




Tutorialspoint Kafka 教程
来源:易百教程
Kafka教程™
Apache Kafka起源于LinkedIn,后来于2011年成为Apache开源项目,然后于2012年成为Apache项目的第一个类别。Kafka是使用Scala和Java编写的。 Apache Kafka是基于 - 发布订阅的容错消息系统。 它具有快速,可扩展和设计分布的特点。
本教程将探讨Kafka的原理,安装和操作,然后它将引导您完成Kafka集群的部署。 最后,我们将教程结束实时应用,并与一些大数据技术集成。
面向读者
本教程主要为有志于使用Apache Kafka消息传递系统从事大数据分析工作的专业人员来准备的。 它会让你充分了解如何使用Kafka集群。
前提条件
在继续本教程之前,您必须对Java,Scala,分布式消息传递系统和Linux环境有很好的理解。
问题反馈
我们不能保证您在学习此Kafka教程的过程中不会遇到任何问题。本教程中的讲解,示例和代码等只是根据作者的理解来概括写出。由于作者水平和能力有限,因此不保正所有编写的文章都准确无误。但是如果有遇到任何错误或问题,请反馈给我们,我们会及时纠正以方便后续读者阅读。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka简介 - Kafka教程™
在大数据中,使用了大量的数据。 关于大数据,主要有两个主要挑战。第一个挑战是如何收集大量数据,第二个挑战是分析收集的数据。 为了克服这些挑战,需要使用消息传递系统。
Kafka专为分布式高吞吐量系统而设计。 Kafka倾向于非常好地取代传统的信息中间服务者。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有容错功能,因此非常适合大型消息处理应用程序。
什么是消息系统?
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不必担心如何共享数据。 分布式消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息传递模式可用 - 一种是点对点的,另一种是发布 - 订阅(pub-sub)消息传递系统。 大多数消息传递模式遵循pub-sub。
点对点消息系统
在点对点系统中,消息被保存在一个队列中。 一个或多个消费者可以消费队列中的消息,但是特定的消息只能由最多一个消费者消费。 一旦消费者在队列中读取消息,消息就从该队列中消失。 这个系统的典型例子是一个订单处理系统,其中每个订单将由一个订单处理器处理,但是多订单处理器也可以同时工作。 下图描述了结构。
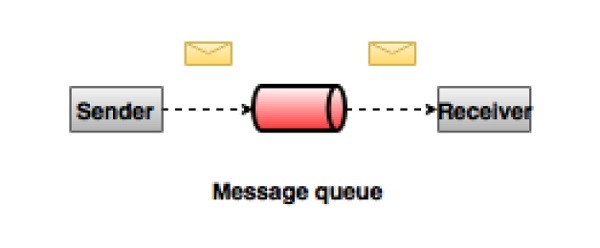
发布-订阅消息系统
在发布-订阅系统中,消息被保存在一个主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消息。 在发布-订阅系统中,消息生产者称为发布者,消息消费者称为订阅者。 一个真实的例子是Dish TV,它发布体育,电影,音乐等不同的频道,任何人都可以订阅他们自己的一套频道,并在他们的订阅频道可用时获得内容。
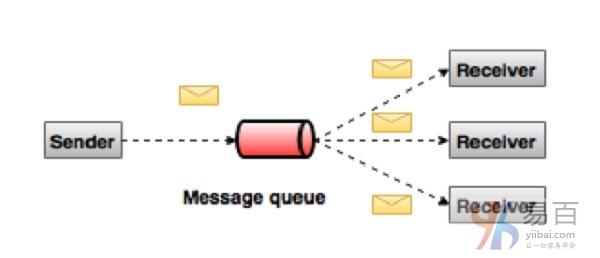
什么是Kafka?
Apache Kafka是一个分布式的发布 - 订阅消息传递系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息被保存在磁盘上并在集群内复制以防止数据丢失。 Kafka建立在ZooKeeper同步服务之上。 它与Apache Storm和Spark完美集成,用于实时流数据分析。
优点
以下是使用Kafka的一些好处(优点) -
- 可靠性 - 卡夫卡是分布式,分区,复制和容错。
- 可扩展性 - Kafka消息系统无需停机即可轻松扩展。
- 耐用性 - Kafka使用分布式提交日志,这意味着消息尽可能快地保留在磁盘上,因此它是持久的。
- 性能 - Kafka对于发布和订阅消息都有很高的吞吐量。 它保持稳定的性能,即使存储了许多TB数据量(级)的消息。
Kafka速度非常快,可确保零停机时间和零数据丢失。
用例
Kafka可用于许多用例。 其中一些列在下面 -
- 指标 - Kafka通常用于运营监控数据。 这涉及从分布式应用程序汇总统计数据以生成操作数据的集中式提要。
- 日志聚合解决方案 - Kafka可以在整个组织中使用,从多个服务中收集日志,并以标准格式向多个消费者提供。
- 流处理 - 流行的框架(如Storm和Spark Streaming)可以从主题读取数据,对其进行处理,并将处理后的数据写入新主题,以供用户和应用程序使用。 Kafka的强耐久性在流加工方面也非常有用。
Kafka是处理所有实时数据馈送的统一平台。 Kafka支持低延迟消息传送并在出现机器故障时保证容错。 它有能力处理大量不同的消费者。 Kafka速度非常快,每秒执行200万次写入。 Kafka将所有数据保留在磁盘上,这意味着所有写入都会进入操作系统(RAM)的页面缓存。 这使得从页面缓存向网络套接字传输数据非常高效。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka基本原理 - Kafka教程™
在深入学习Kafka之前,需要先了解topics, brokers, producers和consumers等几个主要术语。 下面说明了主要术语的详细描述和组件。
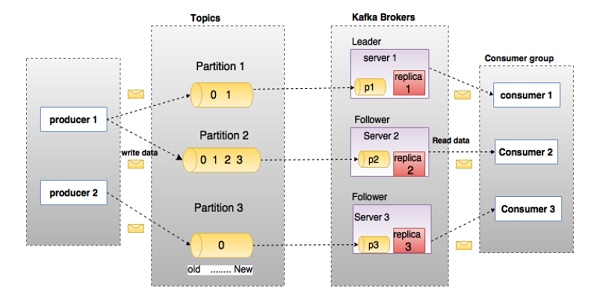
在上图中,主题(topic)被配置为三个分区。 分区1(Partition 1)具有两个偏移因子0和1。分区2(Partition 2)具有四个偏移因子0,1,2和3,分区3(Partition 3)具有一个偏移因子0。replica 的id与托管它的服务器的id相同。
假设,如果该主题的复制因子设置为3,则Kafka将为每个分区创建3个相同的副本,并将它们放入群集中以使其可用于其所有操作。 为了平衡集群中的负载,每个代理存储一个或多个这些分区。 多个生产者和消费者可以同时发布和检索消息。
- Topics - 属于特定类别的消息流被称为主题(Topics),数据存储在主题中。主题分为多个分区。 对于每个主题,Kafka都保留一个分区的最小范围。 每个这样的分区都以不可变的有序顺序包含消息。 分区被实现为一组相同大小的段文件。
- Partition - 主题可能有很多分区,所以它可以处理任意数量的数据。
- Partition offset - 每个分区消息都有一个称为偏移量的唯一序列标识。
- Replicas of partition - 副本只是分区的备份。 副本从不读取或写入数据。 它们用于防止数据丢失。
- Brokers
- 经纪人(Brokers)是简单的系统,负责维护公布的数据。 每个代理可能每个主题有零个或多个分区。 假设,如果一个主题和N个代理中有N个分区,则每个代理将有一个分区。
- 假设某个主题中有N个分区并且N个代理(n + m)多于N个,则第一个N代理将拥有一个分区,下一个M代理将不会拥有该特定主题的任何分区。
- 假设某个主题中有N个分区且N个代理(n-m)少于N个代理,则每个代理将拥有一个或多个分区共享。 由于经纪人之间的负载分配不均衡,不推荐这种情况。
- Kafka Cluster - Kafka拥有多个经纪人称为Kafka集群。 Kafka集群可以在无需停机的情况下进行扩展。 这些集群用于管理消息数据的持久性和复制。
- Producers - 生产者(Producer)是一个或多个Kafka主题的发布者。 生产者向Kafka经纪人发送数据。 每当生产者向经纪人发布消息时,经纪人只需将消息附加到最后一个段文件。 实际上,该消息将被附加到分区。 生产者也可以将消息发送到他们选择的分区。
- Consumers - 消费者从经纪人那里读取数据。 消费者通过从经纪人处获取数据来订阅一个或多个主题并消费发布的消息。
- Leader - Leader是负责所有分区读写的节点。 每个分区都有一台服务器充当领导者。
- Follower - 遵循领导者(Leader)指示的节点称为追随者(Follower)。 如果领导失败,其中一个追随者将自动成为新领导。 追随者扮演正常的消费者角色,拉动消息并更新自己的数据存储。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka群集体系结构 - Kafka教程™
有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。
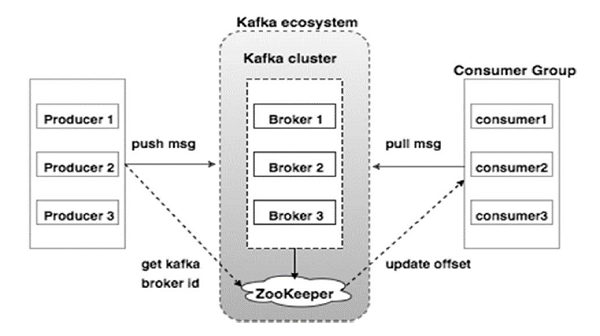
下表描述了上图中显示的每个组件。
- Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可以由ZooKeeper完成。
- ZooKeeper - ZooKeeper用于管理和协调Kafka经纪人。 ZooKeeper服务主要用于通知生产者和消费者关于Kafka系统中任何新经纪人的存在或Kafka系统中经纪人的失败。 根据Zookeeper收到的有关经纪人存在或失败的通知,生产者和消费者就会做出决定,并开始与其他经纪人协调他们的任务。
- Producers - 生产者将数据推送给经纪人。 新代理启动后,所有生产者都会搜索它并自动向该新代理发送消息。 Kafka生产者不会等待经纪人的确认,并且可以像经纪人能够处理的那样快地发送消息。
- Consumers - 由于Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移量来维护消耗了多少消息。 如果消费者确认特定的消息偏移量,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出一个异步拉取请求,以准备消耗字节缓冲区。 消费者可以简单地通过提供偏移值来倒回或跳到分区中的任何点。 消费者补偿值由ZooKeeper通知。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka工作流 - Kafka教程™
截至目前,我们已经了解了Kafka的核心概念。 现在让我们来看看Kafka的工作流程。
Kafka只是分成一个或多个分区的主题集合。 Kafka分区是消息的线性排序序列,每个消息由其索引标识(称为偏移量)。 Kafka集群中的所有数据都是不相关的分区联合。 传入消息写在分区的末尾,消费者依次读取消息。 通过将消息复制到不同的经纪人来提供持久性。
Kafka以快速,可靠,持久的容错和零停机方式提供基于发布订阅和队列的消息传递系统。 在这两种情况下,生产者只需将消息发送到一个主题,消费者就可以根据他们的需要选择任何一种消息传递系统。 可通过下一节中的步骤来了解消费者如何选择它们的消息系统。
发布订阅消息传递的工作流
以下是发布订阅消息工作流程的步骤 -
- 生产者定期向主题发送消息。
- Kafka经纪人将所有消息存储在为该特定主题配置的分区中。 它确保消息在分区之间平均分享。 如果制作者发送两条消息并且有两个分区,则Kafka将在第一个分区中存储一条消息,并在第二个分区中存储第二条消息。
- 消费者订阅特定主题。
- 当消费者订阅了一个主题,Kafka将向消费者提供该主题的当前偏移量,并且还将该偏移量保存在Zookeeper集合中。
- 消费者会定期请求Kafka(如100小时)收取新消息。
- Kafka收到生产者的消息后,会将这些消息转发给消费者。
- 消费者将收到消息并进行处理。
- 当消息被处理,消费者将向Kafka经纪人发送确认。
- Kafka收到确认后,会将偏移量更改为新值并在Zookeeper中更新它。 由于在Zookeeper中维护了偏移量,因此即使在服务器繁忙期间,使用者也可以正确读取下一条消息。
- 上述流程将重复,直到消费者停止请求。
- 消费者可以随时选择倒带/跳至期望的主题偏移量并阅读所有后续消息。
队列消息/消费者组的工作流
在队列消息系统(不是单个消费者)中,具有相同组ID的一组消费者将订阅主题。 简而言之,订阅具有相同组ID的主题的消费者被视为单个组,并且消息在他们之间共享。 让我们来看看一下这个系统的实际工作流程。
- 生产者定期向主题发送消息。
- Kafka将所有消息存储在为特定主题配置的分区中,类似于之前的场景。
- 单个消费者订阅特定主题,将Group ID设为Group-1。
- Kafka发布订阅消息与消费者进行交互,直到新消费者订阅同一主题Topic-01,其Group ID与Group-1相同。
- 一旦新消费者到达,Kafka将其操作切换到共享模式并在两个消费者之间共享数据。 这种共享将持续到用户数量达到为该特定主题配置的分区数量。
- 当消费者数量超过分区数量,新消费者将不会收到任何进一步的消息,直到现有的任何消费者退订。 这种情况的出现是因为Kafka的每个消费者都将被分配至少一个分区,并且当所有分区被分配给现有消费者,新消费者将不得不等待。
- 这个功能也被称为消费群。 以同样的方式,Kafka将以非常简单和有效的方式提供这两个系统。
ZooKeeper的角色
Apache Kafka的关键依赖是Apache Zookeeper,它是一个分布式配置和同步服务。 Zookeeper作为Kafka经纪人和消费者之间的协调接口。 Kafka服务器通过Zookeeper集群共享信息。 Kafka在Zookeeper中存储基本元数据,例如有关主题,经纪人,消费者偏移量(队列读取器)等的信息。
由于所有关键信息都存储在Zookeeper中,并且它通常在整个集群中复制这些数据,所以Kafka broker/Zookeeper的故障不会影响Kafka集群的状态。当Zookeeper重新启动,Kafka将恢复状态。 这给Kafka带来零停机时间。 Kafka经纪人之间的领导者选举也是通过在领导者失败的情况下,使用Zookeeper来完成的。
要了解Zookeeper的更多信息,请参阅zookeeper教程。
让我们继续,在下一章中学习如何安装Java,ZooKeeper和Kafka。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka环境安装配置 - Kafka教程™
以下是在您的机器上安装Java的步骤。
第1步 - Java安装
查看是否在机器上安装了java环境,只需使用下面的命令来验证它。
$ java -version
如果计算机上已成功安装Java,则可以看到已安装的Java版本。例如 -
yiibai@ubuntu:~$ java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) Client VM (build 25.65-b01, mixed mode)
yiibai@ubuntu:~$
如果没有安装好Java,那么可以参考以下步骤来安装。
Ubuntu上安装Java: https://www.yiibai.com/java/how-to-install-java-on-ubuntu.html
第2步 - ZooKeeper框架安装
步骤2.1 - 下载ZooKeeper
要在您的机器上安装ZooKeeper框架,请访问以下链接并下载最新版本的ZooKeeper。URL: http://zookeeper.apache.org/releases.html , 截至目前,ZooKeeper的最新版本是:3.4.10(ZooKeeper-3.4.10.tar.gz)。
步骤2.2 - 解压缩tar文件
使用以下命令提取tar文件
$ cd /usr/local/src
$ wget -c http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
$ tar -zxf zookeeper-3.4.10.tar.gz
$ mv zookeeper-3.4.10 /usr/local/
$ cd /usr/local/zookeeper-3.4.10
$ mkdir /usr/local/zookeeper-3.4.10/data
步骤2.3 - 创建配置文件
使用vi conf/zoo.cfg命令打开conf/zoo.cfg配置文件,并将以下参数内容写入在文件的开头。
tickTime=2000
dataDir=/usr/local/zookeeper-3.4.10/data
clientPort=2181
initLimit=5
syncLimit=2
当配置文件保存成功并再次返回到终端,可以启动zookeeper服务器。
步骤2.4 - 启动ZooKeeper服务器
$ /usr/local/zookeeper-3.4.10/bin/zkServer.sh start
执行此命令后,将得到如下所示的响应 -
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
yiibai@ubuntu:/usr/local/zookeeper-3.4.10$
步骤2.5 - 启动CLI
$ /usr/local/zookeeper-3.4.10/bin/zkCli.sh
输入上述命令后,将连接到zookeeper服务器,并获得以下响应。
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]
步骤2.6 - 停止Zookeeper服务器
连接服务器并执行所有操作后,可以使用以下命令停止zookeeper服务器 -
$ /usr/local/zookeeper-3.4.10/bin/zkServer.sh stop
经过前面的操作,现在已经在机器上成功安装了Java和ZooKeeper。 接下来看看如何来安装Apache Kafka。
第3步 - Apache Kafka安装
下面继续以下步骤来安装Kafka。
步骤3.1 - 下载Kafka
要在您的机器上安装Kafka,请点击下面的链接 -
http://mirrors.hust.edu.cn/apache/kafka/1.0.1/kafka_2.11-1.0.1.tgz
把现在最新的版本,即 - kafka_2.11_0.9.0.0.tgz 下载到您的机器上。
步骤3.2 - 提取tar文件
使用以下命令提取tar文件 -
$ cd /usr/local/src
$ wget -c http://mirrors.hust.edu.cn/apache/kafka/1.0.1/kafka_2.11-1.0.1.tgz
$ tar -zxf kafka_2.11-1.0.1.tgz
$ mv kafka_2.11-1.0.1 /usr/local/
$ cd /usr/local/kafka_2.11-1.0.1
现在已经下载并解压了最新版本的Kafka。
步骤3.3 - 启动服务器
可以通过提供以下命令启动服务器 -
注意:需要先启动 zookeeper
$ /usr/local/kafka_2.11-1.0.1/bin/kafka-server-start.sh config/server.properties
服务器启动后,会在终端上看到以下响应 -
[2018-03-12 01:43:42,213] INFO Result of znode creation is: OK (kafka.utils.ZKCheckedEphemeral)
[2018-03-12 01:43:42,223] INFO Registered broker 0 at path /brokers/ids/0 with addresses: EndPoint(ubuntu,9092,ListenerName(PLAINTEXT),PLAINTEXT) (kafka.utils.ZkUtils)
[2018-03-12 01:43:42,239] WARN No meta.properties file under dir /tmp/kafka-logs/meta.properties (kafka.server.BrokerMetadataCheckpoint)
[2018-03-12 01:43:42,323] INFO Kafka version : 1.0.1 (org.apache.kafka.common.utils.AppInfoParser)
[2018-03-12 01:43:42,326] INFO Kafka commitId : c0518aa65f25317e (org.apache.kafka.common.utils.AppInfoParser)
[2018-03-12 01:43:42,330] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
…………………………………………….
…………………………………………….
第4步 - 停止服务器
执行所有操作后,可以使用以下命令停止服务器 -
$ bin/kafka-server-stop.sh config/server.properties
通过前面的步骤和操作,我们已经安装好了Kafka,在下一章中将学习如何在Kafka上执行基本操作。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka简单的生产者例子 - Kafka教程™
在这一节中将创建一个使用Java客户端发布和使用消息的应用程序。 Kafka生产者客户端由以下API组成。
KafkaProducer API
下面来了解Kafka生产者API。 KafkaProducer API的核心部分是KafkaProducer类。 KafkaProducer类提供了一个选项,用于将Kafka代理的构造函数与以下方法连接起来。
- KafkaProducer类提供send()方法来异步发送消息到主题。 send()的签名如下 -
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
- ProducerRecord - 生产者管理等待发送的记录缓冲区。
- Callback - 服务器确认记录时执行的用户提供的回调函数(null表示无回调)。
- KafkaProducer类提供了一个flush方法来确保所有先前发送的消息已经实际完成。 flush方法的语法如下 -
public void flush()
- KafkaProducer类提供了partitionFor方法,该方法有助于获取给定主题的分区元数据。 这可以用于自定义分区。 这种方法的签名如下 -
public Map metrics()
它返回生产者维护的内部度量图。
- public void close() - KafkaProducer类提供close方法,阻塞直到完成所有先前发送的请求。
生产者API
Producer API的核心部分是Producer类。 Producer类提供了一个选项,通过以下方法在其构造函数中连接Kafka代理。
Producer类
Producer类提供send方法,使用以下签名将消息发送到单个或多个主题。
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);
有两种类型的生产者 - 同步和异步。
同样的API配置也适用于Sync生产者。 它们之间的区别是同步生产者直接发送消息,但在后台发送消息。 当想要更高的吞吐量时,首选异步生产者。 在0.8之前的版本中,异步生产者没有回调send()来注册错误处理程序。异步生产者仅在当前版本0.9中可用。
public void close()
Producer类提供close()方法来关闭所有Kafka 经纪人的生产者池连接。
配置设置
Producer API的主要配置设置在下表中列出以便更好地理解 -
编号 | 配置设置 | 描述 |
1 | client.id | 确定生产者应用 |
2 | producer.type | 是同步还是异步? |
3 | acks | acks配置控制生产者请求下的标准被认为是完整的。 |
4 | retries | 如果生产者请求失败,则自动重试具有特定的值。 |
5 | bootstrap.servers | 引导经纪人(brokers)列表。 |
6 | linger.ms | 如果想减少请求的数量,可以将linger.ms设置为大于某个值的值。 |
7 | key.serializer | 序列化器接口的键。 |
8 | value.serializer | 序列化器接口的值。 |
9 | batch.size | 缓冲区大小。 |
10 | buffer.memory | 控制生产者可用于缓冲的总内存量。 |
ProducerRecord API
ProducerRecord是发送给Kafka的cluster.ProducerRecord类的键/值对,用于使用以下签名创建包含分区,键和值对的记录。
public ProducerRecord (string topic, int partition, k key, v value)
- topic − 用户定义的主题名称将要追加到记录中。
- partition − 分区计数
- key − 记录中将包含的关键字。
- value − 记录内容
public ProducerRecord (string topic, k key, v value)
ProducerRecord类构造函数用于创建一个记录,其中包含键值对,但没有分区。
- topic − 创建一个分配记录的主题。
- partition − 分区计数
- key − 记录中将包含的关键字。
- value − 记录内容
public ProducerRecord (string topic, v value)
ProducerRecord类创建没有分区和键的记录。
- topic − 创建一个分配记录的主题。
- value − 记录内容
下表中列出了ProducerRecord类的方法 -
编号 | 方法 | 描述 |
1 | public string topic() | 将附加到记录的主题。 |
2 | public K key() | 将包含在记录中的键。 如果没有这样的键,返回null。 |
3 | public V value() | 记录的内容。 |
4 | partition() | 记录的分区计数 |
SimpleProducer应用程序
在创建应用程序之前,首先启动ZooKeeper和Kafka代理,然后使用create topic命令在Kafka代理中创建自己的主题。 之后,创建一个SimpleProducer.java的Java类并输入以下编码。
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}
编译 - 可以使用以下命令编译应用程序 -
$ javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
执行 - 可以使用以下命令执行应用程序。
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>
执行上面示例代码,得到以下结果 -
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10
简单的消费者实例
截至目前,已经创建了一个生产者并向Kafka集群发送消息。 现在,创建一个消费者来使用来自Kafka集群的消息。 KafkaConsumer API用于消费来自Kafka集群的消息。 下面定义了KafkaConsumer类的构造函数。
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
- configs - 返回消费者配置的映射。
KafkaConsumer类具有下表中列出的方法。
编号 | 方法 | 描述 |
1 | public java.util.Set<TopicPar-tition> assignment() | 获取消费者当前分配的一组分区。 |
2 | public string subscription() | 订阅给定的主题列表以获取动态签署的分区。 |
3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) | 订阅给定的主题列表以获取动态签署的分区。 |
4 | public void unsubscribe() | 取消订阅给定分区列表中的主题。 |
5 | public void sub-scribe(java.util.List<java.lang.String> topics) | 订阅给定的主题列表以获取动态签署的分区。 如果给定的主题列表为空,则将其视为与unsubscribe()相同。 |
6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) | 参数(pattern)以正则表达式的格式引用订阅模式,而参数listener从订阅模式中获取通知。 |
7 | public void as-sign(java.util.List<TopicParti-tion> partitions) | 手动将分区列表分配给客户。 |
8 | poll() | 获取使用其中一个订阅/分配API指定的主题或分区的数据。 如果在轮询数据之前没有订阅主题,这将返回错误。 |
9 | public void commitSync() | 提交最后一次由poll()返回的主题和分区的所有sub-scribed列表的偏移量。 同样的操作应用于commitAsyn()。 |
10 | public void seek(TopicPartition partition, long offset) | 获取消费者将在下一个poll()方法中使用的当前偏移值。 |
11 | public void resume() | 恢复暂停的分区。 |
12 | public void wakeup() | 唤醒消费者。 |
ConsumerRecord API
ConsumerRecord API用于接收来自Kafka集群的记录。 该API由主题名称,分区编号以及指向Kafka分区中记录的偏移量组成。 ConsumerRecord类用于创建具有特定主题名称,分区计数和<key,value>对的消费者记录。 它有以下签名。
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
参数 -
- topic - 从Kafka集群收到的消费者记录的主题名称。
- partition - 主题的分区。
- key - 记录的关键字,如果不存在关键字,则将返回null。
- value - 记录内容。
ConsumerRecords API
ConsumerRecords API充当ConsumerRecord的容器。 此API用于保留特定主题的每个分区的ConsumerRecord列表。 它的构造函数定义如下。
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)
参数
- TopicPartition - 返回特定主题的分区映射。
- records - ConsumerRecord的返回列表。
ConsumerRecords类中定义了以下方法。
编号 | 方法 | 描述 |
1 | public int count() | 所有主题的记录数。 |
2 | public Set partitions() | 该记录集中包含数据的分区集(如果没有数据返回,则该集为空)。 |
3 | public Iterator iterator() | 迭代器能够遍历集合,获取或重新移动元素。 |
4 | public List records() | 获取给定分区的记录列表。 |
配置设置
以下列出了Consumer客户端API主配置设置的配置设置 -
编号 | 设置 | 描述 |
1 | bootstrap.servers | 经纪人的引导列表。 |
2 | group.id | 将个人消费者分配给组。 |
3 | enable.auto.commit | 如果值为true,则为偏移启用自动提交,否则不提交。 |
4 | auto.commit.interval.ms | 返回更新的消耗偏移量被写入ZooKeeper的频率。 |
5 | session.timeout.ms | 指示在放弃并继续使用消息之前,Kafka将等待多少毫秒以等待ZooKeeper响应请求(读取或写入)。 |
SimpleConsumer应用程序
生产者申请步骤在这里保持不变。 首先,启动ZooKeeper和Kafka经纪人。 然后使用SimpleConsumer.java的Java类创建一个SimpleConsumer应用程序并键入以下代码。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}
编译 - 可以使用以下命令编译应用程序。
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
执行 - 可以使用以下命令执行应用程序 -
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>
输入 - 打开生产者CLI并发送一些消息给主题。输入如'Hello Consumer'。得到以类似以下结果 -
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello Consumer
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka费者群组示例 - Kafka教程™
消费者群组是来自Kafka主题的多线程或多机器消费。
消费者群组
消费者可以通过使用samegroup.id加入一个组。
- 一个组的最大并行度是该组中的消费者的数量 ← 分区的数量。
- Kafka将一个主题的分区分配给组中的使用者,以便每个分区仅由组中的一位消费者使用。
- Kafka保证只有群组中的单个消费者阅读消息。
- 消费者可以按照存储在日志中的顺序查看消息。
重新平衡消费者
添加更多流程/线程将导致Kafka重新平衡。 如果任何消费者或经纪商未能向ZooKeeper发送心跳,则可以通过Kafka集群重新配置它。 在这种重新平衡期间,Kafka会将可用分区分配给可用线程,可能会将分区移至另一个进程。
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}
编译
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
执行代码
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
在这里,创建了一个样本组名称作为my-group与两个消费者。 同样,可以在组中创建组和消费者数量。
输入
打开生产者CLI并发送一些消息,如 -
Test consumer group 01
Test consumer group 02
第一个过程的输出 -
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01
第二个过程的输出 -
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02
现在希望能通过使用Java客户端演示了解SimpleConsumer和ConsumeGroup。 现在已经了解了如何使用Java客户端发送和接收消息。 在下一章继续 Kafka 与一些大数据技术的整合。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka与Storm整合 - Kafka教程™
在本章中,我们将学习如何将Kafka与Apache Storm集成。
Storm是什么?
Storm最初是由Nathan Marz和BackType团队创建的。 在很短的时间内,Apache Storm成为分布式实时处理系统的标准,用于处理大数据。 Storm速度非常快,每个节点每秒处理超过一百万个元组的基准时钟。 Apache Storm持续运行,从配置的源(Spouts)中消耗数据并将数据传递到处理管道(Bolts)。 组合 Spouts 和 Bolts 构成一个拓扑。
与Storm整合
Kafka和Storm自然而然地相互补充,它们强大的合作能够实现快速移动大数据的实时流式分析。 Kafka和Storm的整合使得开发者更容易从Storm拓扑中获取和发布数据流。
概念流程
喷口(spout)是流的来源。 例如,spout可能会读取卡夫卡主题中的元组并将其作为流发送。 Bolts消耗输入流,处理并可能发射新的流。 Bolts可以做任何事情,从运行功能,过滤元组,流聚合,流式连接,与数据库交互等等。 Storm拓扑中的每个节点并行执行。 一个拓扑无限期地运行,直到终止它。 Storm会自动重新分配任何失败的任务。 此外,即使机器停机并且信息丢失,Storm也可以保证不会丢失数据。
下面来看看Kafka-Storm集成API。 有三个主要类将Kafka和Storm结合在一起。 他们如下 -
BrokerHosts - ZkHosts&StaticHosts
BrokerHosts是一个接口,ZkHosts和StaticHosts是它的两个主要实现。 ZkHosts用于通过在ZooKeeper中维护详细信息来动态跟踪Kafka经纪人,而StaticHosts用于手动/静态设置Kafka经纪人及其详细信息。 ZkHosts是访问Kafka经纪人的简单而快捷的方式。
ZkHosts的签名如下 -
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)
其中brokerZkStr是ZooKeeper主机,brokerZkPath是维护Kafka代理细节的ZooKeeper路径。
public KafkaConfig(BrokerHosts hosts, string topic)
参数
- hosts - BrokerHosts可以是ZkHosts / StaticHosts。
- topic - 主题名称。
SpoutConfig API
Spoutconfig是KafkaConfig的扩展,支持额外的ZooKeeper信息。
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)
参数
- hosts - BrokerHosts可以是BrokerHosts接口的任何实现
- topic - 主题名称。
- zkRoot - ZooKeeper根路径。
- id - spout存储在Zookeeper中消耗的偏移量的状态。该ID应该唯一标识的spout。
SchemeAsMultiScheme
SchemeAsMultiScheme是一个接口,它规定了从Kafka消耗的ByteBuffer如何转换为 storm 元组。它来自MultiScheme并接受Scheme类的实现。Scheme类有很多实现,一个这样的实现是StringScheme,它将字节解析为一个简单的字符串。 它还控制输出字段的命名。 签名定义如下。
public SchemeAsMultiScheme(Scheme scheme)
参数
- scheme - 从kafka消耗的字节缓冲区。
KafkaSpout API
KafkaSpout是spout实现,它将与Storm整合。 它从kafka主题获取消息并将其作为元组发送到Storm生态系统中。 KafkaSpout从SpoutConfig获取配置细节。
以下是创建一个简单的kafka spout的示例代码。
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
Bolt创建
Bolt是一个将元组作为输入,处理元组并生成新的元组作为输出的组件。 Bolts将实现IRichBolt接口。 在这个程序中,使用两个类 - WordSplitter-Bolt和WordCounterBolt来执行操作。
IRichBolt接口有以下方法 -
- prepare - 为 bolt 提供执行的环境。 执行者将运行此方法来初始化spout。
- prepare - 处理输入的单个元组。
- prepare - 当bolt即将关闭时调用。
- declareOutputFields - 声明元组的输出模式。
下面创建一个Java文件:SplitBolt.java,它实现了将句子分成单词;CountBolt.java它实现了逻辑来分离唯一的单词并计算它的出现次数。
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
文件:CountBolt.java -
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
提交到拓扑
Storm拓扑基本上是一个Thrift结构。 TopologyBuilder类提供了简单而简单的方法来创建复杂的拓扑。 TopologyBuilder类具有设置spout (setSpout)和设置bolt(setBolt)的方法。 最后,TopologyBuilder使用createTopology()来创建拓朴学。 shuffleGrouping和fieldsGrouping方法有助于设置spout和bolt的流分组。
本地群集 - 出于开发目的,我们可以使用LocalCluster对象创建本地群集,然后使用LocalCluster类的submitTopology方法提交拓扑。
文件:KafkaStormSample.java -
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}
在移动编译之前,Kakfa-Storm集成需要馆长ZooKeeper客户端java库。 ZooKeeper 版本2.9.1支持Apache Storm 0.9.5版本(在本教程中使用)。 下载下面指定的jar文件并将其放在java类路径中。
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
在包含依赖文件后,使用以下命令编译程序,
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.java
执行
启动Kafka Producer CLI(在上一章中介绍),创建一个名为my-first-topic的新主题,并提供一些示例消息,如下所示 -
hello
kafka
storm
spark
test message
another test message
现在使用以下命令执行应用程序 -
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSample
此应用程序的输出示例如下所示 -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka与Spark整合 - Kafka教程™
在本章中,将讨论如何将Apache Kafka与Spark Streaming API集成。
Spark是什么?
Spark Streaming API支持实时数据流的可扩展,高吞吐量,容错流处理。 数据可以从Kafka,Flume,Twitter等许多来源获取,并且可以使用复杂算法进行处理,例如:映射,缩小,连接和窗口等高级功能。 最后,处理后的数据可以推送到文件系统,数据库和现场仪表板上。 弹性分布式数据集(RDD)是Spark的基础数据结构。 它是一个不可变的分布式对象集合。 RDD中的每个数据集都被划分为逻辑分区,这些分区可以在集群的不同节点上进行计算。
与Spark整合
Kafka是Spark流媒体的潜在消息传递和集成平台。 Kafka充当实时数据流的中心枢纽,并使用Spark Streaming中的复杂算法进行处理。 数据处理完成后,Spark Streaming可以将结果发布到HDFS,数据库或仪表板中的另一个Kafka主题中。 下图描述了概念流程。
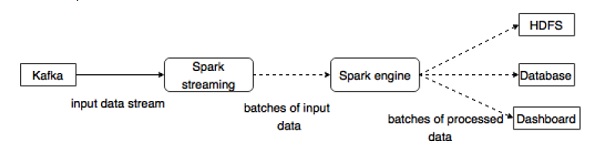
现在,详细介绍一下Kafka-Spark API。
SparkConf API
它代表Spark应用程序的配置。 用于将各种Spark参数设置为键值对。
SparkConf类具有以下方法 -
- set(string key, string value) − 设置配置变量。
- remove(string key) − 从配置中删除键。
- setAppName(string name) − 为应用程序设置应用程序名称。
- get(string key) − 获得键。
StreamingContext API
这是Spark功能的主要入口点。 SparkContext表示与Spark群集的连接,并且可用于在群集上创建RDD,累加器和广播变量。 签名的定义如下所示。
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)
- master - 要连接的群集URL(例如,mesos://host:port,spark://host:port,local [4])。
- appName - 作业的名称,以显示在集群Web UI上。
- batchDuration - 流数据将被分成批次的时间间隔。
public StreamingContext(SparkConf conf, Duration batchDuration)
通过提供新的SparkContext所需的配置来创建StreamingContext。
- conf - Spark参数。
- batchDuration - 流数据将被分成批次的时间间隔。
KafkaUtils API
KafkaUtils API用于将Kafka集群连接到Spark流。 该API具有如下定义的重要方法createStream签名。
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
上面显示的方法用于创建从Kafka Brokers中提取消息的输入流。
- ssc - StreamingContext对象。
- zkQuorum - Zookeeper仲裁。
- groupId - 此消费者的组ID。
- topics - 返回要消费的主题地图。
- storageLevel - 用于存储接收对象的存储级别。
KafkaUtils API还有另一种方法createDirectStream,它用于创建一个输入流,直接从Kafka Brokers中提取消息而不使用任何接收器。 此流可以保证来自Kafka的每条消息都只包含在一次转换中。
示例应用程序在Scala中完成。 要编译应用程序,请下载并安装sbt,scala构建工具(与maven类似)。 主应用程序代码如下所示。
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
构建脚本
spark-kafka集成取决于spark,spark流和spark Kafka集成jar。 创建一个新的文件build.sbt并指定应用程序的详细信息及其依赖关系。 sbt将在编译和打包应用程序时下载必要的jar。
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
编译/包
运行以下命令来编译和打包应用程序的jar文件。 需要将jar文件提交到spark控制台来运行应用程序。
sbt package
提交给Spark
启动Kafka Producer CLI(在前一章中介绍),创建一个名称为my-first-topic的新主题,并提供一些示例消息,如下所示。
Another spark test message
运行以下命令将应用程序提交到 spark 控制台。
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
这个应用程序的输出示例如下所示。
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka工具 - Kafka教程™
Kafka工具包装在org.apache.kafka.tools.*下。 工具分为系统工具和复制工具。
系统工具
系统工具可以使用run class脚本从命令行运行。 语法如下 -
bin/kafka-run-class.sh package.class -- options
下面提到了一些系统工具 -
- Kafka迁移工具 - 此工具用于将代理从一个版本迁移到另一个版本。
- Mirror Maker - 此工具用于将一个Kafka集群镜像到另一个。
- 消费者偏移量检查器 - 此工具显示指定的一组主题和使用者组的消费者组,主题,分区,偏移量,日志大小,所有者。
复制工具
Kafka复制是一个高层次的设计工具。 添加复制工具的目的是提供更强的耐用性和更高的可用性。 下面提到了一些复制工具 -
- 创建主题工具 - 这会创建一个包含默认分区数量,复制因子的主题,并使用Kafka的默认方案执行副本分配。
- 列表主题工具 - 此工具列出给定主题列表的信息。 如果在命令行中没有提供主题,该工具将查询Zookeeper以获取所有主题并列出它们的信息。 该工具显示的字段是主题名称,分区,领导,副本,isr。
- 添加分区工具 - 创建主题时,必须指定主题的分区数量。 稍后,当话题量增加时,话题可能需要更多的分区。 此工具有助于为特定主题添加更多分区,还可以手动添加分区的副本分配。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
Kafka应用 - Kafka教程™
Kafka支持许多最好的工业应用。 在本章中,我们将简要介绍一些Kafka最显着的应用。
推特
Twitter是一种在线社交网络服务,提供发送和接收用户推文的平台。 注册用户可以阅读和发布推文,但未注册的用户只能阅读推文。 Twitter使用Storm-Kafka作为其流处理基础设施的一部分。
在LinkedIn上使用Apache Kafka来获取活动流数据和运营指标。 Kafka消息传递系统可以为LinkedIn提供LinkedIn Newsfeed,LinkedIn Today等在线消息消费以及除Hadoop等离线分析系统之外的各种产品。 Kafka的强大耐用性也是与LinkedIn相关的关键因素之一。
Netflix公司
Netflix是美国的按需互联网流媒体跨国提供商。 Netflix使用Kafka进行实时监控和事件处理。
Mozilla
Mozilla是一个自由软件社区,由Netscape成员于1998年创建。 Kafka即将取代Mozilla当前的生产系统的一部分,以收集最终用户的浏览器的性能和使用数据,用于诸如遥测,测试引导等项目。
Oracle
Oracle通过名为OSB(Oracle Service Bus)的企业服务总线产品为Kafka提供本地连接,该产品允许开发人员利用OSB内置中介功能来实现分阶段数据管道。
易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。
