




repmgrd介绍
repmgrd 作为运行在集群中每个节点上的一个管理和监控的守护程序,可以自动进行故障转移和维护复制关系,并提供有关每个节点状态的监控信息。
repmgrd 不依赖其他服务
提供的功能包括:
•众多的配置项提供选择
•根据场景可自定义对应执行脚本
•一个命令进入维护模式
•多数据中心场景,通过location限制候选主节点
•多种验证Postgresql存活状态方法(PostgreSQL ping, query execution or new connection)
保留监控数据(可选)
repmgrd 故障转移
见证节点介绍
是一个独立于当前主从复制数据库的Postgresql数据库。
目的是当发生failover场景时,用来证明主服务自身不可用还是数据中心网络问题
一个典型的场景
位于两个数据中心的主从复制结构。和主服务同一个数据中心上创建一个见证服务。当主服务不可用时,从节点判断逻辑,如果主服务和见证节点都不可见则认为是网络问题。如果主服务不可见,见证节点可见则认为是主服务发生问题。
注意事项:
不要将见证节点与主从服务安装在同一个物理机上。
多数据中心场景建议使用localiton来预防脑裂问题
见证节点只在repmgrd启用时有效。
添加见证节点
安装一个独立的Postgresql实例,配置参考普通的repmgr。
注册见证节点
repmgr -f etc/repmgr.conf witness register -h node1
思考: 见证节点是否需要运行repmgrd。见证节点不同于其他从节点,元数据可以通过流复制直接获取到。需要repmgrd来维护。
解决脑裂问题
多数据中心带来的脑裂问题,当不同数据中心的节点彼此不可见时,从库的服务发生failover 产生一个新的主节点。此时整个集群同时拥有两个主服务。
虽然见证服务可以在仲裁。但是见证服务存在如下弊端。
•需要保证见证节点与主服务节点位于同一个数据中心。
•当集群中多数节点与主服务节点不在同一个数据中心时,增加额外的维护成本,且不便扩展,尤其是大规模应用时。
repmgr4 提出location的概念,通过配置location来指定节点的物理位置。
当发生failover时。repmgr首先检测是否存在与主服务位于同一个localtion的服务是可见的。如果不存(即整个与主服务位于同一个数据中心的节点都不可见)在则认为是网络问题。不提升新主库,并且进入降级模式。
主服务可见性共识
更复杂的集群结构,当从节点服务连接不到主服务时,询问其他从服务最后一次看到主服务的时间。当存在节点可以连接到主服务则证明主服务还存活,并且可以正常提供写服务。此时不发生新的选举。
配置参数
primary_visibility_consensus=true
注意事项。必须每个服务都设置为true才生效
从节点断开连接
当standby_disconnect_on_failover设置为true时,在发生故障转移时首先从节点断开本地的wal receiver,并且等待所有其他节点断开自己的wal receiver。
这样做的目的是为确保在故障转移时,所有的节点lsn处于静止状态。
重要提示:
•Postgresql9.5 及以上,repmgr 的数据库用户具有超级用户权限
•standby_disconnect_on_failover 必须要所有节点服务都设置才生效
•注意设置此参数后将带来的延迟,包括确定自己wal receiver是否已经关闭。等他确认其他节点wal receiver 是否已经完全关闭
•开启此参数建议同时开启 primary_visibility_consensus
故障转移验证
在发生故障转移时,某个节点被选举为新的主节点时,可以通过配置自定义判断脚本,进一步决定当前是否可以被提升为主节点(用户可以自定义辅助逻辑)。必须在所有节点进行配置。
配置如下:
failover_validation_command=/path/to/script.sh %n
可使用参数:
•%n: node ID
•%a: node name
•%v: 可见节点数
•%u: number of shared upstream nodes
•%t: 总节点数
根据脚本返回码(是否非0)决定是否可以将当前节点提升为主节点,如果不符合条件,中断本次故障转移流程,election_rerun_interval 秒后进入下一轮故障转移流程。
级联复制
Postgresql 9.2 数据库具有了级联复制功能。repmgr 可以提供级联复制支持。
当发生故障转移时,repmgr保持级联关系不变。
在上游节点发生故障时下游节点自动重新尝试连接原上游节点的父节点。
主节点检测从库连接
以上的考虑情形大多是通过从节点检测主节点的运行情况来决定是否发生故障转移。在repmgr中主节点也可以检测到从节点的连接情况。
通过主机点不断的检测从节点的连接情况,当满足某些状况时可以执行自定义脚本。如发生故障转移后产生一个新的主服务时,其他的从节点也都跟着指向了新主节点,原主节点的从节点个数变为零。这时可以通过执行一个特殊的命令来阻止应用写入原主节点。
检测过程和标准
•间隔时间child_nodes_check_interval 默认5秒查询一次pg_stat_replication 视图,并与注册repmgr时指定upstream node为主及节点的列表进行对比
•如果检测到从节点不在pg_stat_replication 视图中。记录检测到的时间并触发 child_node_disconnect 事件
•如果从节点重新出现在pg_stat_repliation视图中,清除上面的检测时间记录,并触发 child_node_reconnect事件
•如果检测到一个新的从节点加入,将新节点加入到内部列表中并触发child_node_new_connect 事件
•如果在repmgr.conf中配置了参数child_nodes_disconnect_command,repmgrd会循环检测所有节点,如果检测到连接的从节点数小于child_nodes_connected_min_count (默认零)并且超过child_nodes_disconnect_timeout(默认30s)所指定的时间时,触发 child_nodes_disconnect_command 事件
•注意事项,在 repmgrd 启动时没有连接的子节点不会被认为是丢失的,因为 repmgrd 无法知道它们为什么没有被连接。
注意事项
•子节点配置为归档复制时
•子节点的primary_conninfo信息中的application_name与节点的 repmgr.conf文件中定义的节点名称相同。此外,这个application_name在整个复制集群中必须是唯一的。如果使用自定义的application_name,或者application_name在整个复制集群中不是唯一的,repmgr将无法可靠地监控子节点的连接。
配置参数
•child_nodes_check_interval 检测间隔时间 默认值5s
•child_nodes_disconnect_command 自定义脚本
•child_nodes_disconnect_timeout 超时时间 默认值30s
•child_nodes_connected_min_count 存活从库的最小值。当检测到存活的从节点数小于该值时,触发child_nodes_disconnect_command 事件。
•child_nodes_disconnect_min_count 丢失节点的最小值,当丢失的节点数大于该值时触发child_nodes_disconnect_command 事件。
注意child_nodes_connected_min_count 值会覆盖child_nodes_disconnect_min_count。当这两个参数都未设置时。检测到从节点存在个数为零时触发child_nodes_disconnect_command 事件。
事件类型
•child_node_disconnect
•child_node_reconnect
•child_node_new_connect
•child_nodes_disconnect_command
查看事件
repmgr cluster event --event=xxxxx (事件类型)
repmgrd 配置
Postgresql 配置 postgressql.conf 需要重启服务
shared_preload_libraries = 'repmgr'
•monitor_interval_secs 检测上游节点时间间隔 默认2秒
•connection_check_type 检测类型 PQping (default)、connection、query
•reconnect_attempts 重连尝试次数 默认6次
•reconnect_interval 重连尝试间隔时间
•degraded_monitoring_timeout 默认-1 禁止。默认情况下,repmgrd将无限期地继续处于降级监视模式。设置该参数超时(以秒为单位),之后repmgrd将终止。
必须设置的参数
•failover =automatic•promote_command =/'usr/bin/repmgr standby promote -f etc/repmgr.conf --log-to-file'•follow_command= '/usr/bin/repmgr standby follow -f etc/repmgr.conf --log-to-file --upstream-node-id=%n'
可选参数
priorityfailover_validation_commandprimary_visibility_consensusalways_promotestandby_disconnect_on_failoverelection_rerun_intervalsibling_nodes_disconnect_timeout
其他参数
除了以上配置,conninfo 也会影响 repmgr 如何与 PostgreSQL 进行网络连接,如参数connect_timeout。同时也受到系统网络设置 tcp_syn_retries将影响。
日志自动切割
/var/log/repmgr/repmgrd.log {missingokcompressrotate 52maxsize 100Mweeklycreate 0600 postgres postgrespostrotateusr/bin/killall -HUP repmgrdendscript}
repmgrd 操作
repmgrd 维护模式
进入维护模式后,将不会发生自动故障转移。
# 维护模式repmgr -f etc/repmgr.conf service pause# 解除维护模式repmgr -f etc/repmgr.conf service unpause# 查看当前模式repmgr -f etc/repmgr.conf service status
注意: 维护模式的状态不会因为重启repmgrd或Postgresql服务而改变。
当进行Postgresql 版本升级时,要完全关闭repmgrd 服务。并且安装与数据库对应的新版本repmgr。
手动故障转移repmgr standby switchover 会自动进行 pause/unpause 状态切换。
当Postgresql数据库通过pg_wal_replay_pause处于暂停wal日志回放状态时,故障转移会自动恢复wal回放。
注意执行repmgr_standby_promote 将被拒绝,直到管理员wal resumed恢复回放。
降级模式
当遇到某些情况时将进入 "降级监控 "模式,即 repmgrd 仍处于活动状态,但在等待情况的解决。
情况包括: 当发生故障时
•与主节点位于同一个数据中的的其他节点都不可见。根据location参数
•没有可以提升为主节点的候选节点
•候选节点不能被提升主节点
•节点不能作为新主节点的从节点
•节点没有设置自动故障转移
•主节点故障,但是没其他节点被提升为主节点
默认情况,降级模式将一致持续下去。但如果设置了degraded_monitoring_timeout参数,超过指定值,repmgrd将停止运行。
监控数据存储
当参数monitoring_history=true时,监控记录数据将会不断的写入到repmgr.monitoring_history表中。 可以使用命令repmgr cluster cleanup -k/ --keep-history (选择需要保留记录天数) 定期清理数据。
这些数据也会复制到从节点中,可以通过设置ALTER TABLE repmgr.monitoring_history SET UNLOGGED; 使数据不复制到从节点。
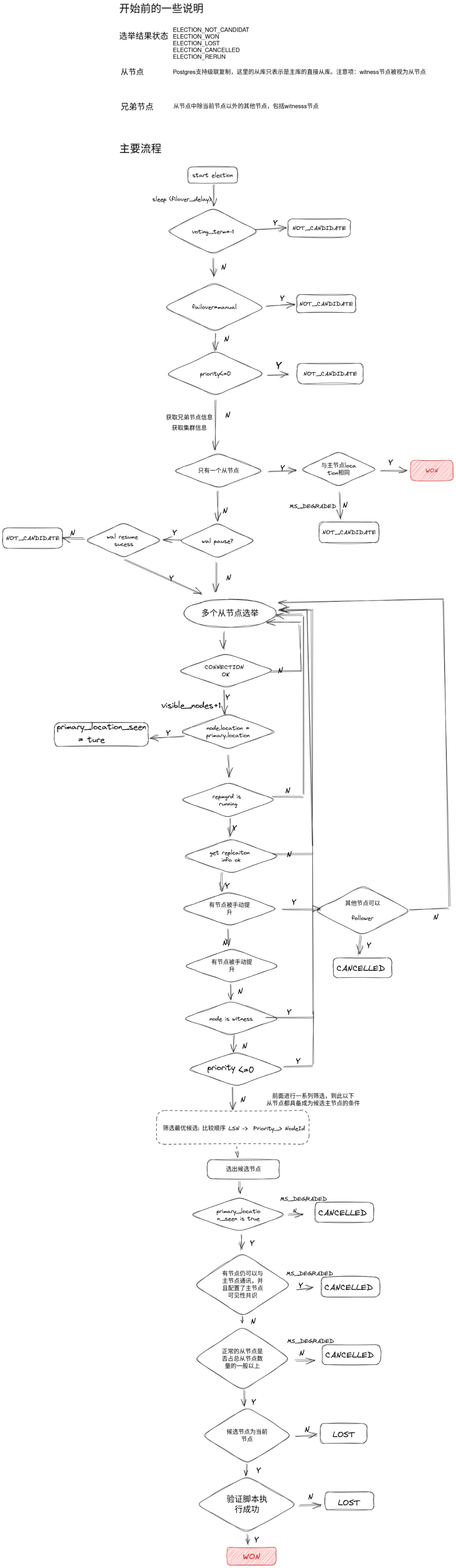
选举流程简介
源码位置 repmgrd-physical.c
当primary 节点被检测到发生故障,进入选举阶段时的大概流程。
/** Failover decision for nodes attached to the current primary.** NB: this function sets "sibling_nodes"; caller (do_primary_failover)* expects to be able to read this list*/# 选举流程 Postgresql 支持级联复制。新的主节点只能在一级子节点中产生。# sibling_nodes 兄弟节点static ElectionResultdo_election(NodeInfoList *sibling_nodes, int *new_primary_id){int electoral_term = -1;#NodeInfoListCell *cell = NULL;#t_node_info *candidate_node = NULL;# 选举状态election_stats stats;ReplInfo local_replication_info;* To collate details of nodes with primary visible for logging purposes */PQExpBufferData nodes_with_primary_visible;** Check if at least one server in the primary's location is visible; if* not we'll assume a network split between this node and the primary* location, and not promote any standby.** NOTE: this function is only ever called by standbys attached to the* current (unreachable) primary, so "upstream_node_info" will always* contain the primary node record.*/# 根据是否存在与故障节点位置相同的可见节点。如果都为不可见状态,则认为是网络问题。PS: 每个节点可配置location 参数指定所在的物理位置。如多数据中心场景bool primary_location_seen = false;int nodes_with_primary_still_visible = 0;if (config_file_options.failover_delay > 0){log_debug("sleeping %i seconds (\"failover_delay\") before initiating failover",config_file_options.failover_delay);sleep(config_file_options.failover_delay);}* we're visible */#可见节点数stats.visible_nodes = 1;#与当前node为相同上游的节点数 shared_upstream_nodes = sibling_nodes + 1(当前节点)stats.shared_upstream_nodes = 0;# 集群中所有节点数stats.all_nodes = 0;# SELECT term FROM repmgr.voting_term; 初始值为1 , 执行repmgr standby promote加一electoral_term = get_current_term(local_conn);if (electoral_term == -1){log_error(_("unable to determine electoral term"));return ELECTION_NOT_CANDIDATE;}log_debug("do_election(): electoral term is %i", electoral_term);# 如果repmgr.conf中failover参数设置为manual ,该节点不参与选举if (config_file_options.failover == FAILOVER_MANUAL){log_notice(_("this node is not configured for automatic failover so will not be considered as promotion candidate, and will not follow the new primary"));log_detail(_("\"failover\" is set to \"manual\" in repmgr.conf"));log_hint(_("manually execute \"repmgr standby follow\" to have this node follow the new primary"));return ELECTION_NOT_CANDIDATE;}#如果设置priority为0 ,该节点不参与选举 。见证节点的priority=0。及见证节点到这里已经出局* node priority is set to zero - don't become a candidate, and lose by default */if (local_node_info.priority <= 0){log_notice(_("this node's priority is %i so will not be considered as an automatic promotion candidate"),local_node_info.priority);return ELECTION_LOST;}#该方法 SQL 查询 视图repmgr.nodes ,获取兄弟节点。何为兄弟,与当前节点上游节点相同的节点,不包括自身。# 注意一点。见证节点的也算在兄弟节点中。因为在nodes表中他们的upstream_node_id 相同# SELECT REPMGR_NODES_COLUMNS FROM repmgr.nodes n WHERE n.upstream_node_id = %i AND n.node_id != %i AND n.active IS TRUE ORDER BY n.node_id* get all active nodes attached to upstream, excluding self */get_active_sibling_node_records(local_conn,local_node_info.node_id,upstream_node_info.node_id,sibling_nodes);log_info(_("%i active sibling nodes registered"), sibling_nodes->node_count);stats.shared_upstream_nodes = sibling_nodes->node_count + 1;#获取集群中所有节点数量 SELECT count(*) FROM repmgr.nodes nget_all_nodes_count(local_conn, &stats.all_nodes);log_info(_("%i total nodes registered"), stats.all_nodes);#判断记录当前节点位置是否与 上游节点(主节点)位置相同if (strncmp(upstream_node_info.location, local_node_info.location, MAXLEN) != 0){log_info(_("primary node \"%s\" (ID: %i) has location \"%s\", this node's location is \"%s\""),upstream_node_info.node_name,upstream_node_info.node_id,upstream_node_info.location,local_node_info.location);}else{log_info(_("primary node \"%s\" (ID: %i) and this node have the same location (\"%s\")"),upstream_node_info.node_name,upstream_node_info.node_id,local_node_info.location);}local_node_info.last_wal_receive_lsn = InvalidXLogRecPtr;# 没有兄弟节点,没有见证节点,独生子。如果与主节点位置相同直接继承王位,江湖中的打打杀杀在这里不存在。* fast path if no other standbys (or witness) exists - normally win by default */if (sibling_nodes->node_count == 0){ # 比较上游节点(原主节点)与当前节点的位置,如果相同if (strncmp(upstream_node_info.location, local_node_info.location, MAXLEN) == 0){# 升级为主服务前的配置的验证脚本,是否返回值为0if (config_file_options.failover_validation_command[0] != '\0'){return execute_failover_validation_command(&local_node_info, &stats);}log_info(_("no other sibling nodes - we win by default"));# 胜出,新王诞生。return ELECTION_WON;}else{** If primary and standby have different locations set, the assumption* is that no action should be taken as we can't tell whether there's* been a network interruption or not.** Normally a situation with primary and standby in different physical* locations would be handled by leaving the location as "default" and* setting up a witness server in the primary's location.*/log_debug("no other nodes, but primary and standby locations differ");# 虽然只有一个从节点,但是与主节点的位置不同,不能进行升级。集群进行降级处理。很遗憾。# 相当于 主节点相同位置的节点都不可见。被认为网络分区故障。monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);return ELECTION_NOT_CANDIDATE;}}# 当有多个兄弟的时候else{* standby nodes found - check if we're in the primary location before checking theirs */ # 当前节点是否与主节点位置相同if (strncmp(upstream_node_info.location, local_node_info.location, MAXLEN) == 0){ # 存在与主节点位置相同的直接从节点primary_location_seen = true;}}* get our lsn */ #if (get_replication_info(local_conn, STANDBY, &local_replication_info) == false){log_error(_("unable to retrieve replication information for local node"));return ELECTION_LOST;}# wal 回放状态为 paused ,尝试恢复wal回放状态 , resume失败 当前节点不参与选举* check if WAL replay on local node is paused */if (local_replication_info.wal_replay_paused == true){log_debug("WAL replay is paused");if (local_replication_info.last_wal_receive_lsn > local_replication_info.last_wal_replay_lsn){log_warning(_("WAL replay on this node is paused and WAL is pending replay"));log_detail(_("replay paused at %X/%X; last WAL received is %X/%X"),format_lsn(local_replication_info.last_wal_replay_lsn),format_lsn(local_replication_info.last_wal_receive_lsn));}# 尝试恢复wal状态* attempt to resume WAL replay - unlikely this will fail, but just in case */if (resume_wal_replay(local_conn) == false){log_error(_("unable to resume WAL replay"));log_detail(_("this node cannot be reliably promoted"));# resume 失败,该节点不参与选举return ELECTION_LOST;}log_notice(_("WAL replay forcibly resumed"));}local_node_info.last_wal_receive_lsn = local_replication_info.last_wal_receive_lsn;log_info(_("local node's last receive lsn: %X/%X"), format_lsn(local_node_info.last_wal_receive_lsn));* pointer to "winning" node, initially self */candidate_node = &local_node_info;initPQExpBuffer(&nodes_with_primary_visible);# 众候选节点进入选举会场,开始厮杀。for (cell = sibling_nodes->head; cell; cell = cell->next){ReplInfo sibling_replication_info;log_info(_("checking state of sibling node \"%s\" (ID: %i)"),cell->node_info->node_name,cell->node_info->node_id);* assume the worst case */cell->node_info->node_status = NODE_STATUS_UNKNOWN;cell->node_info->conn = establish_db_connection(cell->node_info->conninfo, false);if (PQstatus(cell->node_info->conn) != CONNECTION_OK){close_connection(&cell->node_info->conn);continue;}cell->node_info->node_status = NODE_STATUS_UP;stats.visible_nodes++;** see if the node is in the primary's location (but skip the check if* we've seen a node there already)*/if (primary_location_seen == false){if (strncmp(cell->node_info->location, upstream_node_info.location, MAXLEN) == 0){log_debug("node %i in primary location \"%s\"",cell->node_info->node_id,cell->node_info->location);primary_location_seen = true;}}** check if repmgrd running - skip if not** TODO: include pid query in replication info query?** NOTE: from Pg12 we could execute "pg_promote()" from a running repmgrd;* here we'll need to find a way of ensuring only one repmgrd does this*/if (repmgrd_get_pid(cell->node_info->conn) == UNKNOWN_PID){log_warning(_("repmgrd not running on node \"%s\" (ID: %i), skipping"),cell->node_info->node_name,cell->node_info->node_id);continue;}if (get_replication_info(cell->node_info->conn, cell->node_info->type, &sibling_replication_info) == false){log_warning(_("unable to retrieve replication information for node \"%s\" (ID: %i), skipping"),cell->node_info->node_name,cell->node_info->node_id);continue;}** Check if node is not in recovery - it may have been promoted* outside of the failover mechanism, in which case we may be able* to follow it.*/# 有兄弟节点被手动提升为主节点if (sibling_replication_info.in_recovery == false && cell->node_info->type != WITNESS){bool can_follow;log_warning(_("node \"%s\" (ID: %i) is not in recovery"),cell->node_info->node_name,cell->node_info->node_id);** Node is not in recovery, but still reporting an upstream* node ID; possible it was promoted manually (e.g. with "pg_ctl promote"),* or (less likely) the node's repmgrd has just switched to primary* monitoring node but has not yet unset the upstream node ID in* shared memory. Either way, log this.*/if (sibling_replication_info.upstream_node_id != UNKNOWN_NODE_ID){log_warning(_("node \"%s\" (ID: %i) still reports its upstream is node %i, last seen %i second(s) ago"),cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_node_id,sibling_replication_info.upstream_last_seen);}#检验当前节点是否能follow 被提升的兄弟节点can_follow = check_node_can_follow(local_conn,local_node_info.last_wal_receive_lsn,cell->node_info->conn,cell->node_info);# 在选举结果前有节点手动提升节点为主节点。并且当前节点可以follower。当前节点不在参与选举if (can_follow == true){*new_primary_id = cell->node_info->node_id;termPQExpBuffer(&nodes_with_primary_visible);return ELECTION_CANCELLED;}# 如果不能follower主节点。这种情况会很棘手。** Tricky situation here - we'll assume the node is a rogue primary*/log_warning(_("not possible to attach to node \"%s\" (ID: %i), ignoring"),cell->node_info->node_name,cell->node_info->node_id);continue;}else{log_info(_("node \"%s\" (ID: %i) reports its upstream is node %i, last seen %i second(s) ago"),cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_node_id,sibling_replication_info.upstream_last_seen);}* check if WAL replay on node is paused */if (sibling_replication_info.wal_replay_paused == true){** Theoretically the repmgrd on the node should have resumed WAL play* at this point.*/if (sibling_replication_info.last_wal_receive_lsn > sibling_replication_info.last_wal_replay_lsn){log_warning(_("WAL replay on node \"%s\" (ID: %i) is paused and WAL is pending replay"),cell->node_info->node_name,cell->node_info->node_id);}}** Check if node has seen primary "recently" - if so, we may have "partial primary visibility".* For now we'll assume the primary is visible if it's been seen less than* monitor_interval_secs * 2 seconds ago. We may need to adjust this, and/or make the value* configurable.*/if (sibling_replication_info.upstream_last_seen >= 0 && sibling_replication_info.upstream_last_seen < (config_file_options.monitor_interval_secs * 2)){if (sibling_replication_info.upstream_node_id != upstream_node_info.node_id){log_warning(_("assumed sibling node \"%s\" (ID: %i) monitoring different upstream node %i"),cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_node_id);}else{nodes_with_primary_still_visible++;log_notice(_("%s node \"%s\" (ID: %i) last saw primary node %i second(s) ago, considering primary still visible"),get_node_type_string(cell->node_info->type),cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_last_seen);appendPQExpBuffer(&nodes_with_primary_visible," - node \"%s\" (ID: %i): %i second(s) ago\n",cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_last_seen);}}else{log_info(_("%s node \"%s\" (ID: %i) last saw primary node %i second(s) ago"),get_node_type_string(cell->node_info->type),cell->node_info->node_name,cell->node_info->node_id,sibling_replication_info.upstream_last_seen);}# 见证节点不参与选举* don't interrogate a witness server */if (cell->node_info->type == WITNESS){log_debug("node %i is witness, not querying state", cell->node_info->node_id);continue;}# priority=0 的节点不参与选举* don't check 0-priority nodes */if (cell->node_info->priority <= 0){log_info(_("node \"%s\" (ID: %i) has priority of %i, skipping"),cell->node_info->node_name,cell->node_info->node_id,cell->node_info->priority);continue;}* get node's last receive LSN - if "higher" than current winner, current node is candidate */cell->node_info->last_wal_receive_lsn = sibling_replication_info.last_wal_receive_lsn;log_info(_("last receive LSN for sibling node \"%s\" (ID: %i) is: %X/%X"),cell->node_info->node_name,cell->node_info->node_id,format_lsn(cell->node_info->last_wal_receive_lsn));* compare LSN */ # 比较LSNif (cell->node_info->last_wal_receive_lsn > candidate_node->last_wal_receive_lsn){* other node is ahead */log_info(_("node \"%s\" (ID: %i) is ahead of current candidate \"%s\" (ID: %i)"),cell->node_info->node_name,cell->node_info->node_id,candidate_node->node_name,candidate_node->node_id);candidate_node = cell->node_info;}# LSN 相同比较 priority,priority也相同然后比较 node_id/* LSN is same - tiebreak on priority, then node_id */#LSN 对比else if (cell->node_info->last_wal_receive_lsn == candidate_node->last_wal_receive_lsn){log_info(_("node \"%s\" (ID: %i) has same LSN as current candidate \"%s\" (ID: %i)"),cell->node_info->node_name,cell->node_info->node_id,candidate_node->node_name,candidate_node->node_id);#priority 对比if (cell->node_info->priority > candidate_node->priority){log_info(_("node \"%s\" (ID: %i) has higher priority (%i) than current candidate \"%s\" (ID: %i) (%i)"),cell->node_info->node_name,cell->node_info->node_id,cell->node_info->priority,candidate_node->node_name,candidate_node->node_id,candidate_node->priority);candidate_node = cell->node_info;}else if (cell->node_info->priority == candidate_node->priority){if (cell->node_info->node_id < candidate_node->node_id){log_info(_("node \"%s\" (ID: %i) has same priority but lower node_id than current candidate \"%s\" (ID: %i)"),cell->node_info->node_name,cell->node_info->node_id,candidate_node->node_name,candidate_node->node_id);candidate_node = cell->node_info;}}else{log_info(_("node \"%s\" (ID: %i) has lower priority (%i) than current candidate \"%s\" (ID: %i) (%i)"),cell->node_info->node_name,cell->node_info->node_id,cell->node_info->priority,candidate_node->node_name,candidate_node->node_id,candidate_node->priority);}}}# 网络分区,降级。if (primary_location_seen == false){log_notice(_("no nodes from the primary location \"%s\" visible - assuming network split"),upstream_node_info.location);log_detail(_("node will enter degraded monitoring state waiting for reconnect"));monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);reset_node_voting_status();termPQExpBuffer(&nodes_with_primary_visible);return ELECTION_CANCELLED;}# 主节点仍可见if (nodes_with_primary_still_visible > 0){log_info(_("%i nodes can see the primary"),nodes_with_primary_still_visible);log_detail(_("following nodes can see the primary:\n%s"),nodes_with_primary_visible.data);#主节点可见性共识if (config_file_options.primary_visibility_consensus == true){log_notice(_("cancelling failover as some nodes can still see the primary"));monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);reset_node_voting_status();termPQExpBuffer(&nodes_with_primary_visible);return ELECTION_CANCELLED;}}termPQExpBuffer(&nodes_with_primary_visible);log_info(_("visible nodes: %i; total nodes: %i; no nodes have seen the primary within the last %i seconds"),stats.visible_nodes,stats.shared_upstream_nodes,(config_file_options.monitor_interval_secs * 2));# 同级节点中大部分不可见,不参与选举if (stats.visible_nodes <= (stats.shared_upstream_nodes / 2.0)){log_notice(_("unable to reach a qualified majority of nodes"));log_detail(_("node will enter degraded monitoring state waiting for reconnect"));monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);reset_node_voting_status();return ELECTION_CANCELLED;}log_notice(_("promotion candidate is \"%s\" (ID: %i)"),candidate_node->node_name,candidate_node->node_id);# 新选出的节点为当前节点if (candidate_node->node_id == local_node_info.node_id){/** If "failover_validation_command" is set, execute that command* and decide the result based on the command's output*/# 验证failover_validation_command 脚本的执行if (config_file_options.failover_validation_command[0] != '\0'){return execute_failover_validation_command(candidate_node, &stats);}# 当前节点宣布胜出,为主节点return ELECTION_WON;}return ELECTION_LOST;}if (primary_location_seen == false){log_notice(_("no nodes from the primary location \"%s\" visible - assuming network split"),upstream_node_info.location);log_detail(_("node will enter degraded monitoring state waiting for reconnect"));monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);reset_node_voting_status();termPQExpBuffer(&nodes_with_primary_visible);return ELECTION_CANCELLED;}if (nodes_with_primary_still_visible > 0){log_info(_("%i nodes can see the primary"),nodes_with_primary_still_visible);log_detail(_("following nodes can see the primary:\n%s"),nodes_with_primary_visible.data);if (config_file_options.primary_visibility_consensus == true){log_notice(_("cancelling failover as some nodes can still see the primary"));monitoring_state = MS_DEGRADED;INSTR_TIME_SET_CURRENT(degraded_monitoring_start);reset_node_voting_status();termPQExpBuffer(&nodes_with_primary_visible);return ELECTION_CANCELLED;}}
总结:
选举结果状态
ELECTION_NOT_CANDIDATELECTION_WONELECTION_LOSTELECTION_CANCELLEDELECTION_RERUN
根据location 或 winess节点决定集群是否处于网络分区状态,进入选举或降级模式。
当只有一个一级从节点
从节点原主节点位置相同直接选举成功。
从节点与原主节点位置不同且没有见证节点则降级。
不参与选举的节点
Priority=0
repmgr.conf中failover参数设置为manual
wal 处于 pause 状态将被resume。但resume失败
Repmgr选举候选备节点会以以下顺序选举:LSN-> Priority-> Node_ID。
流程图
功能增强
如何将repmgrd真正投入到生产中,真正的落地。在某些CASE面向仍能满足HA要求
Virtual IP
•注册主节点时,绑定vip
•Failover & Switchover时 利用failover_validation_command事件重新绑定vip
•整个集群重启时,识别出主节点绑定vip
主节点异常后恢复处理
•主节点网络问题,如网络防火墙等原因。Postgresql服务仍在运行,并可写。
设置参数 child_nodes_connected_min_count触发事件 child_nodes_disconnect_command 中定义回调方法将主节点降级为只读,或关闭。
异常恢复时,网络重新恢复连接。
找出集群故障转移后新主节点, 方法 libpq 中可写多个hosts。
pg_rewind 对齐时间线
rejoin 新集群
断电 ,不能做任何处理
电力恢复。服务重启,检测从库数量如果为0 暂时不提供服务。等待一段时间 stop service -> rejoin集群
从节点故障及恢复
•当从节点发生故障时不会引起故障转移。当需要注意当从节点故障恢复后wal日志会落后与主库。
对外服务管理
应用在通常情况下不会直接连接数据库,比如通过dns,haproxy等中间管理服务进行负载均衡和解耦。
在数据库发生故障转移时,对应用程序来说尽量做到不需变化,无感。
新增一个独立与现有服务之外的服务。
主要功能
提供一个七层http请求, 包括访问权限验证
返回值: 服务已经正常运行的时间 ps:上层负载均衡用户可参考该值进行权限分配。如节点刚接入集群缓存数据尚未准备充分,建议业务流量逐步接入。
返回码: 200 , 其他
主库 访问地址 ip:port/master ?xxx
如返回码为200,当前节点为主节点并且服务正常。
其他返回码,暂时不能提供写服务
主要判断逻辑: PG服务可连接性,下游节点个数
从库 访问地址 ip:port/replocation ?xxx
主要判断逻辑: PG服务可连接性,落后主节点的wal差值
可解决的问题
vip 不能跨网段管理
在Postgresql对外提供服务时进行健康状态检测。如果不满足需求,停止对应用提供服务,待恢复后在提供服务
故障切换时间预估
switchover & failover: 故障发生后检测切换的总时间预估
主要参考因素:
monitor_interval_secs 检测上游节点时间间隔 默认2秒
connection_check_type 检测类型 每次检测的timeout
reconnect_attempts 重连尝试次数 默认6次
reconnect_interval 重连尝试间隔时间
只有两个节点
主要面临问题: 两个节点主要是当发生网络故障时,而非postgres数据库应用问题时。从库无法判断是网络还是主库发生了故障。见证节点主要是为了解决这样的问题。
解决思路: 模拟见证节点。在从库无法与主库通信时,ping 一个其他节点。或ping 网关或自己的ip。当ping失败时认为发生了网络问题。
具体实现: 配置
failover_validation_commandfailover_validation_command.sh
#! bin/bashping -c 5 {{ inventory_hostname }}if [ $? -eq 0 ]; thenecho "ping $ip success!"return 0elseecho "ping $ip fail!"return 1fi
