




李文杰
网易游戏计费 TiDB 负责人
读完需要
速读仅需 6 分钟
导读
当前的市场环境对产品运营提出了更高的要求,特别是对数据指标实时性的要求日益严格。为了能够实时监测数据动态和特征用户的状态,我们采用了分布式数据库 TiDB 和计算框架 Flink 的组合,提出了一种基于滑动窗口的实时累计指标算法。该算法能够在市场营销活动中发挥积极的作用,显著改善用户体验并促进收益增长。



基础数据量大,存在乱序、重复等问题:
数据源历史数据量较大,亿级别;日增日志数据在百万级别;
原始日志数据打印在不同应用机器上,没有集中统一存储,分散;
由于业务有等待逻辑,业务时间字段存在乱序问题,即先产生的数据的日志打印时间可能晚于后产生的数据的打印时间,时间乱序的数据如果不及时处理可能会出现漏算的情况;
由于业务有重试机制,相同的日志数据可能重复出现,数据重算会导致结果错误。
聚合指标要求支持高并发访问:
最终的结果指标要求支持 TP 服务访问,且满足高并发场景。
线上的应用部署在不同的机器上,先后请求的数据的业务时间和日志打印时间,可能是乱序的,这会导致我们需要解决数据排序的问题。且由于业务存在请求重试逻辑,数据也有可能是重复的,需要设计好去重机制。
保证计算的实时性、准确性:
需要处理数据乱序问题,使其有序,然后实时监听数据再分别进入统计周期开始边界、结束边界的变化情况,准确在累计值上执行加、减操作。
计算的事务性:
在对同一个用户的累计指标执行加、减操作时,要严格保证每个操作的原子性和隔离性;
此外,还要保证不同用户之间的操作也是事务隔离的。
累计指标可重入:
数据经过统计窗口边界时,有且仅有一次被计算,需要处理原始数据重复问题;
程序重启时数据计算结果应该保持不变,指标的值不会变多,也不会变少,即保证重入。

优点
方案简单,实现容易;
能获取到准确的指标结果。
缺点
由业务方维护计算的方法,访问和计算是同时进行的,没有做到分离;
数据库要有实时高并发的 AP 能力,对数据库要求过高;
计算全部依托于数据库,IO、CPU等资源容易出现瓶颈;
高并发时服务不稳定。
优点
支持实时高并发读取;
业务访问和计算分离,访问延迟低。
缺点
实时维护缓存,要引入额外的机制保障数据更新的事务性;
容易出现读写冲突问题;
数据没有落地,故障或宕机时数据丢失风险高;
计算复杂,且不可重入。
优点
支持实时高并发读取;
业务访问和计算分离,访问延迟低;
数据存储在数据库,保存有最新的数据状态,能保证数据安全和事务性,进而能保证计算是可重入的。
缺点
计算复杂,程序维护成本较高;
数据库要求高,必须能存储大量数据且支持高并发访问,且能应对未来的业务增长量。
首先要求数据库具有灵活的扩展性,必须能存储数以亿计的历史数据,且能应对还在不断增长的数据规模;
其次要支持良好的事务特性,这一方面支持最好的就是关系型数据库,要能保证数据操作时的事务隔离;
同时在高并发场景下保证读、写互不影响,支持业务高并发访问。


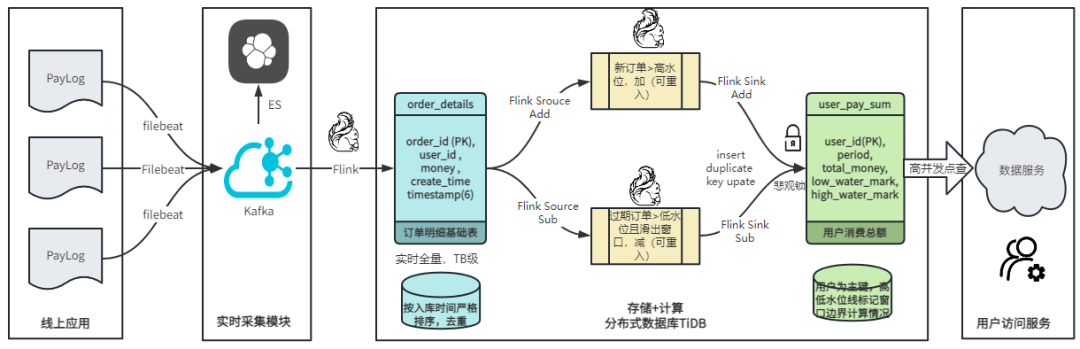
数据实时采集
线上应用在不同机器上部署,实时产生日志数据,通过 Filebeat 采集并汇总数据流写入到 Kafka 中。
借助 TiDB 关系型数据库的特性解决数据乱序、重复问题,生成基础数据
设计合理的业务唯一键,给每一行数据设置一个精确到微秒的入库时间(create_time timestamp(6),CT),在我们的业务场景,能得全部入库数据按 CT 字段严格有序;
同时,利用 TiDB 的唯一键特性对重复的数据去重;
Flink 消费 Kafka,将经过 ETL 后基础数据实时写入到 TiDB 中生成基础数据表,供后续计算、数据校验、监控使用。
数据指标的持久化和可重入计算
对 TiDB 的结果指标表设置用户维度的主键,同时设置每个用户在滑动窗口左、右边界已消费的数据的 CT 水位线,保证计算可重入要求,即经过窗口边界的数据只会计算一次;
Flink 双 Source 读取按 CT 切片的开始边界、结束边界的数据,用双 Sink 分别负责指标的加、减。TiDB 集群事先设置为悲观锁事务模式,Flink 作业在 Sink 时执行串行的 INSERT ON DUPLICATE KEY UPDATE 语句完成累计值的加、减操作,可以保证操作事务的原子性、隔离性。经过调优上线后,该方式在我们的计算场景里也有不错的性能,能满足业务需求。
计算和对外访问同时服务
利用 TiDB 写操作不阻塞读的特性,在计算的同时数据也在实时对外服务,不影响线上服务可用性;
用户是我们表的主键,而产品访问时是对用户的点查,所以我们的方案具备非常高的并发访问性能,远超过业务峰值。
通过提前设计合理的业务唯一键,Flink Sink 时用 INSERT INGORE 方式写入数据, 遇到相同的数据只会写入一行,达到去重的目的 ;
同时,设置一个精确到微秒的入库时间字段(create_time timestamp(6),下文简称 CT),在我们的业务场景里数亿行数据全部入库,每一行数据都能做到按 CT 字段有序递增 。
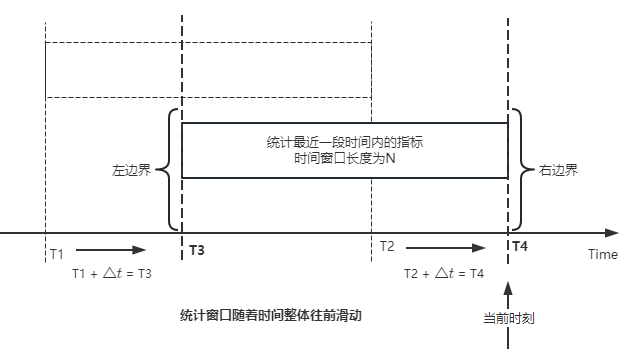
这两个 Source 读取数据的时间点,分别指向统计时间窗口的左、右边界。指向右边界的指针负责用户累计金额的加操作,指向左边界的指针负责用户累计金额的减操作,它们使用相同的步调随着时间推进;
假设有一个用户他每个时刻都有充值行为,那么随着时间推进,“最近 N 年”这个时间窗口也在不断推进,窗口的右边界是实时前进的,就会不断有新数据进来,计算累计值则需要不断加;窗口的左边界也在往前走,滑出左边界的数据就过期了、不在这个统计周期内了,所以左边界的指针就需不断减去这些值。
以用户为维度,每个用户指标都有 low_water_mark 和 high_water_mark 这两个水位线时间来做标记这个累计指标的计算状态,它们来自基础数据表的入库时间。用户指标的 high_water_mark 与 low_water_mark 和 Flink 作业里窗口的左边界和右边界不太一样,作业里的左右边界时间是和真实世界一样的绝对时间 (True Time),而它们是业务上的逻辑时间,所以它们之间时间跨度,是可以超过窗口的长度的,这样以保证能统计到完整周期的指标。
作业右边界指针读到的数据是最新的,要执行加操作,当在结果指标表没有该用户时(high_water_mark 为 null )说明是首次充值可以直接加,且同时设置该 CT 为其 low_water_mark 和 high_water_mark;如果该用户有在表里了则要求其 CT 大于 high_water_mark 才可以累加进去,否则不累加,累计进去的同时更新 high_water_mark 为当前 CT,以保证同一条数据的计算可重入,不会出现重复加的问题。
左边界指标读到的数据是统计周期内过期的数据,目标是减去,原始数据的有序性保证了经过左边界的数据一定已经经过右边界,即一定已经完成了加的操作,所以不存在结果指标表没有该用户时的情况,为了避免重复减的问题,要求过期数据的 CT 小于统计周期开始时间且大于 low_water_mark 才执行减操作,同时更新 low_water_mark 为当前 CT。如果 CT 小于等于 low_water_mark 说明已经执行过减操作,不需要重复操作。
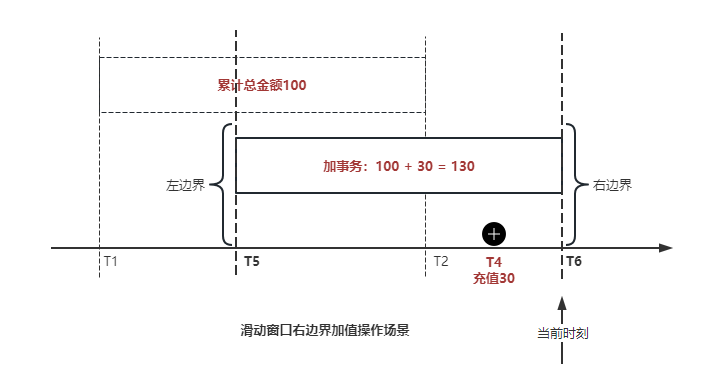
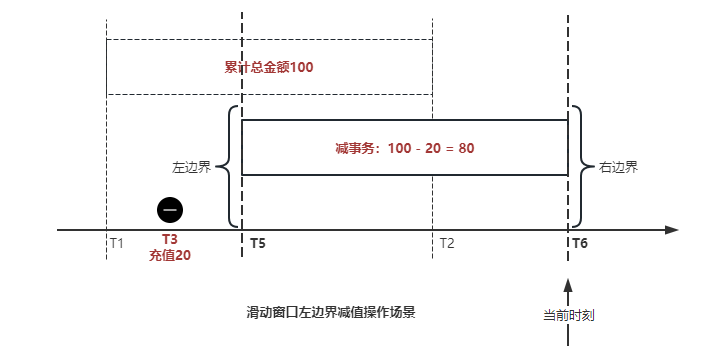
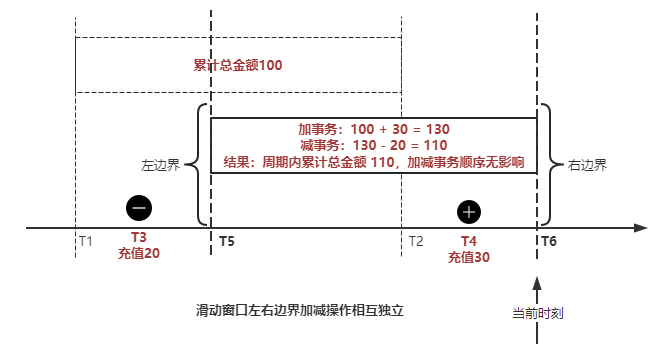

日志数据通过 Flink ETL 后写入到 TiDB 基础表,借助设置到微秒级别的入库时间,经过验证,在我们业务场景的数十亿行数据能能做到单调递增,这为我们后面的计算打下了关键性的基础。
计算流首次启动时要处理历史数据,要设置好窗口的左右边界,假设要统计最近 1 年的累计消费金额,则需要手动指定右边界的 Source 起点为 365 天前,左边界的 Source 起点为 730 天前(左右边界共同决定统计窗口的长度)。设置 2 年、3 年、5 年、10 年的场景以此类推。
在跑历史数据时,计算流的串行处理速度可以达到万级QPS,证明 TiDB 和 Flink 有非常优秀的计算能力;
历史数据量大,初始化耗时通常较久,一个优化的方法是基于历史日志数据,使用离线统计的方式一次性先算好基量指标,然后 Flink 作业再基于此结果来计算。这可以大大缩短指标首次上线、故障恢复、数据重算等场景的时间,极大提高用户体验。
计算策略里设计的每个环节都是可重入的,当遇到网络中断、数据库抖动或 Flink 流失败重启等故障,数据不会丢、也不会重算,可以保证数据的安全性。
该算法已正式上线到生产环境,已稳定对外提供数据服务有数月之余。为了保证数据消费的稳定性,在不影响整体服务体验的情况下,我们设置 Flink 的消费时间比实时数据略迟一点时间,这也是一个实时计算的最佳实践经验。
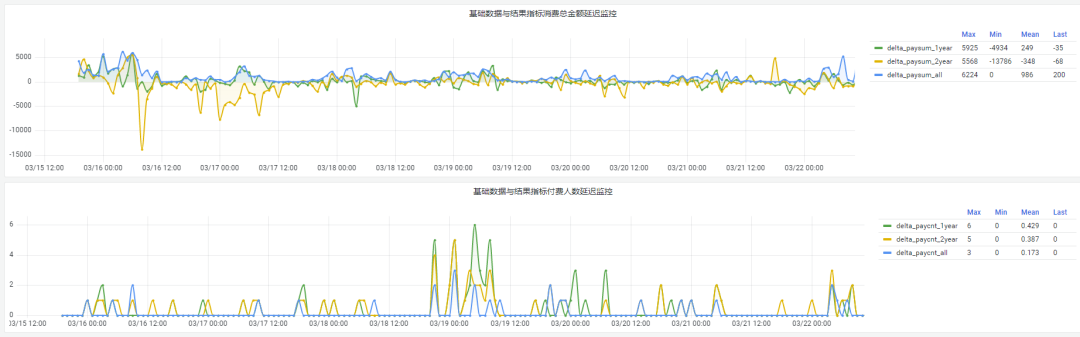

有明确时间范围的实时指标:
最近一段时间的实时充值总额、订单量、支付率等;
最近一段时间的实时 PU/ARPU/ARPPU 等;
最近一段时间的实时 AU/DAU//MAU、新增用户数等。
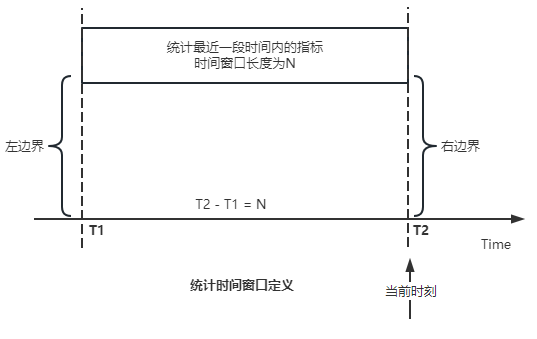
适用的统计周期:最近一段时间,即最近 N 时/天/周/月/年,指定的统计时间窗口长度;
适用的计算维度:产品、渠道、平台、用户、角色等。
如果对本文所提及的内容有任何疑问或建议,欢迎点击文末阅读原文,在 TiDB 社区专栏评论区共同交流。
/ 相关阅读

