





本文结合生产中的实际需求和测试结果,分享了对 TiDB + 数据仓库共建的构想。从技术优势、配置方式、场景实践等角度详细解析 TiDB 7.0 版本中的资源管控技术,同时深入介绍了 TiKV “partitioned-raft-kv”功能的用户价值、应用实践以及使用方式。
TiDB 6.5 新特性解析 | 解锁TiDB+数据仓库的新形态
从 v6.5.0 开始,TiCDC 支持将行变更事件保存至存储服务,这给 TiDB + 数据仓库带来了更多可能。本文由 TiDB 社区版主、数据架构师数据小黑撰写,结合生产中的实际需求和测试结果,分享了他对 TiDB + 数据仓库共建的构想。
1. 背景
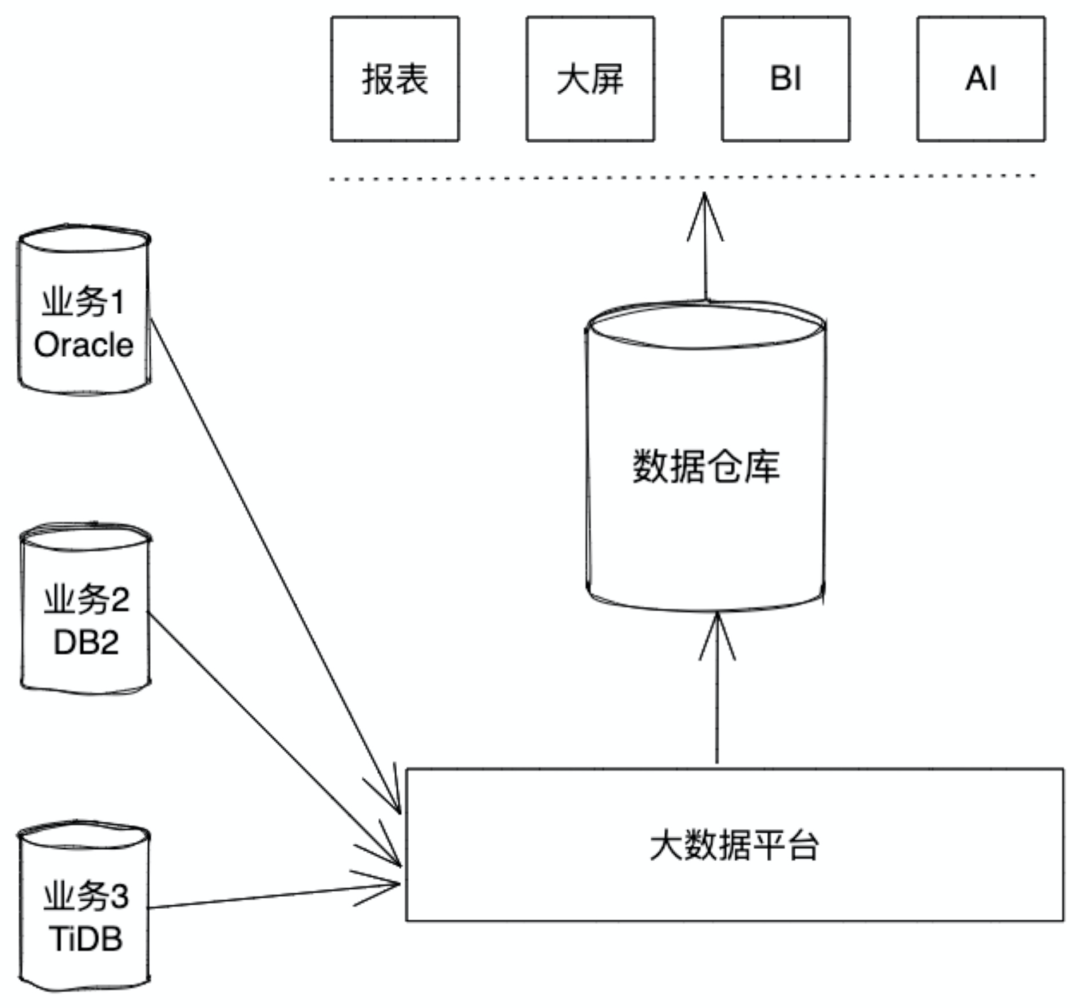
从 v6.5.0 开始,TiCDC 支持将行变更事件保存至存储服务,如 Amazon S3、Azure Blob Storage 和 NFS。
这个特性能够通过 TiCDC 这一个组件,就能保存 CDC 日志到对象存储中,这个特性满足对数据架构的一些想象,例如:
1.数据链路足够短
2.同步组件尽量少
结合这个特性,基于最近的一些实际需求和 POC 的成果,接下来将介绍与 TiDB 搭配的数据仓库应该是什么样的,是否能够有一个足够简单的架构,搭建一个适配大多数云的数据仓库。
2. 何为数据仓库 何为数据湖
数据仓库,英文名称为 Data Warehouse,可简写为 DW 或 DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。怎么理解上面这个解释,根据我们遇到的客户的诉求,数据仓库都是干这些事的:
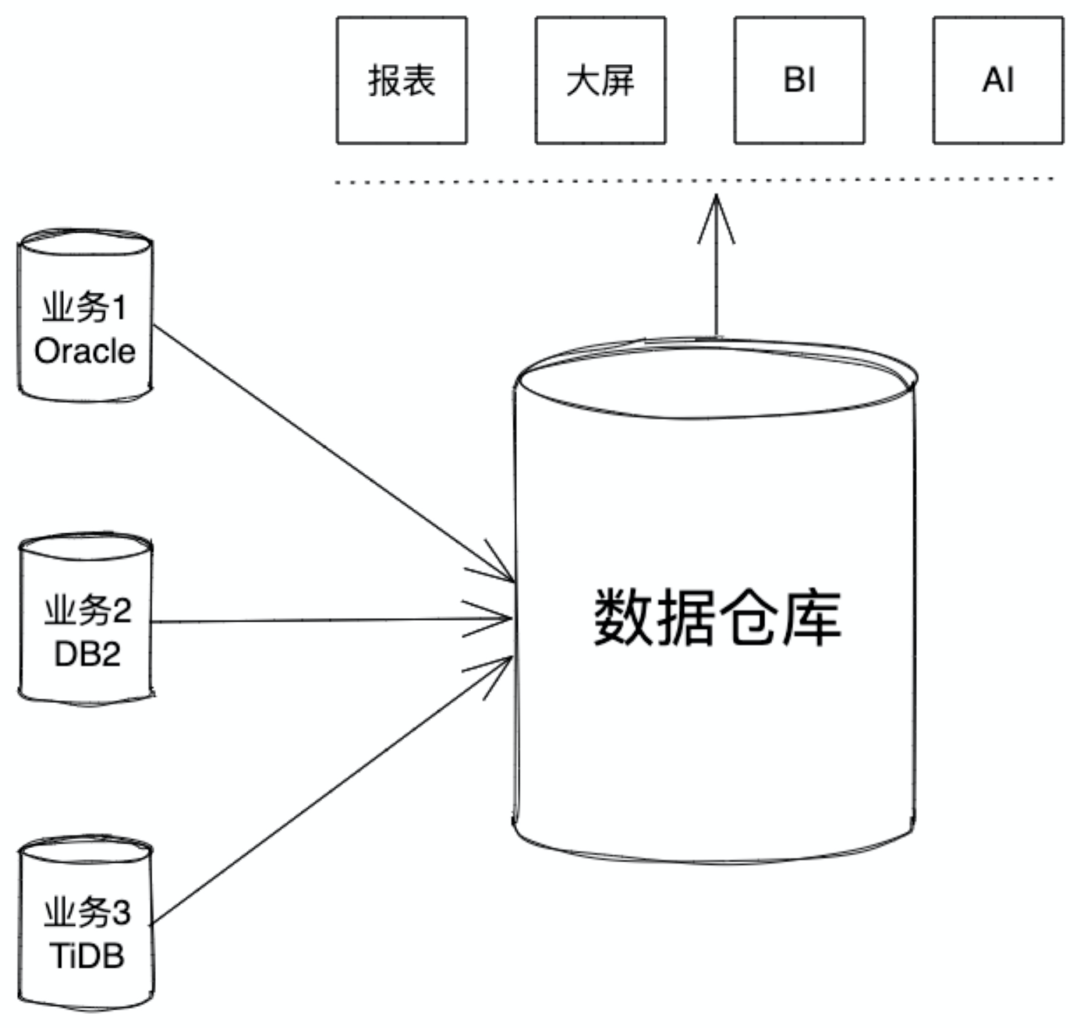
1. 大型企业内有各种各样的内部系统,一般情况下,这些业务系统建设时间不同,建设厂商不同,甚至于底层数据产品都有较大差异。领导要看全局,看大数,看趋势,需要一个架构把数据整合起来,这个架构叫做数据仓库
2. 一个企业内的数据相对比较单一,企业通过各种渠道汇集了多种多样的数据放在一起进行分析,这时候需要一个架构来解决采集数据的存储、计算、服务等多种问题,这个架构叫做数据仓库
以上的需求整合的数据,在整合之前就可以被准确认知,知道整合的目的。
假如企业基于战略目的,先执行收集数据的动作,然后从收集的数据中挖掘价值,此时的架构应该叫做数据湖
本篇文章只讨论一个场景:
1.业务应用的后端数据库是 TiDB
2.有分析较久远历史数据的需求
3.有接入第三方数据综合分析的需求
4.硬件投资有限,需要合理的架构充分发挥硬件性能
5.客户的部署环境不确定,需要适配大多数云
新特性解析丨TiDB资源管控的设计思路与场景解析
资源管控技术(Resource Control)是 TiDB 7.0 版本中优化提升的重要能力之一,不仅可以在负载剧烈变化时,保证服务质量,同时提供了数据库的多租户隔离能力,能够有效地降低数据库运行成本,帮助企业节省信息化管理开支,提升企业的竞争力。本文从将技术优势、配置方式、场景实践等角度详细解析 TiDB 7.0 版本中的资源管控技术。
作为可透明扩展的分布式数据库,TiDB 一直致力于满足企业对大型数据库集群的管理需要,集群内资源管控和资源隔离是企业客户长久以来的诉求之一。资源管控的主要目的在于解决数据库管理中常见的一些问题:
当多个业务共享同一数据库集群时,某个业务的非预期负载变化会影响其他业务的正常运行
当集群中存在混合负载时,对资源需求较高的数据分析或批量作业会影响在线交易类业务的响应时间
在需要 7x24 高可用性的业务系统中,数据备份、统计信息收集等后台任务可能会影响服务质量
应用灰度上线时,小流量引发的性能问题仍可能“击穿”整个生产数据库
为了解决上述场景中的问题,TiDB 开发了资源管控技术,于 TiDB 6.6 首次引入,并在 TiDB 7.0 进行了优化和增强。该技术利用资源组 (Resource Group) 将一个庞大的数据库集群划分为多个逻辑单元,每个资源组都能限制其所需的计算和 I/O 资源。通过特定设置,当集群有空闲资源时,允许一部分资源组超越其限制,以实现资源的充分利用。
1. 核心优势
TiDB 采用了业界领先的双层资源管控机制来实现更精确的管控。“流量控制”模块控制资源限额,确保仅在限额内的操作才能得以执行;“调度控制”模块则对队列中的任务设置不同的优先级,以确保在负载剧烈变化或超负荷运行时,高优先级的任务能够得到快速反馈。与同类产品通常只提供其中一层管控能力不同,TiDB 同时具备流控和调度控制能力,能够精确定义出更符合用户场景的配置。
基于存储计算分离的架构,TiDB 的资源管控对最重要的 I/O 资源进行了限制。I/O 吞吐通常是数据库系统最常见的资源瓶颈,也是资源管控的难点,多数数据库产品并不支持对 I/O 进行控制。只有控制住主要瓶颈,才能保证在资源阻塞时有疏通调控的手段。
把所有资源抽象成统一的单位来进行分配和限制。太过细粒度的设置通常难以衡量,也容易失去灵活性。TiDB 希望通过尽量少的指标来识别用户的意图,自适应地完成最佳的调度方案,提升易用性。
除了隔离性,提升资源利用率也是 TiDB 资源管控的重要目标。在整体资源尚有空闲的情况下,允许部分业务超过资源组定义的限制。
提供用量统计的精确反馈, 通过监控面板获取实际用量的使用情况,协助用户合理改进配置。同时,配合企业管理目标,TiDB 能够协助企业精确统计各部门数据库资源的使用情况,进而完成合理的成本分摊。
提供灵活的资源绑定手段。支持在用户级,会话级,和语句级指定资源的绑定方式,满足不同场景的资源控制需要。
TiDB Raft KV 新引擎:更高级别的可扩展性和写性能
TiKV 推出了名为“partitioned-raft-kv”的新实验性功能,该功能采用一种新的架构,不仅可以显著提高 TiDB 的可扩展性,还能提升 TiDB 的写吞吐量和性能稳定性。TiDB 6.6 之前的版本已经成功容纳超过 200 TB 的数据,甚至有客户将超过 500 TB 的数据放入 TiDB 集群中;开启新功能后,TiDB 的可扩展性能够提高到 PB 级别。本文将深入介绍 TiKV “partitioned-raft-kv”功能的用户价值、应用实践以及使用方式。
TiDB 是一种高度可扩展的分布式 HTAP 数据库,而 TiKV 是 TiDB 基于行的存储层。TiDB 的优势之一在于它的 OLTP 可扩展性:在 TiDB 6.6 之前,TiDB 集群可以轻松容纳超过 200 TB 的数据;有些客户正在将超过 500 TB 的数据放入 TiDB 集群中。相比之下,像 Aurora 这样的传统数据库则很难处理超过 100 TB 的数据。
在 TiDB 6.6 及后续的版本中,TiKV 的一个名为“partitioned-raft-kv”的新实验性功能可以将 TiDB 的可扩展性带到 PB 级别。它利用了一种新的架构,不仅可以提高可扩展性,还可以显著提高 TiDB 的写吞吐量和性能稳定性。
1. 用户价值
更高效:更好地利用硬件能力,消除写入流程中的瓶颈
更快:更好的写入性能和 QoS,特别是在大数据集下
更安全:每个表的物理隔离。
Partitioned-Raft-KV 的主要改进之一是将写放大显著降低,最高可降低 80%,从而可以释放更多的 IO 资源用于用户的实际读写流量。另一个主要改进是通过每个区域的专用 RocksDB 实例,消除了单个巨大 RocksDB 实例的逻辑瓶颈,因而在生成和应用快照时对用户流量没有逻辑影响。快照的唯一影响是 IO CPU 资源消耗,但因为降低了读放大,所以总的资源消耗仍然小于旧版本。
2. 性能测试
在 AWS m5.2xlarge 上运行 Sysbench 的批量插入:
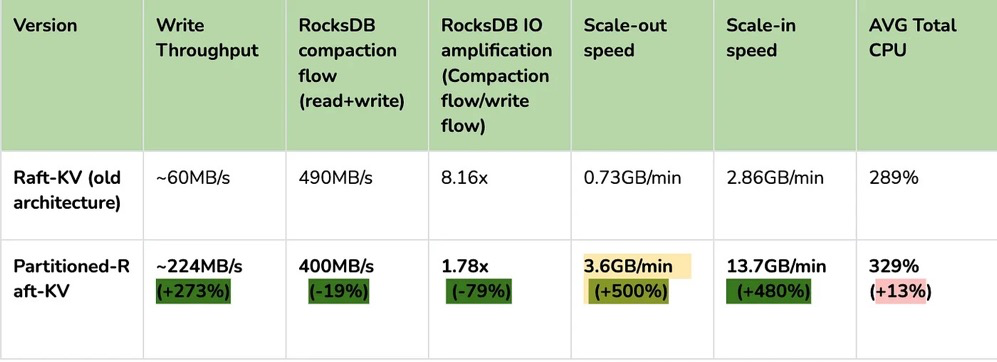
在这里,我们可以看到其写入吞吐量要高得多。I/O 吞吐越大,提升越明显。因此,该特性对大宽表(行大小> 4KB)的插入操作性能提升要比小表更明显。
另一个重要的改进是更快的扩缩容速度(即增加/减少 tikv 节点)。这意味着 TiKV 现在可以更快地响应用户流量的增长或下降。更重要的是,可以看到在扩缩容操作时,gRPC 的延迟和吞吐量不会受到影响,如下图所示。
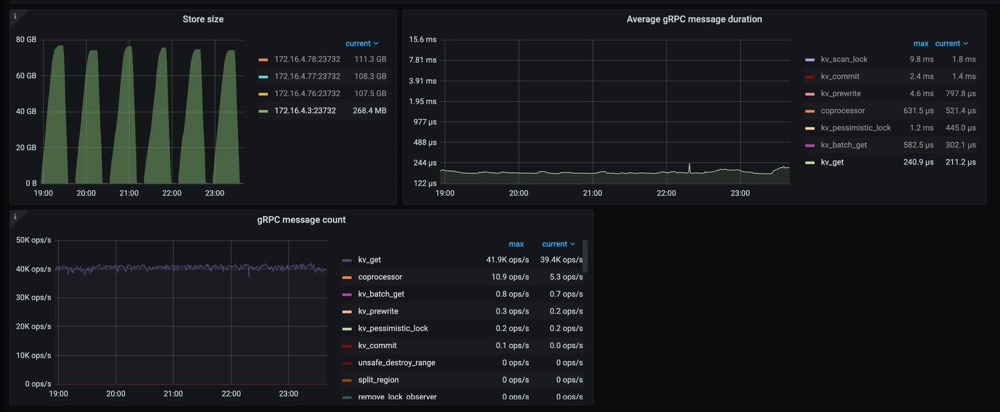
关于 CPU 使用率,Partitioned-Raft-KV 的 CPU 使用率即使在写入吞吐量更高的情况下也没有显著增加。这是因为工作负载本身并不是 CPU 密集型,并且 Partitioned-Raft-KV 的 compaction 相关操作占用的 CPU 较小,其内部消息编码也进行了优化。因此,单位吞吐量 (MB)的 CPU 使用率要低得多。
⬇️ 点击下方图片立即试用 TiDB 7.0 ⬇️

更多精彩敬请期待
