




平衡树,简称B-树,是最常见的数据库索引类型。一个B-树索引是被划分为多个范围的已排序的值列表。通过将键与一行或行范围关联起来,B-树可以对多种类型的查询提供优秀的检索性能,包括精确匹配和范围搜索等。
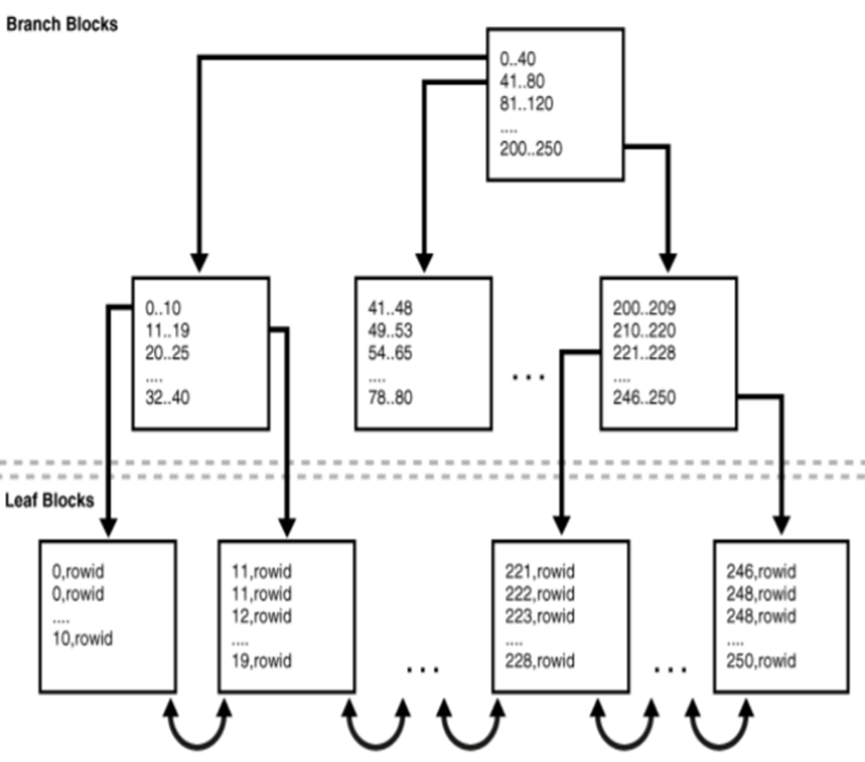
图3-1显示了一个B-树索引的结构。该示例显示在department_id列上的一个索引,它是雇员表的一个外键。
分支块和页块
B-树索引有两种类型的块:用于查找的分支块和用于存储值的叶块。B-树索引的上层分支块包含指向下层索引块的索引数据。在图3-1中,根分支块包含条目0-40,指向下一个分支级别中最左边的块。此分支块包含条目如0-10和11-19等。每个这些条目指向包含在该范围内键值的叶块。
B-树索引之所以是平衡的,是因为所有叶块都自动处于相同的深度。因此,在索引中从任意位置检索任意记录需要的时间基本上是相同的。索引的高度是从根块到叶块所需的块的数量。分支级别等于其高度减1。在图3-1中,索引的高度为3,分支级别为2。
分支块用于存储在两个键之间作出分支决定所需的最小键前缀。这种技术使数据库在每个分支块上能够尽可能存放更多的数据。分支块包含一个指针,该指针指向包含该键的子块。键和指针的数量受限于块大小。
叶块包含每个被索引的数据值,和一个相应的用来定位实际行的rowid。每个条目按(rowid,键)排序。在一个叶块内,键和rowid链接到其左右同级条目。这些叶块本身也双向链接在一起。如图3-1,最左边的叶块(0-10)链接到第二个叶块(11-19)。
注意:
在字符数据列上的索引,基于数据库字符集中字符的二进制值。
索引扫描
在索引扫描中,数据库使用语句指定的索引列,通过遍历索引来检索行。数据库扫描索引,将使用n个I/O就能找到其要查找的值,其中n即是B-树索引的高度。这是数据库索引背后的基本原理。
如果SQL语句仅访问被索引的列,那么数据库只需直接从索引中读取值,而不用读取表。如果该语句同时还需要访问除索引列之外的列,那么数据库会使用rowids来查找表中的行。通常,为检索表数据,数据库以交替方式先读取索引块,然后读取相应的表块。
完全索引扫描
在完全索引扫描中,数据库顺序读取整个索引。如果在SQL语句中的谓词(WHERE子句)引用了一个索引列,或者在某些情况下未不指定任何谓词,此时可能使用完全索引扫描。完全扫描可以消除排序,因为数据本身就是基于索引键排过序的。
假设应用程序运行以下查询:

此外假定department_id、last_name,和salary是一个复合索引键。Oracle数据库会执行完全索引扫描,按顺序读取(按部门ID和姓氏顺序)并基于薪金属性进行筛选。通过这种方式,数据库只需扫描一个小于雇员表的数据集,而不用扫描那些未包含在查询中的列,并避免了对该数据进行排序。
例如,完全扫描可能这样读取索引条目,如下所示:

快速完全索引扫描
快速完全索引扫描是一种完全索引扫描,数据库并不按特定的顺序读取索引块。数据库仅访问索引本身中的数据,而无需访问表。
当索引包含了查询所需的所有列,且索引键中至少一列具有NOTNULL约束时,快速完全索引扫描可以替代全表扫描。
例如,应用程序发出以下查询,不包含ORDERBY子句:

如果姓氏和工资是一个复合索引键,那么快速完全索引扫描只需读取索引条目,就可以获取所需的信息:

索引范围扫描
索引范围扫描是对索引的有序扫描,具有以下特点:
•在条件中指定了一个或多个索引前导列。条件指定一个或多个表达式和逻辑(布尔)运算符的组合,并返回一个值(TRUE、FALSE,或UNKNOWN)。
•一个索引键可能对应0个、1个或更多个值。
通常,数据库使用索引范围扫描来访问选择性的数据。选择性是查询所选择的数据占总行数的百分比,0意味着没有任何行,1表示所有行。选择性与一个(或多个)查询谓词相关,比如WHERElast_nameLIKE’A%’。值越接近0的谓词越具有选择性,相反,越接近1的谓词则越不具有选择性。
例如,用户查询姓氏以A开头的雇员。假定last_name列已被索引,其索引条目如下所示:

数据库可以使用范围扫描,因为在谓词中指定了last_name列,而且每个索引键可能对应多个rowids。例如有两个雇员名叫Austin,所以有两个rowids都与索引键Austin相关联。
索引范围扫描可以在两边都有边界,比如部门ID在10至40之间的查询,或只在一边有界,比如部门id在40以上的查询。为扫描索引,数据库将在叶块之间前后移动。例如,对于ID在10到40之间的扫描,将先定位到包含最低键值(大于或等于10)的第一个索引叶块。然后顺着各个被链接的页结点水平推进,直到它找到一个大于40的值为止。
唯一索引扫描
相对于索引范围扫描,唯一索引扫描必须是有0个或1个rowid与索引键相关联。当一个谓词使用相等运算符引用了唯一索引键的所有列时,数据库将执行唯一扫描。只要找到了第一个记录,唯一索引扫描就停止处理,因为不可能有第二个记录满足条件。
作为演示,假定用户运行如下查询:

假定employee_id列是主键,并具有如下的索引条目:

在这种情况下,数据库可以使用唯一索引扫描来定位rowid,以找到ID为5的雇员
索引跳跃扫描
索引跳跃扫描使用复合索引的逻辑子索引。数据库“跳跃地”通过单个索引,好像它在多个单独的索引中搜索一样。如果在复合索引前导键列中有少量不同值,而在非前导键列中有大量不同值,此时使用跳跃扫描是有益的。
当在查询谓词中未指定组合索引的前导列时,数据库可能选择索引跳跃扫描。例如,假定您要在sh.customers表中查找一个客户,运行如下查询:

customers表中有一列cust_gender,其值为M或F。假定在列cust_gender和cust_email上存在一个复合索引。示例3-1显示了索引条目的一部分。

虽然未在WHERE子句中指定cust_gender,数据库可以使用跳跃索引扫描。
在跳跃扫描中,逻辑子索引的数目决定于前导列中的非重复值的数目。在示例3-1中,前导列中有两个可能值。数据库在逻辑上将该索引拆分为一个具有F键的子索引和另一个具有M键的子索引。
当搜索电子邮件为Abbey@company.com的客户的记录时,数据库首先搜索F值的子索引,然后搜索M值的子索引。从概念上讲,数据库这样处理查询,如下所示:

索引聚簇因子
索引聚簇因子用于测量相对于某个索引值(如雇员姓氏)的行顺序。被索引值的行存储得越有序,则聚簇因子越低。
作为一种粗略测量通过索引读取整个表所需的I/O数,聚簇因子非常有用:
•如果聚簇因子较高,则在大型索引范围扫描过程中,数据库将执行相对较高数目的I/O。索引条目指向随机表块,因此数据库可能必须一遍又一遍地来回重读索引所指向的同一数据块。
•如果聚簇因子较低,则在大型索引范围扫描过程中数据库将执行相对较低数目的I/O。在一个范围内的索引键倾向于指向相同的数据块,因此该数据库不必来回重读相同的数据块。
聚簇因子与索引扫描关系密切,因为它可以显示:
•数据库是否会在大范围扫描中使用索引
•相对于索引键的表组织程度
•如果行必须按索引键顺序排列,是否应考虑使用索引组织表、分区、或表簇
例如,假定雇员表存放在两个数据块中。表3-1描述了两个数据块中的行(省略号表示未显示的数据)。
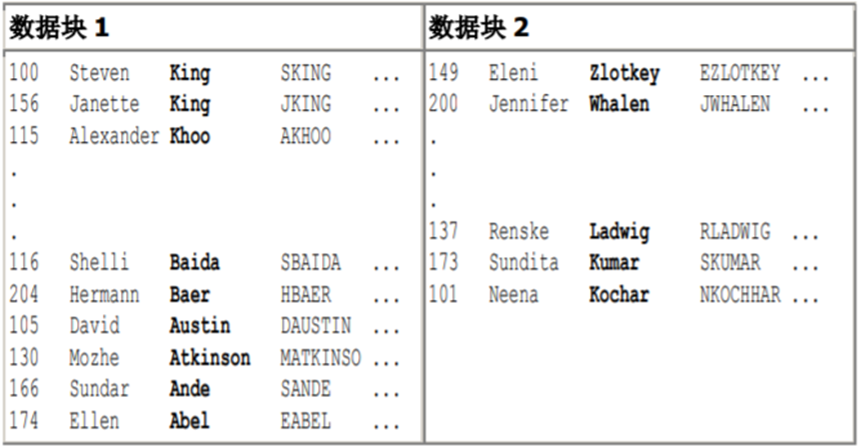
行以姓氏顺序(以粗体显示)存储在块中。例如,数据块1的最下面一行描述了Abel,往上一行描述了Ande,如此等等,按字母顺序直到最上面的一行描述了StevenKing。数据块2中的最下面行描述了Kochar,往上一行描述了Kumar,如此等等,按字母顺序直到最后一行描述了Zlotkey。
假设在姓氏列上存在一个索引。每个姓氏条目对应于一个rowid。从概念上讲,索引条目看起来如下所示:

假设在雇员ID列上存在另一个单独的索引。从概念上讲,索引条目可能看起来像下面这样,雇员id几乎分布在这整个两个数据块的任意位置:

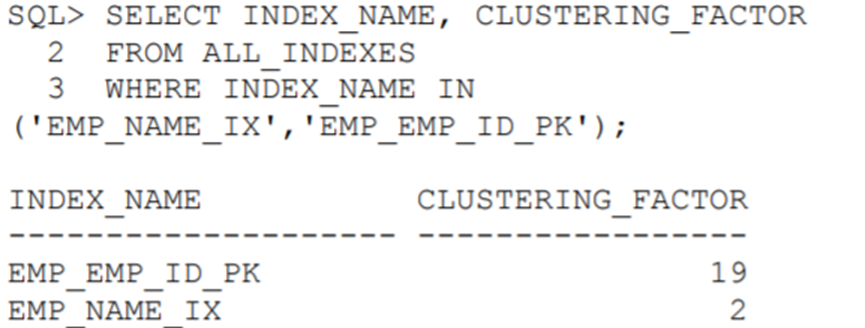
示例3-2所示的查询,通过ALL_INDEXES查看这两个索引的聚簇因子。EMP_NAME_IX的聚簇因子较低,这意味着在一个单一叶块中的相邻索引条目倾向于指向同一个数据块中的行。EMP_EMP_ID_PK的聚簇因子较高,这意味着在相同的叶块中的相邻索引条目不太可能指向同一个数据块中的行。
示例3-2聚簇因子
反向键索引
反向键索引是一种B-树索引,它在物理上反转每个索引键的字节,但保持列顺序不变。例如,如果索引键是20,,并且在一个标准的B-树索引中此键被存为十六进制的两个字节C115,那么反向键索引会将其存为15,C1。
反向键解决了在B-树索引右侧的的叶块争用问题。在Oracle真正应用集群(OracleRAC)数据库中的多个实例重复不断地修改同一数据块时,这个问题尤为严重。例如,在订单表中,订单的主键是连续的。在集群中的一个实例添加订单20,而另一个实例添加订单21,每个实例都将它的键写入索引右侧的相同叶块。
在一个反向键索引中,对字节顺序反转,会将插入分散到索引中的所有叶块。例如键20和21,本来在一个标准键索引中会相邻,现在存储在相隔很远的独立的块中。这样,顺序插入产生的I/O被更均匀地分布了。
因为存储数据时,并没有按照键列排序,因此在某些情况下,反向键格式丧失了执行索引范围扫描查询的能力。例如,如果用户发出一个订单id大于20的查询,但数据库不能从包含此ID的块开始扫描并沿着叶块水平推进。
升序和降序索引
对于升序索引,数据库按升序排列的顺序存储数据。默认情况下,字符数据按每个字节中包含的二进制值排序,数值数据按从小到大排序,日期数据从早到晚排序。
举一个升序索引的例子,请考虑下面的SQL语句:

Oracle数据库对hr.employees表按department_id列进行排序。从0开始,按department_id列及相应的rowid值的升序顺序加载索引。使用此索引,数据库搜索已排序的department_id值,并使用相关联的rowids来定位包含所请求的department_id值的行。
通过在CREATEINDEX语句中指定DESC关键字,您可以创建一个降序索引。在这种情况下,索引在指定的一列或多列上按降序顺序存储数据。如果在图3-1中employees.department_id列上的索引为降序,则包含250的叶块会在树的左侧,而0在右侧。降序索引的默认搜索顺序是从最高值到最低值。
当要求查询按一些列升序而另一些列降序排序时,降序索引非常有用。例如,假定您在last_name列和department_id列上创建一个复合索引,如下所示:

一个对hr.employees用户查询,要求按姓氏以升序顺序(A到Z)而部门id以降序(从高到低)排序,则数据库可以使用此索引检索数据并避免额外的排序步骤。
键压缩
Oracle数据库可以使用键压缩来压缩B-树索引或索引组织表中的主键列值的部分。键压缩可以大大减少索引所使用的空间。
一般地,索引键包含两个片断,一个分组片断和一个唯一片断。键压缩将索引键分成两部分,即作为分组片断的前缀条目,和作为唯一或几乎唯一片断的后缀条目。数据库通过在一个索引块中的多个后缀条目之间共享前缀条目来实现压缩。
注意:
如果某个键未被定义为具有唯一片断,那么数据库会通过将一个rowid附加到分组片断来提供唯一片断。
默认情况下,一个唯一索引的前缀由除最后一列之外的所有键列组成,而非唯一索引的前缀包含所有键列。例如,假设您在oe.orders表上创建一个复合索引,如下所示:

在order_mode和order_status列中有许多重复值出现。一个索引块中的条目可能如示例3-3中所示。

示例3-3中,键前缀将包括order_mode和order_status的串联值。如果此索引按默认键压缩创建,那么重复键前缀(如online,0和online,2)将会被压缩。从概念上讲,数据库按如下示例中所示实现压缩:

后缀条目形成索引行的压缩版本。每个后缀条目引用一个与其存储在相同索引块中的前缀条目。
或者,创建一个压缩索引时,您也可以指定前缀长度。例如,如果指定了前缀长度为1,那么前缀将会是order_mode,而后缀将会是order_status,rowid。对于示例3-3中的数值,索引会提取重复出现的online作为前缀,如下所示:

对索引中的每个叶块,一个特定前缀最多被存储一次。只有在B-树索引的叶块中的键会被压缩。在分支块中的键后缀可以被截断,但不会被压缩。
