




TutorialsPoint JSoup 教程
来源:易百教程
JSoup教程™
JSoup是一个用于处理HTML的Java库,它提供了一个非常方便类似于使用DOM,CSS和jquery的方法的API来提取和操作数据。
jsoup实现WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
- 从URL,文件或字符串中提取并解析HTML。
- 查找和提取数据,使用DOM遍历或CSS选择器。
- 操纵HTML元素,属性和文本。
- 根据安全的白名单清理用户提交的内容,以防止XSS攻击。
- 输出整洁的HTML。
jsoup旨在处理发现所有格式有差异的HTML; 从原始和验证,到无效的标签; jsoup将创建一个明智的解析树。
实例
获取维基百科主页,解析为DOM,并从新闻部分中选择标题列入元素列表:
Document doc = Jsoup.connect("http://en.wikipedia.org/").get();
Elements newsHeadlines = doc.select("#mp-itn b a");
以下是一个完整的示例,在这个示例中,它提取易百教程网首页的title标签中的字符串符。
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class FirstJsoupExample{
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String title = doc.title();
System.out.println("title is: " + title);
}
}
开源
jsoup是一个根据自由MIT许可证分发的开源项目。 源代码可在GitHub获得:http://github.com/jhy/jsoup/ 。
发展和支持
如果您有任何关于如何使用jsoup的问题,或有未来发展的想法,请通过邮件列表联系( http://jsoup.org/discussion )。
如果您发现任何问题,请在检查重复之后提交错误。
本教程问题
在本Jsoup教程中,我们是通过一些简单的开发和测试实例来一步步演示Jsoup的使用的,但是由于开发环境和工具的不同,我们不能保证所有实例均可在您的机器也能正常运行。 如果您在本教程中发现任何问题或错误,可以向我们报告。我们及时修改/修正错误以方便后来的学习者。
本站所有代码下载:请扫描本页面底部二维码并关注微信公众号,回复:"代码下载" 获取。
本文属作者原创,转载请注明出处:易百教程 » JSoup教程
JSoup安装 - JSoup教程™
要运行任何jsoup示例,需要先安装好jsoup相关Jar包。到目前为止(2017年05月),jsoup的当前版本是1.10.2.0。安装jsoup主要有三种方法:
- 通过Maven的pom.xml配置文件
- 使用jsoup.jar文件
- Gradle的配置文件(省略)
1)通过Maven的pom.xml文件配置
目前,maven被广泛应用于java开发。所以在这里建议使用maven来开发jsoup应用程序。
要使用maven安装jsoup,请在pom.xml文件中添加如下给定的依赖关系,不需要下载; 只需将以下内容放入POM的<dependencies>标签中:
<dependency>
<!-- jsoup HTML parser library @ http://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
2)使用jsoup.jar文件
如果您不使用maven框架,可以下载jsoup.jar文件。点击下载jsoup.jar文件,
在下载完成后,需要设置jsoup.jar文件的classpath。在控制台上写下面的命令
set classpath=jsoup-1.8.1.jar;.;%classpath%
提示: 使用IDE的话可以将上面的 jsoup.jar 添加到项目类库中。
有关依赖
jsoup是完全自包含的,没有依赖关系。
jsoup运行在Java 1.5及更高版本,Scala,Android,OSGi,Lambda 和 Google App Engine。
安装测试
这里以 Maven 为例,演示如何安装和使用JSoup,首先打开 Eclipse 创建一个名称为:HelloWordJSoup 的 Maven 工程,然后添加 pom.xml 的依懒,完整的 pom.xml内容如下 -
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yiibai</groupId>
<artifactId>HelloWordJSoup</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>HelloWordJSoup</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<!-- jsoup HTML parser library @ http://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
</dependencies>
</project>
创建一个Java类:FirstJsoupExample.java,其代码如下 -
package com.yiibai;
/**
* Hello world!
*
*/
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class FirstJsoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String title = doc.title();
System.out.println("title is: " + title);
}
}
运行上面代码,得到以下结果 -
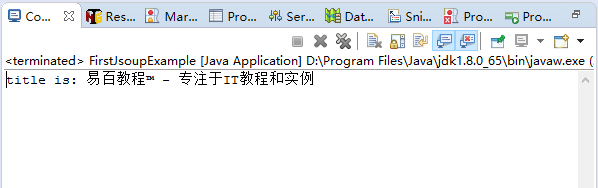
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
下一篇:JSoup快速入门
JSoup快速入门 - JSoup教程™
Jsoup是用于解析HTML,就类似XML解析器用于解析XML。 Jsoup它解析HTML成为真实世界的HTML。 它与jquery选择器的语法非常相似,并且非常灵活容易使用以获得所需的结果。 在本教程中,我们将介绍很多Jsoup的例子。
能用Jsoup实现什么?
- 从URL,文件或字符串中刮取并解析HTML
- 查找和提取数据,使用DOM遍历或CSS选择器
- 操纵HTML元素,属性和文本
- 根据安全的白名单清理用户提交的内容,以防止XSS攻击
- 输出整洁的HTML
安装-运行时依赖关系
您可以使用下面的maven依赖项将Jsoup jar包含到项目中。
<dependency>
<!-- jsoup HTML parser library @ http://jsoup.org/ -->
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
JSoup应用的主要类
虽然完整的类库中有很多类,但大多数情况下,下面给出3个类是我们需要重点了解的。
1. org.jsoup.Jsoup类
Jsoup类是任何Jsoup程序的入口点,并将提供从各种来源加载和解析HTML文档的方法。
Jsoup类的一些重要方法如下:
方法 | 描述 |
static Connection connect(String url) | 创建并返回URL的连接。 |
static Document parse(File in, String charsetName) | 将指定的字符集文件解析成文档。 |
static Document parse(String html) | 将给定的html代码解析成文档。 |
static String clean(String bodyHtml, Whitelist whitelist) | 从输入HTML返回安全的HTML,通过解析输入HTML并通过允许的标签和属性的白名单进行过滤。 |
2. org.jsoup.nodes.Document类
该类表示通过Jsoup库加载HTML文档。可以使用此类执行适用于整个HTML文档的操作。
Element类的重要方法可以参见 - http://jsoup.org/apidocs/org/jsoup/nodes/Document.html 。
3. org.jsoup.nodes.Element类
HTML元素是由标签名称,属性和子节点组成。 使用Element类,您可以提取数据,遍历节点和操作HTML。
Element类的重要方法可参见 - http://jsoup.org/apidocs/org/jsoup/nodes/Element.html 。
应用实例
现在我们来看一些使用Jsoup API处理HTML文档的例子。
1. 载入文件
从URL加载文档,使用Jsoup.connect()方法从URL加载HTML。
try
{
Document document = Jsoup.connect("http://www.yiibai.com").get();
System.out.println(document.title());
}
catch (IOException e)
{
e.printStackTrace();
}
2. 从文件加载文档
使用Jsoup.parse()方法从文件加载HTML。
try
{
Document document = Jsoup.parse( new File( "D:/temp/index.html" ) , "utf-8" );
System.out.println(document.title());
}
catch (IOException e)
{
e.printStackTrace();
}
3. 从String加载文档
使用Jsoup.parse()方法从字符串加载HTML。
try
{
String html = "<html><head><title>First parse</title></head>"
+ "<body><p>Parsed HTML into a doc.</p></body></html>";
Document document = Jsoup.parse(html);
System.out.println(document.title());
}
catch (IOException e)
{
e.printStackTrace();
}
4. 从HTML获取标题
如上图所示,调用document.title()方法获取HTML页面的标题。
try
{
Document document = Jsoup.parse( new File("C:/Users/xyz/Desktop/yiibai-index.html"), "utf-8");
System.out.println(document.title());
}
catch (IOException e)
{
e.printStackTrace();
}
5. 获取HTML页面的Fav图标
假设favicon图像将是HTML文档的<head>部分中的第一个图像,您可以使用下面的代码。
String favImage = "Not Found";
try {
Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8");
Element element = document.head().select("link[href~=.*\\.(ico|png)]").first();
if (element == null)
{
element = document.head().select("meta[itemprop=image]").first();
if (element != null)
{
favImage = element.attr("content");
}
}
else
{
favImage = element.attr("href");
}
}
catch (IOException e)
{
e.printStackTrace();
}
System.out.println(favImage);
6. 获取HTML页面中的所有链接
要获取网页中的所有链接,请使用以下代码。
try
{
Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8");
Elements links = document.select("a[href]");
for (Element link : links)
{
System.out.println("link : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
catch (IOException e)
{
e.printStackTrace();
}
7. 获取HTML页面中的所有图像
要获取网页中显示的所有图像,请使用以下代码。
try
{
Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8");
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images)
{
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
}
catch (IOException e)
{
e.printStackTrace();
}
8. 获取URL的元信息
元信息包括Google等搜索引擎用来确定网页内容的索引为目的。 它们以HTML页面的HEAD部分中的一些标签的形式存在。 要获取有关网页的元信息,请使用下面的代码。
try
{
Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai-index.html"), "utf-8");
String description = document.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords);
}
catch (IOException e)
{
e.printStackTrace();
}
9. 在HTML页面中获取表单属性
在网页中获取表单输入元素非常简单。 使用唯一ID查找FORM元素; 然后找到该表单中存在的所有INPUT元素。
Document doc = Jsoup.parse(new File("c:/temp/yiibai-index.html"),"utf-8");
Element formElement = doc.getElementById("loginForm");
Elements inputElements = formElement.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println("Param name: "+key+" \nParam value: "+value);
}
10. 更新元素的属性/内容
只要您使用上述方法找到您想要的元素; 可以使用Jsoup API来更新这些元素的属性或innerHTML。 例如,想更新文档中存在的“rel = nofollow”的所有链接。
try
{
Document document = Jsoup.parse(new File("C:/Users/zkpkhua/Desktop/yiibai.com.html"), "utf-8");
Elements links = document.select("a[href]");
links.attr("rel", "nofollow");
}
catch (IOException e)
{
e.printStackTrace();
}
10. 消除不信任的HTML(以防止XSS)
假设在应用程序中,想显示用户提交的HTML片段。 例如 用户可以在评论框中放入HTML内容。 这可能会导致非常严重的问题,如果您允许直接显示此HTML。 用户可以在其中放入一些恶意脚本,并将用户重定向到另一个脏网站。
为了清理这个HTML,Jsoup提供Jsoup.clean()方法。 此方法期望HTML格式的字符串,并将返回清洁的HTML。 要执行此任务,Jsoup使用白名单过滤器。 jsoup白名单过滤器通过解析输入HTML(在安全的沙盒环境中)工作,然后遍历解析树,只允许将已知安全的标签和属性(和值)通过清理后输出。
它不使用正则表达式,这对于此任务是不合适的。
清洁器不仅用于避免XSS,还限制了用户可以提供的元素的范围:您可以使用文本,强元素,但不能构造div或表元素。
String dirtyHTML = "<p><a href='http://www.yiibai.com/' onclick='sendCookiesToMe()'>Link</a></p>";
String cleanHTML = Jsoup.clean(dirtyHTML, Whitelist.basic());
System.out.println(cleanHTML);
执行后输出结果如下 -
<p><a href="http://www.yiibai.com/" rel="nofollow">Link</a></p>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
Jsoup API - JSoup教程™
jsoup api中有6个包提供用于开发jsoup应用程序的类和接口。
- org.jsoup
- org.jsoup.examples
- org.jsoup.helper
- org.jsoup.nodes
- org.jsoup.parser
- org.jsoup.safety
- org.jsoup.salect
以上包中有很多类。 jsoup api中的主要类如下所示:
- Jsoup
- Document
- Element
Jsoup类
org.jsoup.Jsoup类提供了连接,清理和解析HTML文档的方法。
org.jsoup.Jsoup类的重要方法如下:
方法名称 | 描述 |
static Connection connect(String url) | 创建并返回URL的连接。 |
static Document parse(File in, String charsetName) | 将指定的字符集文件解析成文档。 |
static Document parse(File in, String charsetName, String baseUri) | 将指定的字符集和baseUri文件解析成文档。 |
static Document parse(String html) | 将给定的html代码解析成文档。 |
static Document parse(String html, String baseUri) | 用baseUri将给定的html代码解析成文档。 |
static Document parse(URL url, int timeoutMillis) | 将给定的URL解析为文档。 |
static String clean(String bodyHtml, Whitelist whitelist) | 将输入HTML返回安全的HTML,通过解析输入HTML并通过允许的标签和属性的白名单进行过滤。 |
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
Jsoup应用实例 - JSoup教程™
在本篇文章中,将列出了一些常用的jsoup例子,例如获取URL或HTML文档的标题,链接,图像和元数据。
1. 获取URL的标题
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String title = doc.title();
2. 从HTML文件获取标题
Document doc = Jsoup.parse(new File("e:\\register.html"),"utf-8");//assuming register.html file in e drive
String title = doc.title();
3. 获取URL的链接
Document doc = Jsoup.connect("http://www.yiibai.com").get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
4. 获取URL的元信息
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String keywords = doc.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords);
String description = doc.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
5. 获取URL的图像
Document doc = Jsoup.connect("http://www.yiibai.com").get();
Elements images = doc.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
6. 获取表单参数
Document doc = Jsoup.parse(new File("e:\\register.html"),"utf-8");
Element loginform = doc.getElementById("registerform");
Elements inputElements = loginform.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println("Param name: "+key+" \nParam value: "+value);
}
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup API下一篇:Jsoup示例:提取给定url的标题
Jsoup示例:提取给定url的标题 - JSoup教程™
在这篇文章中,我们来演示一个打印一个url的标题的jsoup例子,例如: www.yiibai.com 。 在Jsoup.connect()方法的帮助下,将连接到给定的URL。get()方法返回Document类的对象的引用。Document类提供返回文档标题的title()方法。
如下代码实现 -
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class FirstJsoupExample{
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String title = doc.title();
System.out.println("title is: " + title);
}
}
`
执行结果 -
... ...
自已编程运行看看吧
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup应用实例下一篇:Jsoup示例:提取给定URL中的链接
Jsoup示例:提取给定URL中的链接 - JSoup教程™
在这篇文章中,我们演示如何打印给定URL中的所有链接信息。 要做到这一点,我们需要调用返回元素引用的Document类对象的select()方法。Elements类中可以使用for-each循环遍历元素。Element类提供了attr()和text()方法来返回链接的链接和对应的文本。
如下代码实现 -
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupPrintLinks {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://www.yiibai.com").get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
}
`
执行结果 -
... ...
自已编程运行看看吧
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup示例:提取给定url的标题下一篇:Jsoup示例:提取URL中的元数据
Jsoup示例:提取URL中的元数据 - JSoup教程™
在这个例子中,我们将打印一个URL的meta关键字和描述。要实现这个功能,需要调用Document类的select(),first(),get()和attr()方法。
如下代码实现 -
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class JsoupPrintMetadata {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://www.yiibai.com").get();
String keywords = doc.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords);
String description = doc.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
}
}
`
执行结果 -
... ...
自已编程运行看看吧
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup示例:提取给定URL中的链接下一篇:Jsoup示例:提取URL中的图像
Jsoup示例:提取URL中的图像 - JSoup教程™
在这个例子中,我们将提取并打印给定URL的所有图像信息。 要做到这一点,我们调用select()方法传递“"img[src~=(?i)\\.(png|jpe?g|gif)]"”正则表达式作为参数,以便它可以打印png,jpeg或gif类型的图像。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupPrintImages {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://www.yiibai.com").get();
Elements images = doc.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
}
}
`
执行结果 -
... ...
自已编程运行看看吧
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup示例:提取URL中的元数据下一篇:Jsoup示例:提取表单参数
Jsoup示例:提取表单参数 - JSoup教程™
在这个例子中,我们将提取并打印表单参数,如参数名称和参数值。 为此,我们调用Document类的getElementById()方法和Element类的getElementsByTag()方法。
创建一个HTML文件:register.html,代码如下 -
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register Please</title>
</head>
<body>
<form id="registerform" action="register.jsp" method="post">
Name:<input type="text" name="name" value="maxsu"/><br/>
Password:<input type="password" name="password" value="sj"/><br/>
Email:<input type="email" name="email" value="maxsu@gmail.com"/><br/>
<input name="submitbutton" type="submit" value="register"/>
</form>
</body>
</html>
`
创建一个Java类文件:JsoupPrintFormParameters.java,代码如下 -
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupPrintFormParameters {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("e:\\register.html"),"utf-8");
Element loginform = doc.getElementById("registerform");
Elements inputElements = loginform.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println("Param name: "+key+" \nParam value: "+value);
}
}
}
执行结果 -
Param name: name
Param value: maxsu
Param name: password
Param value: sj
Param name: email
Param value: maxsu@gmail.com
Param name: submitbutton
Param value: register
自已编程运行看看吧
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Jsoup示例:提取URL中的图像下一篇:哥,这回真没有了
