




1
故障概述
2022年8月7号中午左右,驻场的同事打电话反馈Exadata X8M-2上的某个数据库出现hang的现象,业务数据无法写入,业务系统受到影响。
本文主要描述故障的处理过程,及事后的故障原因分析。
2
故障分析及处理过程
1、跟驻场的同事在电话里进行简单的交流后,得知该hang住的数据库是一套两节点的RAC数据库,节点1完全hang死,用sqlplus命令都无法连接到实例1,而实例2工作正常,没有出现hang的现象,也可以正常登录,连接到实例2的业务也能正常处理。
2、来不及让同事收集AWR、hanganalyze和systemstate之类的报告,先收集该数据库的当前等待事件看看,等待事件如下所示:

从该数据库当前的等待事件也可以看出,实例1有370个会话处于log file switch(checkpoint incomplete)。另外91个会话处于buffer busy waits。
log file switch(checkpoint incomplete)等待事件,说明checkpoint未完成,内存中的脏块未能写回数据文件,所以redo logfile无法重用,无法进行logfile日志切换,所以实例1最终hang住。
buffer busy waits等待事件,说明存在热块,关键要看这些热块是些什么数据块。
3、分析buffer busy waits等待事件。我们可以先检查是哪个会话阻塞了这些出现buffer busy waits等待事件的会话。查询的结果如下所示:

这个截图只是整个结果集的一部分,但FINAL_BLOCKING_INSTANCE和FINAL_BLOCKING_SESSION全部为1,1633。
这说明实例1中SID为1633的会话需要重点关注。检查实例1中SID为1633的会话信息如下所示:

这说明实例1中SID为1633的会话是LGWR进程。
4、当看到buffer busy waits等待事件最终的阻塞进程为LGWR,同时存在大量会话的等待事件为log file switch(checkpoint incomplete)时,基本上可以肯定当前实例1的redo logfile全部为活动状态(ACTIVE和CURRENT)。现场的同事收集了redolog相关的信息,如下所示:
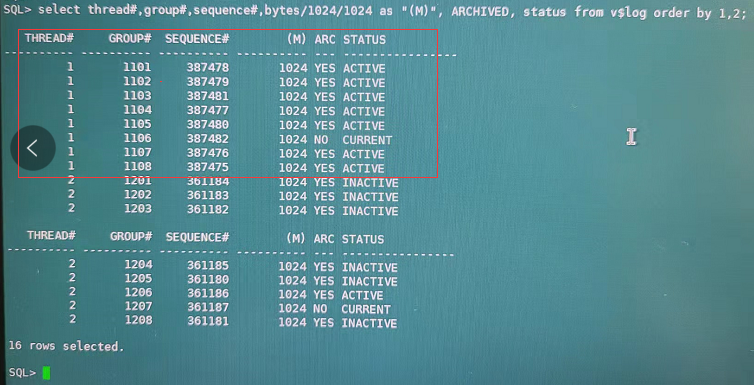
可以看出,实例1和实例2各有8组redo logfile,每组大小为1GB,而实例1的redo logfile当前全部为活动状态。
redo logfile的状态为ACTIVE,表示该logfile中所涉及到的脏数据块还在内存中,未被刷回数据文件,此时,如果数据库实例CRASH掉,则需要进行实例恢复,从ACTIVE的logfile中恢复已经修改的数据。当前这个故障,简单来说,就是脏数据块还在内存中,未被刷回数据文件,检查点工作未完成。
5、这种故障,绝大部分情况,是由于数据修改业务量爆增,导致在短时间内产生大量的redo日志,redo logfile切换的速度快于刷回脏数据的速度,最终导致所有的redo logfile全部为ACTIVE。这种情况的解决办法是:增加日志组的数量,或者增大日志组的大小就可以解决问题。极少数的情况,是由于数据文件所在的磁盘性能低下,导致刷回脏数据的速度太慢。这种情况就需要更换更高性能的磁盘来存放数据文件。
6、让同事赶紧给实例1加4组redo,每组大小为4GB。加完redo后,同事反馈实例1恢复正常了,sqlplus工具也能正常登录了。当时想着,这也太简单了。但是没多久,同事的电话再次响起,实例1又hang住了,检查发现还是log file switch(checkpoint incomplete)等待事件最为严重,刚刚添加的4组redo,全部为ACTIVE状态。难道添加的4组redo还不够?又让同事添加了10组大小为4GB的redo,实例1hang的现象立马消失。但是,过了没多久,实例1再次hang住,现象为仍然是log file switch(checkpoint incomplete),实例1的所有redo组全部为ACTIVE状态。
7、前面提到过,这种故障,也可能是因为数据文件所在的磁盘性能低下所导致。但这个可能性完全可以排除,因为:1、这是ExadataX8M-2(8台存储节点),同时FlashCache开启了WriteBack模式,所以写IO的性能肯定非常非常好。2、这套ExadataX8M-2环境,上面运行着多套数据库,别的数据库都运行性能良好,未出现性能问题。3、现场的同事也查看了所有存储节点的IO情况,出现问题时,存储节点的IO使用率都非常低。此时,感觉这个故障没这么简单。
8、让同事手动执行alter system checkpoint;该命令一直hang住,为什么checkpoint无法完成?checkpoint的过程主要涉及到dbwn进程刷脏数据和ckpt进程更新控制文件和数据文件的SCN。目前这种情况,只能尝试跟踪dbwn和ckpt进程,收集进程的errorstack 和pstack信息。
9、根据pstack和errorstack中的函数调用,去ORACLE官网搜索相关的BUG,但未找到匹配的BUG。通过各种关键字搜索官网时,找到一篇文章《Bug 9143376 - Database Hang by DBWR Automatic Archived or Redo Dump for a Corrupt Block (Doc ID 9143376.8)》,该文章中提及的故障Symptoms也是:
(1).数据库hang。
(2). Waits for "log file switch (checkpoint incomplete)"。
REDISCOVERY INFORMATION包括:
(1). a database hang, lasting minutes or hours
(2). the tracefile of one of the critical oracle background processes contains a dump of selected redo, with timestamps matching the time the database hang was observed. in 11.1 onwards, look for the lines "DUMP REDO".
(3). a stack trace of the oracle process taken during the hang, shows redo dump routines on the stack: in 11.1 onwards, look for kcra_dump_redo_internal()
10、查看该数据库的alert日志,在数据库出现hang现象之前,已经有如下日志产生。
Sun Aug 07 00:01:15 2022
Hex dump of (file 137, block 473055) in trace file u01/app/oracle/diag/rdbms/sdswj2yy/sdswj2yy1/trace/sdswj2yy1_dbw9_237964.trc
Corrupt block relative dba: 0x224737df (file 137, block 473055)
Bad check value found during preparing block for write
Data in bad block:
type: 6 format: 2 rdba: 0x224737df
last change scn: 0x10e8.b838a402 seq: 0x1 flg: 0x04
spare1: 0x0 spare2: 0x0 spare3: 0x0
consistency value in tail: 0xa4020601
check value in block header: 0xd931
computed block checksum: 0x392a
Sun Aug 07 00:01:15 2022
Block Corruption Recovery: buf=0x2efcc3b78 seqno=1
看到这些坏块信息,更加觉得当前故障与上面提及的那篇文档非常接近。
11、继续查看DBWn进程和CKPT进程的trace日志,在DBWn进程的trace日志中看到如下日志。
Corrupt block relative dba: 0x224737df (file 137, block 473055)
Bad check value found during preparing block for write
Data in bad block:
type: 6 format: 2 rdba: 0x224737df
last change scn: 0x10e8.b838a402 seq: 0x1 flg: 0x04
spare1: 0x0 spare2: 0x0 spare3: 0x0
consistency value in tail: 0xa4020601
check value in block header: 0xd931
computed block checksum: 0x392a
kcra_dump_redo_internal: skipped for critical process
kcbz_try_block_recovery <9, 575092703>: tries=0 max=5 cur=1659801674 last=0
BH (0x2efcc3b78) file#: 137 rdba: 0x224737df (137/473055) class: 1 ba: 0x2eeb10000
set: 282 pool: 3 bsz: 8192 bsi: 0 sflg: 1 pwc: 0,25
dbwrid: 5 obj: 276805 objn: 276805 tsn: 9 afn: 137 hint: f
hash: [0x3dfc01930,0x79cbb58f0] lru: [0x1bbba8b88,0x41bb37608]
obj-flags: object_write_list
ckptq: [0x12bab7598,0x1a7bd0798] fileq: [0x3f3bd9028,0x1afbc4988] objq: [0x825912e0,0x825912e0] objaq: [0x103b5c420,0x825912b0]
st: WRITING md: NULL tch: 0 le: (nil)
cr: [scn: 0x10e8.b83d539f],[xid: 0x0],[uba: 0x0],[cls: 0x10e8.b83d539f],[sfl: 0x0]
flags: buffer_dirty being_written block_written_once redo_since_read
LRBA: [0x5e993.1698ca.0] LSCN: [0x10e8.b838a402] HSCN: [0x10e8.b838a402] HSUB: [1]
BH (0x3dfc01878) file#: 137 rdba: 0x224737df (137/473055) class: 1 ba: 0x3ddc20000
set: 282 pool: 3 bsz: 8192 bsi: 0 sflg: 1 pwc: 0,25
dbwrid: 5 obj: 276805 objn: 276805 tsn: 9 afn: 137 hint: f
hash: [0x217cf0590,0x2efcc3c30] lru: [0x97d1e2a8,0x167cf3348]
ckptq: [NULL] fileq: [NULL] objq: [0x14bd7d230,0x825912c0] objaq: [0x4abd41520,0x28bb7aee0]
use: [0x7b3a7a8b8,0x7b3a7a8b8] wait: [NULL]
st: XCURRENT md: EXCL fpin: 'kddwh01: kdddel' tch: 0 le: 0x113f9a2f8
flags: clone_being_written block_written_once corrupt_being_recovered
redo_since_read
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [1]
GLOBAL CACHE ELEMENT DUMP (address: 0x113f9a2f8):
id1: 0x737df id2: 0x89 pkey: OBJ#276805 block: (137/473055)
lock: X rls: 0x0 acq: 0x0 latch: 21
flags: 0x20 fair: 0 recovery: 0 fpin: 'kddwh01: kdddel'
bscn: 0x10e8.b65a8809 bctx: (nil) write: 3 scan: 0x0
lcp: (nil) lnk: [NULL] lch: [0x3dfc019b0,0x3dfc019b0]
seq: 29325 hist: 180 239 143:0 208 352 32 197 48 121 239 144:0 7 352 32
LIST OF BUFFERS LINKED TO THIS GLOBAL CACHE ELEMENT:
flg: 0x02a00800 state: XCURRENT tsn: 9 tsh: 0 mode: EXCL
pin: 'kddwh01: kdddel' pinwait: 'log file sequential read'
addr: 0x3dfc01878 obj: 276805 cls: DATA bscn: 0x10e8.b838a402
kcra_dump_redo_internal: skipped for critical process
buffer rdba: 0x224737df
scn: 0x10e8.b838a402 seq: 0x01 flg: 0x04 tail: 0xa4020601
frmt: 0x02 chkval: 0xd931 type: 0x06=trans data
Hex dump of corrupt header 3 = CHKVAL
Dump of memory from 0x00000002EEB10000 to 0x00000002EEB10014
2EEB10000 0000A206 224737DF B838A402 040110E8 [.....7G"..8.....]
2EEB10010 0000D931 [1...]
Hex dump of corrupt block
Dump of memory from 0x00000002EEB10014 to 0x00000002EEB11FFC
2EEB10010 00000001 00043945 B6569C85 [....E9....V.]
2EEB10020 000010E8 00320002 22472205 00090705 [......2.."G"....]
2EEB10030 00000CFB 25C08CFB 00010478 00530001 [.......%x.....S.]
2EEB10040 00000000 00151606 00000D44 199959DC [........D....Y..]
2EEB10050 000D0504 00002026 B65A8801 00000000 [....& ....Z.....]
……(略)
从DBWn进程产生的trace日志来看,就是针对坏块(file 137, block 473055)进行dump操作。
12、既然知道了是因为数据坏块导致了这个故障,那么下面就来分析下这个数据坏块。只要修复掉这个坏块,DWNn进程就不会将坏块对应的redo信息给dump到DWNn进程的trace文件中,也就不会触发这个故障。
我们使用DBV、ANALYZED TABLE和RMAN工具来检索这个数据库的坏块时,惊奇地发现这个数据库中没有任何的物理坏块和逻辑坏块。那说明当前数据库中提及的这个坏块是内存坏块。
13、以前,针对这台Exadata进行健康巡检时,发现这台Exadata存在严重风险(EX67:(EX67) Database instances on Exadata X8M database servers may crash due to I/O buffer memory corruption (Doc ID 2748735.1)),该文档中提及,当数据库遭遇这个问题时,数据库后台日志中会有ORA-00600: [oss_write_compl_1]的错误提示。
继续查看该数据库的alert日志, 找到如下日志内容。
Thu Jul 07 17:01:15 2022
Errors in file /u01/app/oracle/diag/rdbms/sdswj2yy/sdswj2yy1/trace/sdswj2yy1_arc2_118313.trc (incident=216424):
ORA-00600: internal error code, arguments: [oss_write_compl_1], [946176], [948224], [0x7FFA9B7F6000], [0x00D7BC800], [], [], [], [], [], [], []
Incident details in: /u01/app/oracle/diag/rdbms/sdswj2yy/sdswj2yy1/incident/incdir_216424/sdswj2yy1_arc2_118313_i216424.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
ERROR: unrecoverable error ORA-600 raised in ASM I/O path; terminating process 118313
可见,在7月份,该数据库已经遭遇EX67风险。
14、下面,我们针对这个故障进行简单复盘。由于Exadata X8M-2当前的存储软件版本存在EX67风险,有可能导致内存坏块,当出现了内存坏块后,数据库的DWNn进程需要将这个坏块的内存信息全部打印出来写入trace文件,从而导致DWNn进程无法将内存中的脏数据刷回磁盘,而脏数据无法刷回磁盘就导致checkpoint无法完成,该节点所有的redo日志文件无法复用,最终导致该实例hang住。
15、最终,针对该Exadata X8M-2进行存储软件升级,升级完成后,该数据库已经平稳运行几个月都未出现坏块,也未再出现log file switch(checkpoint incomplete)故障。
