






导读:慧经营是一款数据分析产品,主要提供经营分析、运营分析、应收对账三大功能,面向企业的经营、运营、财务三个角色。可以根据客户需求提供经营分析、报表生成、账单汇总等多项数据分析服务,以帮助客户更好地经营店铺。本文将分享慧经营从 ClickHouse 到 Apache Doris 的架构演进之路,并将其在资源隔离、高并发等场景上的探索进行了经验总结,通过本文分享给大家。
慧策(原旺店通)是一家技术驱动型智能零售服务商,基于云计算 PaaS、SaaS 模式,以一体化智能零售解决方案,帮助零售企业数字化智能化升级,实现企业规模化发展。凭借技术、产品、服务优势,慧策现已成为行业影响力品牌并被零售企业广泛认可。2021年7月,慧策完成最新一轮 D 轮 3.12 亿美元的融资,累计完成四轮逾 4.52 亿美元的融资,与诸多国际一流企业、行业头部企业并列而行,被全球顶尖投资公司看好。
业务需求
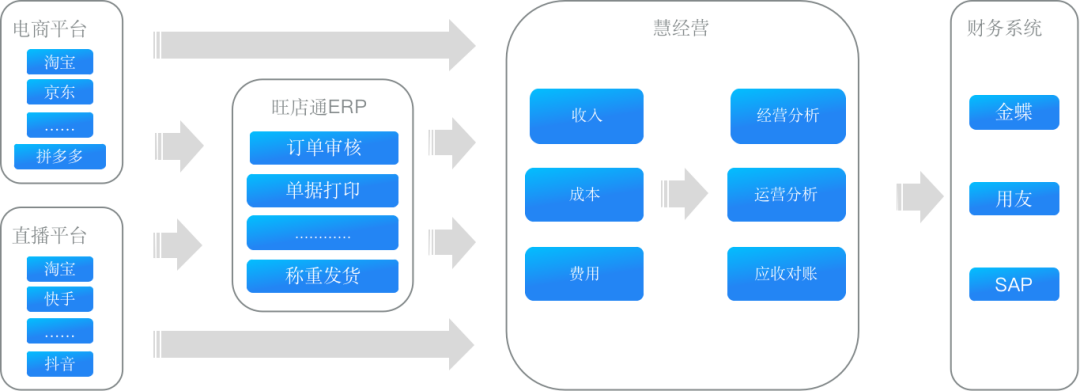
低成本:慧经营的付费模式为按需付费,这要求架构必须具有轻量化、易维护的特性。基于这点考虑,首先排除基于 Hadoop 的生态架构,虽然 Hadoop 足够成熟,但是组件依赖度较高、繁琐复杂,无论是运维成本还是使用成本都非常高。 高性能:电商数据为慧经营的主要数据来源,数据维度丰富, ETL 复杂度高;另外,在很多使用场景中明细查询与聚合查询是并存的,既需要够快速定位数据范围,又需要高效的计算能力,因此需要一个强大的 OLAP 引擎来支撑。
合理资源分配:客户规模差异较大,有月单量只有 1 万的小客户,也有月单量高达千万级别的大客户,资源合理分配在这样的场景下异常重要,因此要求 OLAP 引擎可以在不影响用户体验的前提下,可以根据客户的需求进行资源分配,避免大小查询资源抢占带来的性能问题。
高并发:能够承受上游平台多来源、高并发的大量数据的复杂 ETL,尤其在 618、双 11 这样的业务高峰期,需要具备高效查询能力的同时,能够承担大量的写入负载。
架构演进
架构 1.0
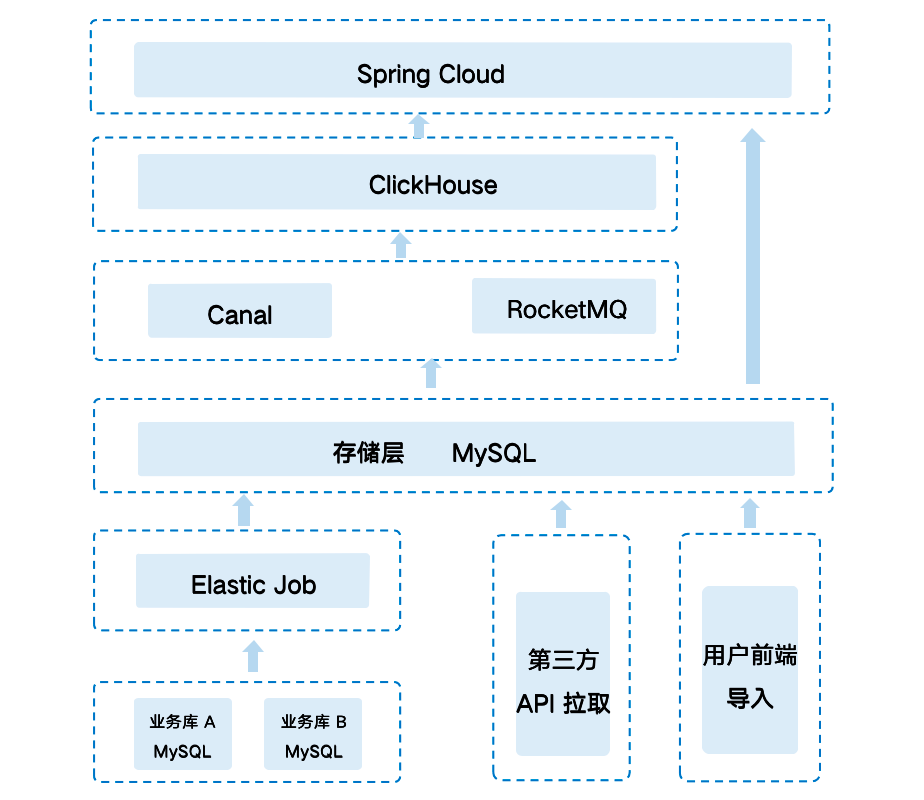
不支持高并发,即使一个查询也会用服务器一半的 CPU。对于三副本的集群,通常会将 QPS 控制在 100 以下。 ClickHouse 的扩容缩容复杂且繁琐,目前做不到自动在线操作,需要自研工具支持。 ClickHouse 的 ReplacingMergeTree 模型必须添加 final 关键字才能保证严格的唯一性,而设置为 final 后性能会急剧下降。
架构 2.0
使用成本低:只有 FE 和 BE 两类进程,部署简单,支持弹性扩缩容,不依赖其他组件,运维成本非常低;同时兼容 MySQL协议 和标准 SQL,开发人员学习难度小,项目整体迁移使用成本也比较低。 Join 性能优异:项目存在很多历史慢 SQL ,均为多张大表 Join,Apache Doris 良好的 Join 性能给我们提供了一段优化改造的缓冲期。 社区活跃度高:社区技术氛围浓厚,且 SelectDB 针对社区有专职的技术支持团队,在使用过程中遇到问题均能快速得到响应解决。
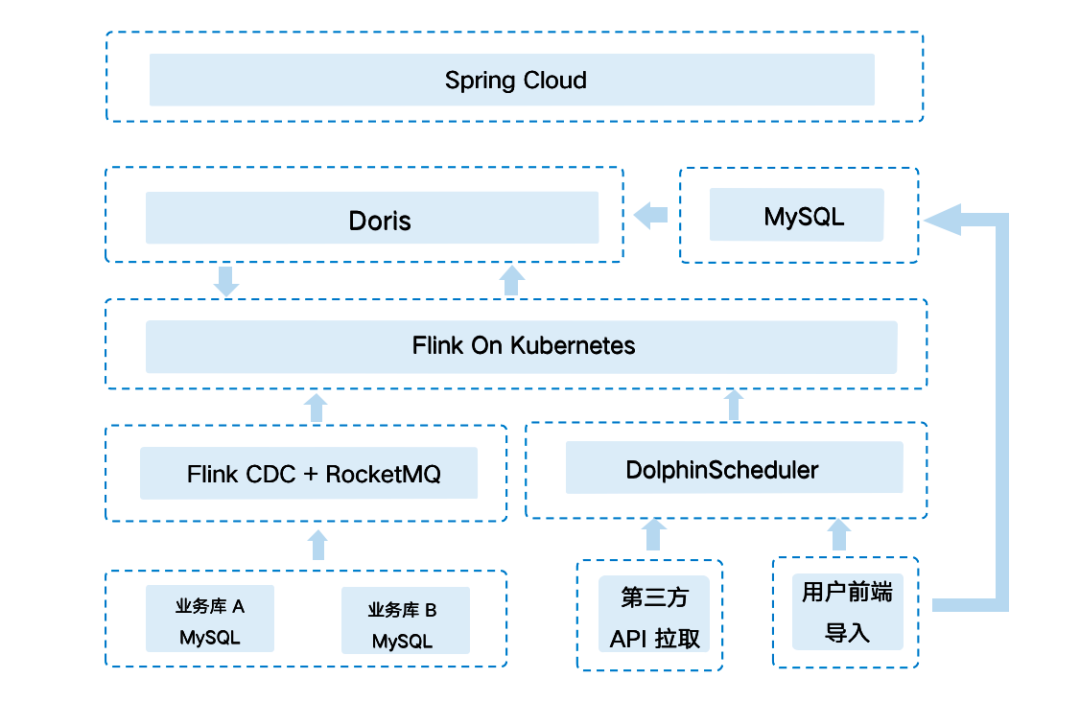
ETL 效率极大提升:慧经营的数据维度丰富、 ETL 复杂度高,得益于 Apache Doris 强大的运算能力及丰富的数据模型,将 ETL 过程放在 Doris 内部进行后效率得到了显著提升; Join 耗时大幅降低:查询性能同样得到极大提升,在 SQL 未经过改造的情况下,多表 Join 查询耗时相较于过去有了大幅降低。 并发表现出色:在业务查询高峰期可达数千 QPS,而 Apache Doris 面对高并发查询时始终表现平稳; 存储空间节省:Apache Doris 的列式存储引擎实现了最高 1:10 的数据压缩率,使得存储成本得到有效降低。 运维便捷:Apache Doris 架构简单、运维成本低,扩容升级也非常方便,我们前后对 Doris 进行了 3 次升级扩容,基本都在很短的时间内完成。
实践应用
分区分桶优化
在执行 SQL 时,SQL 的资源占用和分区分桶的大小有着密切的关系,合理的分区分桶将有效提升资源的利用率,同时避免因资源抢占带来的性能下降。
CREATE TABLE DWD_ORDER_... (
...)
...
PARTITION BY RANGE(tenant,business_date)
(
PARTITION p1_2022_01_01 VALUES [("1", '2022- 01- 01'), ("1", '2023- 01- 01')),
PARTITION p2_2022_01_01 VALUES [("2", '2022- 01- 01'), ("2", '2022- 07- 01')),
PARTITION p3_2022_01_01 VALUES [("3", '2022- 01- 01'), ("3", '2022- 04- 01')),
PARTITION p4_2022_01_01 VALUES [("4", '2022- 01- 01'), ("4", '2022- 02- 01')),
...
)
多租户和资源隔离方案
在 SaaS 业务场景中,多租户和资源划分是架构设计过程中必不可少的部分。多租户(Multi-Tenancy )指的是单个集群可以为多个不同租户提供服务,并且仍可确保各租户间数据隔离性。通过多租户可以保证系统共性的部分被共享,个性的部分被单独隔离。
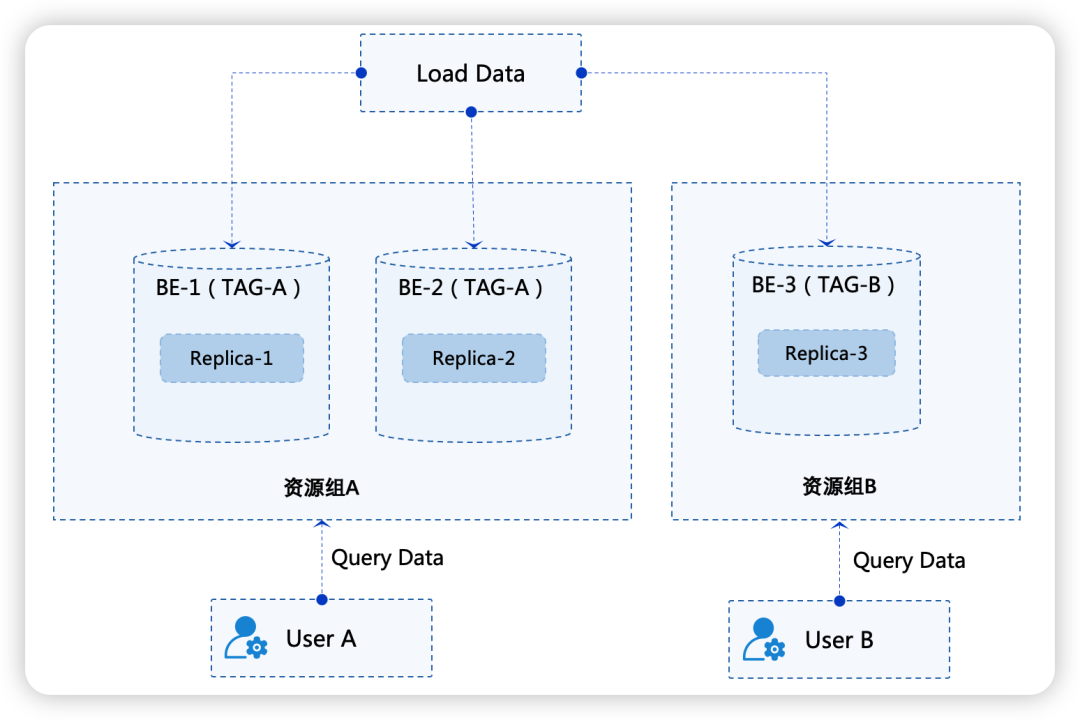
host[1-3]。在初始情况下,所有节点都属于一个默认资源组(Default)。
group_b:
alter system modify backend "host1:9050" set ("tag.location" = "group_a");
alter system modify backend "host2:9050" set ("tag.location" = "group_a");
alter system modify backend "host3:9050" set ("tag.location" = "group_b");
host[1-2] 组成资源组
group_a,
host[3]组成资源组
group_b。
create table UserTable (k1 int, k2 int)
distributed by hash(k1) buckets 1
properties(
"replication_allocation"="tag.location.group_a:2, tag.location.group_b:1"
)
set property for 'user_a' 'resource_tags.location' = 'group_a';
set property for 'user_b' 'resource_tags.location' = 'group_b';
这里将user_a和group_a 资源绑定,user_b 和 group_b 资源绑定。绑定完成后,user_a 在发起对 UserTable 表的查询时,只会访问 group_a 资源组内节点上的数据副本,并且查询仅会使用 group_a 资源组内的节点计算资源。
高并发场景的支持
高并发也通常是 SaaS 服务场景面临的挑战,一方面是慧经营已经为众多客户提供了分析服务,需要去同时承载大规模客户的并发查询和访问,另一方面,在每日早晚业务高峰期也会面临更多客户的同时在线,通常 QPS 最高可达数千,而这也是 Apache Doris 表现得非常出色的地方。在上游 Flink 高频写入的同时,Apache Doris 表现极为平稳,随着查询并发的提升,查询耗时相较于平时几乎没有太大的波动。
数据生命周期管理
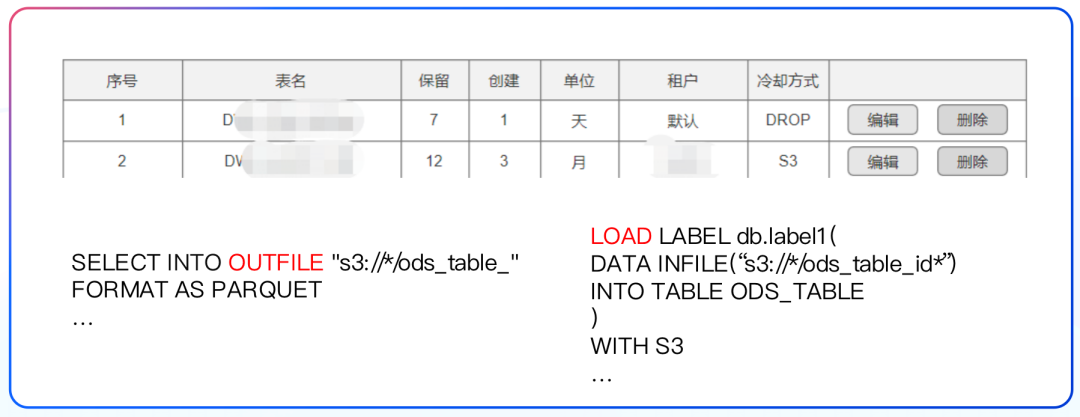
总结规划
目前正在强化 Apache Doris 的元数据管理建设,我们希望通过该服务能更好的协助开发人员使用 Doris,包括数据血缘追踪等;
尝试使用更多 Apache Doris 的新功能,在 1.2.0 版本中新增的 Java UDF 功能可以极大降低数据出入库的频率,更便捷地在 Doris 内部进行数据 ETL,这一功能我们正在尝试使用中;
探索更好的资源分配方案,包括 SQL 代理以及尝试 Doris 后续提供的 Spill 功能,以更好进行资源分配应用。
最后,再次感谢 Apache Doris 社区和 SelectDB 技术团队在我们使用过程中提供的许多指导和帮助,提出问题都会及时的响应并尽快协助解决,未来我们也希望深度参与到社区建设中,为社区的发展出一份力。
# 相关链接:
SelectDB 官网:
Apache Doris 官网:
Apache Doris Github:
欢迎更多的开源技术爱好者加入 Apache Doris 社区交流群,携手成长,共建社区生态。Apache Doris 社区当前已容纳了上万名开发者和使用者,承载了 30+ 交流社群,如果你也是 Apache Doris 的爱好者,非常欢迎您的加入!

