0 <0.000014>14:18:13.292980 munmap(0x7f461c0e4000, 4096) = 0 <0.000019>
$ strace -p 11559 -T -tt -e trace=memory -o trace00.out14:18:12.934062 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f461c0e4000 <0.358768>14:18:13.292980 munmap(0x7f461c0e4000, 4096) = 0 <0.000019>
● 定位问题
$ perf trace -p 11559 -o trace01.out --max-stack 15 -T616821913.647 (358.740 ms): Redis-server_4/32088 mmap(len: 4096, prot: READ|WRITE, flags: PRIVATE|ANONYMOUS ) = 0x7f461c0e4000__mmap64 (/usr/lib64/libc-2.17.so)__GI__IO_file_doallocate (inlined)__GI__IO_doallocbuf (inlined)__GI__IO_file_overflow (inlined)_IO_new_file_xsputn (inlined)_IO_vfprintf_internal (inlined)__GI_fprintf (inlined)serverLogRaw (/usr/local/Redis/Redis-server)serverLog (/usr/local/Redis/Redis-server)rdbSaveBackground (/usr/local/Redis/Redis-server)bgsaveCommand (/usr/local/Redis/Redis-server)call (/usr/local/Redis/Redis-server)processCommand (/usr/local/Redis/Redis-server)processInputBuffer (/usr/local/Redis/Redis-server)aeProcessEvents (/usr/local/Redis/Redis-server)616822272.562 ( 0.010 ms): Redis-server_4/32088 munmap(addr: 0x7f461c0e4000, len: 4096 ) = 0__munmap (inlined)__GI__IO_setb (inlined)_IO_new_file_close_it (inlined)_IO_new_fclose (inlined)serverLogRaw (/usr/local/Redis/Redis-server)serverLog (/usr/local/Redis/Redis-server)rdbSaveBackground (/usr/local/Redis/Redis-server)bgsaveCommand (/usr/local/Redis/Redis-server)call (/usr/local/Redis/Redis-server)processCommand (/usr/local/Redis/Redis-server)processInputBuffer (/usr/local/Redis/Redis-server)aeProcessEvents (/usr/local/Redis/Redis-server)aeMain (/usr/local/Redis/Redis-server)main (/usr/local/Redis/Redis-server)
6.2 Async-fork 适配优化
● 测试环境
127.0.0.1:6680> info memory# Memoryused_memory:58385641144used_memory_human:54.38G
● 现象
在压测过程中执行bgsave,fork耗时和TP100均正常。
使用 info stats 返回上次fork耗时:latest_fork_usec:414
TP100结果如下:
# 压测过程中执行 bgsave[root@xxx Redis]# usr/bin/Redis-benchmark -d 256 -t set -n 1000000 -a dRedis123456 -p 6680====== SET ======1000000 requests completed in 7.50 seconds50 parallel clients256 bytes payloadkeep alive: 199.99% <= 1 milliseconds99.99% <= 2 milliseconds100.00% <= 2 milliseconds133386.69 requests per second
● 跟踪验证
strace跟踪父进程只看到clone,并且耗时只有378微秒,
# strace -p 14697 -T -tt -o strace04.out14:42:00.723224 clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7fa5340d0a50) = 15470 <0.000378>
# perf trace -p 14697 -o trace04.out --max-stack 15 -T618249694.830 ( 0.423 ms): Redis-server/14697 ... [continued]: clone()) = 15470 (Redis-server)__GI___fork (inlined)rdbSaveBackground (/usr/local/Redis/Redis-server)bgsaveCommand (/usr/local/Redis/Redis-server)call (/usr/local/Redis/Redis-server)processCommand (/usr/local/Redis/Redis-server)processInputBuffer (/usr/local/Redis/Redis-server)aeProcessEvents (/usr/local/Redis/Redis-server)aeMain (/usr/local/Redis/Redis-server)main (/usr/local/Redis/Redis-server)
由于我们的优化是将触发mmap的相关日志修改到子进程中,使用Perf trace跟踪fork产生的子进程,命令为:
strace -p 14697 -T -tt -f -ff -o strace05.out
通过Redis日志文件找到子进程pid为15931;打开对应生成的保存子进程strace信息的文件strace05.out.15931(父进程strace信息保存在文件 strace05.out.14697)
# 以下为子进程 strace 信息14:47:40.878387 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fa5340da000 <0.000008>14:47:40.878415 write(6, "15931:C 21 Mar 14:47:40.878 * Ba"..., 69) = 69 <0.000015>14:47:40.878447 close(6) = 0 <0.000006>14:47:40.878467 munmap(0x7fa5340da000, 4096) = 0 <0.000010>14:47:40.878494 open("temp-15931.rdb", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 6 <0.000020>14:47:40.878563 fstat(6, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0 <0.000006>14:47:40.878584 mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7fa5340da000 <0.000006>
在子进程中看到了mmap调用,子进程中调用不会影响父进程对业务访问的响应。
7. 性能测试
修改Redis代码,针对Async-fork适配优化后,我们针对fork与Async-fork进行了性能对比测试;测试包含不同数据量下fork()命令耗时与fork()操作对压测过程中TP100的影响。
7.1 fork()命令耗时
fork()命令耗时,即针对Redis执行 bgsave 命令后,通过Redis提供的 info stats 命令观察到的 latest_fork_usec 用时。
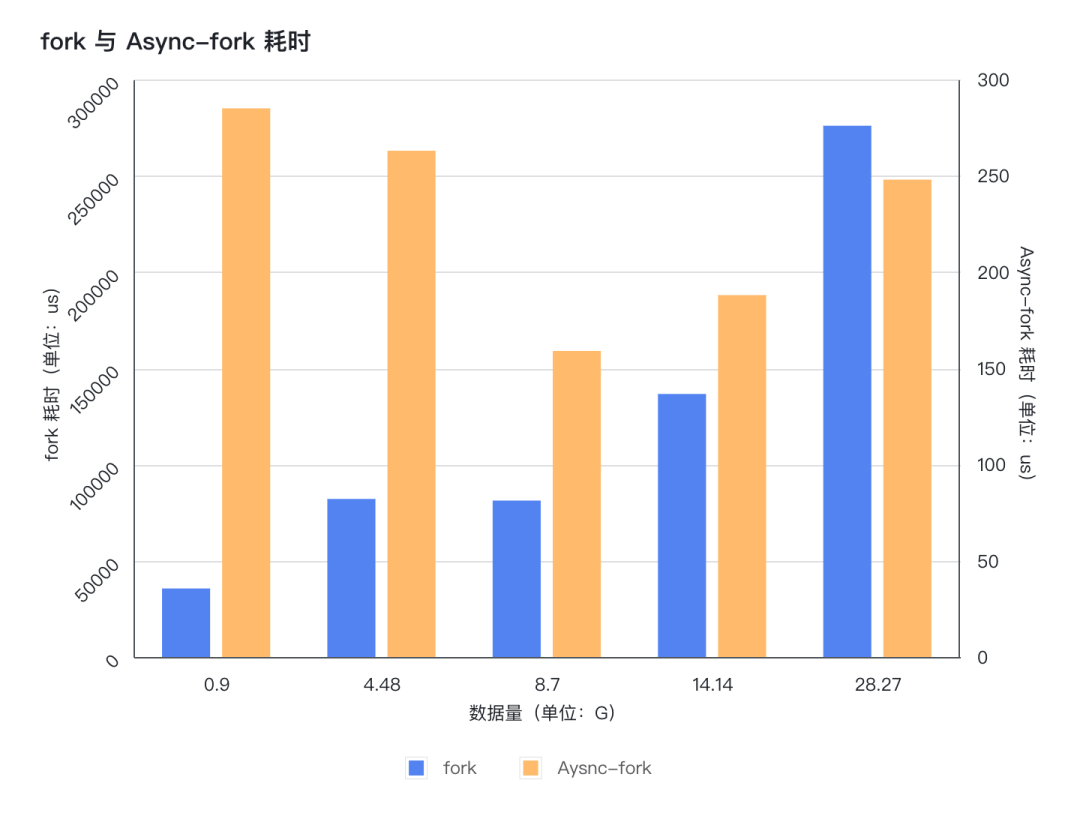
注:由于fork与Async-fork系统下,fork()操作产生的 latest_fork_usec 数据差距悬殊非常大,使用单纵轴会导致Async-fork的数据在图表中显示不明显,不方便查看,因此,该图表使用了双纵轴;虽然Async-fork的图表看起来比较高,但是实际右纵轴范围小,所以数据小。
从图表可以看出,使用支持Async-fork的操作系统,fork()操作产生的耗时非常小,不管数据量多大,耗时都非常稳定,基本在200微秒左右;而原生fork产生的耗时会随着数据量增长而增长,而且是从几十毫秒增长到几百毫秒。
7.2 TP100抖动
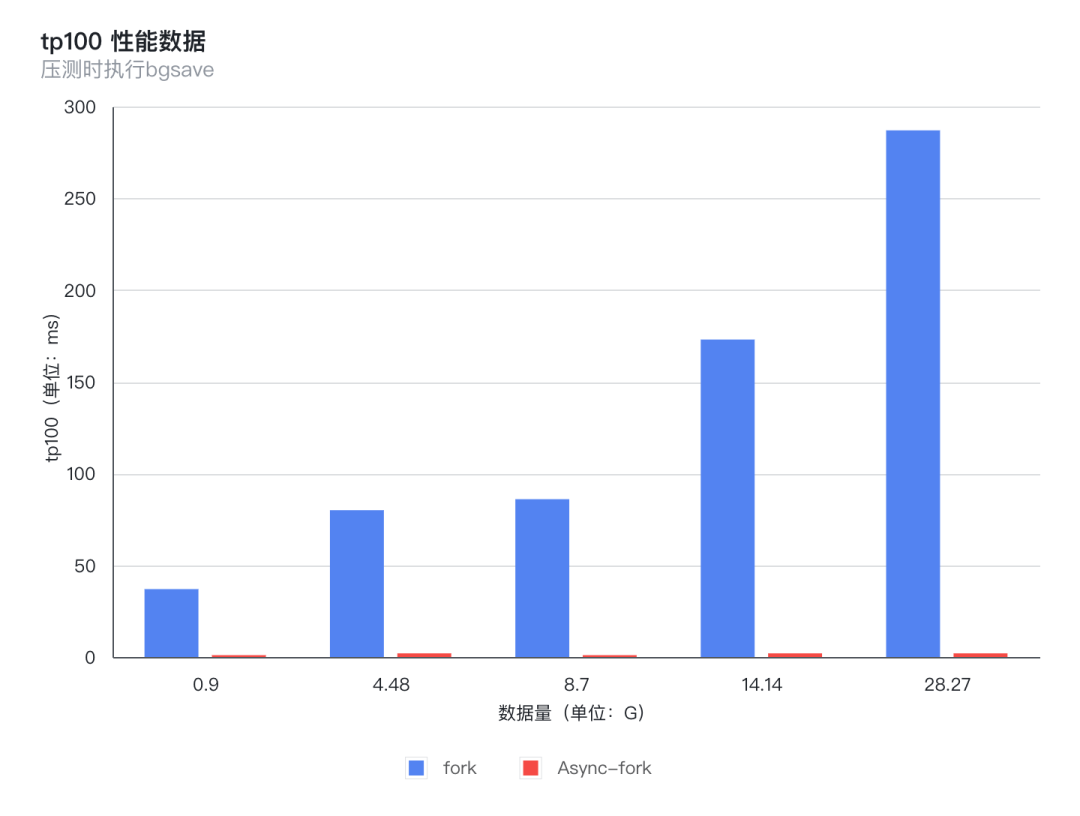
从图上可以看出,使用支持Async-fork的操作系统,fork()操作对Redis压测产生的性能影响非常小,性能提升非常明显,不管数据量多大,耗时都非常稳定,基本在1-2毫秒左右;而原生fork产生的抖动影响时间会随着数据量增长而增长,TP100从几十毫秒增长到几百毫秒。
8. 总结
通过不同数据量下对比测试,我们可以看到,Async-fork相比原生fork,阻塞时间大大减少,性能提升非常明显。而且阻塞时间非常稳定,不会因为数据量的增长出现倍数级增长。
在单机测试场景下,8G数据量大小下,TP100和 latest_fork_usec 耗时均减少98% 以上。
基于论文中Async-fork的设计思想,Tair专属操作系统镜像已支持该特性,并且将该特性集成在原生fork 中,没有新增系统调用接口,理论上用户只需要使用支持Async-fork的操作系统,程序无需做任何修改,就可以享受到Async-fork特性带来的性能提升。对于Redis而言,我们也只需要对Redis稍加适配就可以获得该技术带来的红利。
在Redis应用场景中,在添加从节点、RDB文件备份、AOF持久化文件重写等场景下,应用支持Async-fork的操作系统,都将极大的减少对业务的影响。
[1] 《Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level》




 点击「阅读原文」查看 云数据库 Redis 版 更多内容
点击「阅读原文」查看 云数据库 Redis 版 更多内容
