




<<PostgreSQL 14 Internals>>是由Egor Rogov从俄文翻译的电子书,可以从下面的网址下载PDF文件:
https://postgrespro.com/community/books/internals
最近利用周末时间在14内幕的电子书里挖呀挖,挖出一些新知识,并分享收获的花。
好词好句
-
tuple: row version
-
全局对象存储在一个oid为0的database中。
-
系统表列名前三个字母通常为表的缩写,一般把oid作为主键。
-
pg_class最初叫pg_relation,受面向对象概念的影响,重命名为class,但列名仍然延续relation,使用rel前缀。
-
pg里提供了如下预定义的schema: public、pg_catalog、information_schema、pg_toast、pg_temp
-
segments: 为了兼容不同文件系统对大文件的支持情况,按1GB进行分割。
-
分支文件: vm文件对每个page使用两个bit进行标识,一个可用与index-only,一个用于frozen。
TOAST
TOAST: (The Oversized Attributes Storage Technique):
-
TOAST表是隐藏的
-
page设计至少存四个rows,每个row大约不能超过大约2k(表级toast_tuple_target存储过程)
-
建表时可以设置四几种TOAST策略: plain/extend(先压缩再行外存储)/external(直接外部存储)/main(长字段先压缩,如果压缩后放不下,再行外存储)
-
TOAST的处理过程:首先对external和extend策略最长的字段进行TOAST处理,第一次TOAST后还不能适配到一个page,则继续对其他external和extend策略的字段逐个使用external或extend策略转移到TOAST表。如果还不行,则对main策略的字段进行压缩处理,尝试直接放到table的page里,如果还是不能存放,则main策略的字段直接存到TOAST表。
-
索引的TOAST只支持压缩(索引行头不包含xmin和xmax字段),toast表不支持二级toast
-
TOAST表只做insert或delete,没有update
-
如果update不影响存储在TOAST中的任何长值,则表的新元组将引用现有的TOAST值,只有长值发生真实更新时,才会产生新元组和新的TOAST值
-
访问长属性时,PG自动恢复原始值并返回客户端(explain的seralize选项可展示de-toast过程),因此长属性不参与查询就不需要读取TOAST表,这就是为什么在生产解决方案中应避免使用*的原因之一。
后台进程
backgroud后台进程,有一些是运行一次后结束,例如startup故障恢复进程。有一些进程是一直运行着,有一些是可以关闭,例如日志进程或autovacuum进程。
MVCC
BEGIN ISOLATION LEVEL SERIALIZABLE READ ONLY DEFERRABLE;
即便以只读的方式去执行运行时间非常长的一些报表查询,也可能和之前已经开启并正在执行的其他串行事务产生干扰,从而导致其他串行事务需要回滚。
因此对于这类长时间运行的只读串行事务,可以使用++延迟只读事务++模式,这个模式是等待其他的串行事务结束或确保其他正在执行的串行事务不会与当前的串行事务冲突,然后才开始执行只读SQL。
这样使用的好处是,当运行长的串行只读事务时,不会感染其他的串行事务,无论跑多久都可以。
数据对齐
x86架构的字节序是小端,z架构的字节序是大端,arm架构可配置字节序。
int四字节对齐,数据对齐使得tuple的size依赖于表字段的建表顺序。
基于数据对齐的微优化: 没有NULL值并且固定长度的列可以放在建表语句的最前面。
元组的可见性
- xmin/xmax
- 共享内存结构:ProcArray活动进程列表
- 事务提示位hint bits状态最终会写入元组头infomask,但当时并不知道事务是否成功完成以及哪些元组和页面被修改,甚至一些页面可能不在缓存中,如果再次读取它们仅仅为了更新提示位,这成本也太昂贵,严重降低事务提交的速度。
因此事务操作会立刻写xmin/xmax,提示位延迟到下次访问页面的其他事务(甚至只读select查询)触发。
虚拟事务号
虚拟事务号由后端进程ID + 序号组成,虚拟事务号赋值不需要在不同进程之间进行同步,因此很快很轻量。
虚拟事务号存在于RAM中,只有当事务激活期间才存在,不会写入page或者落盘。只有当事务真正修改数据,才会产生唯一的事务号。
事务快照
下面这张图演示不同事务隔离级别下的事务快照
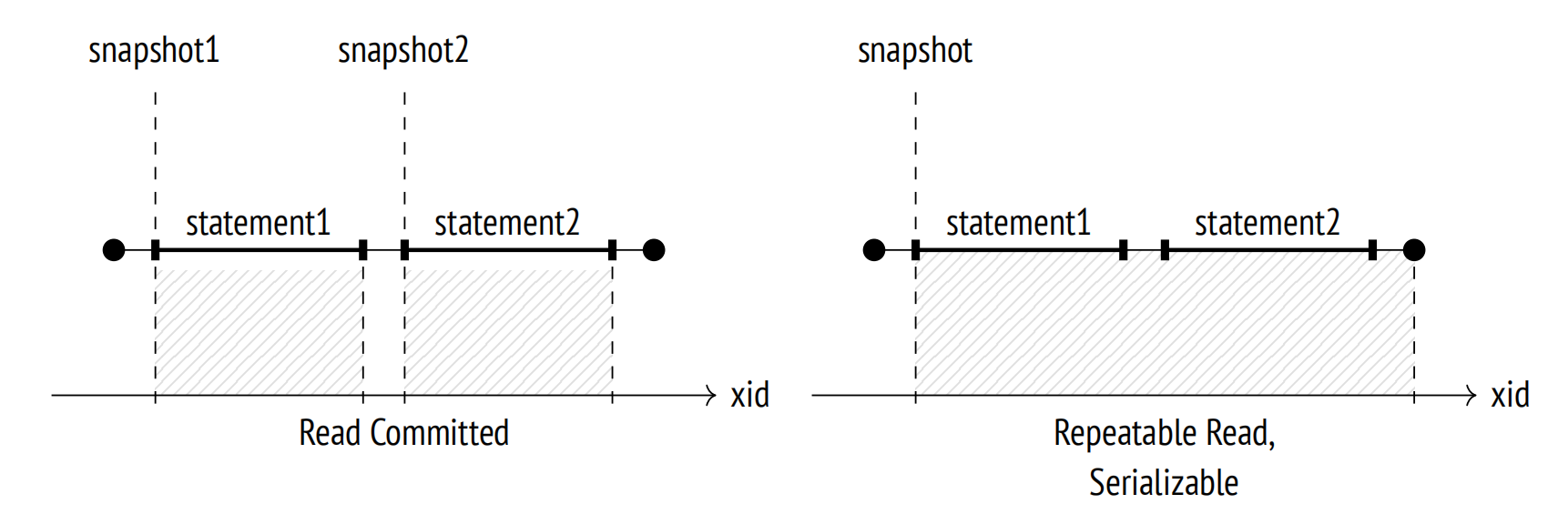
xmax定义了快照产生的那个时刻
事务视界:Transaction Horizon
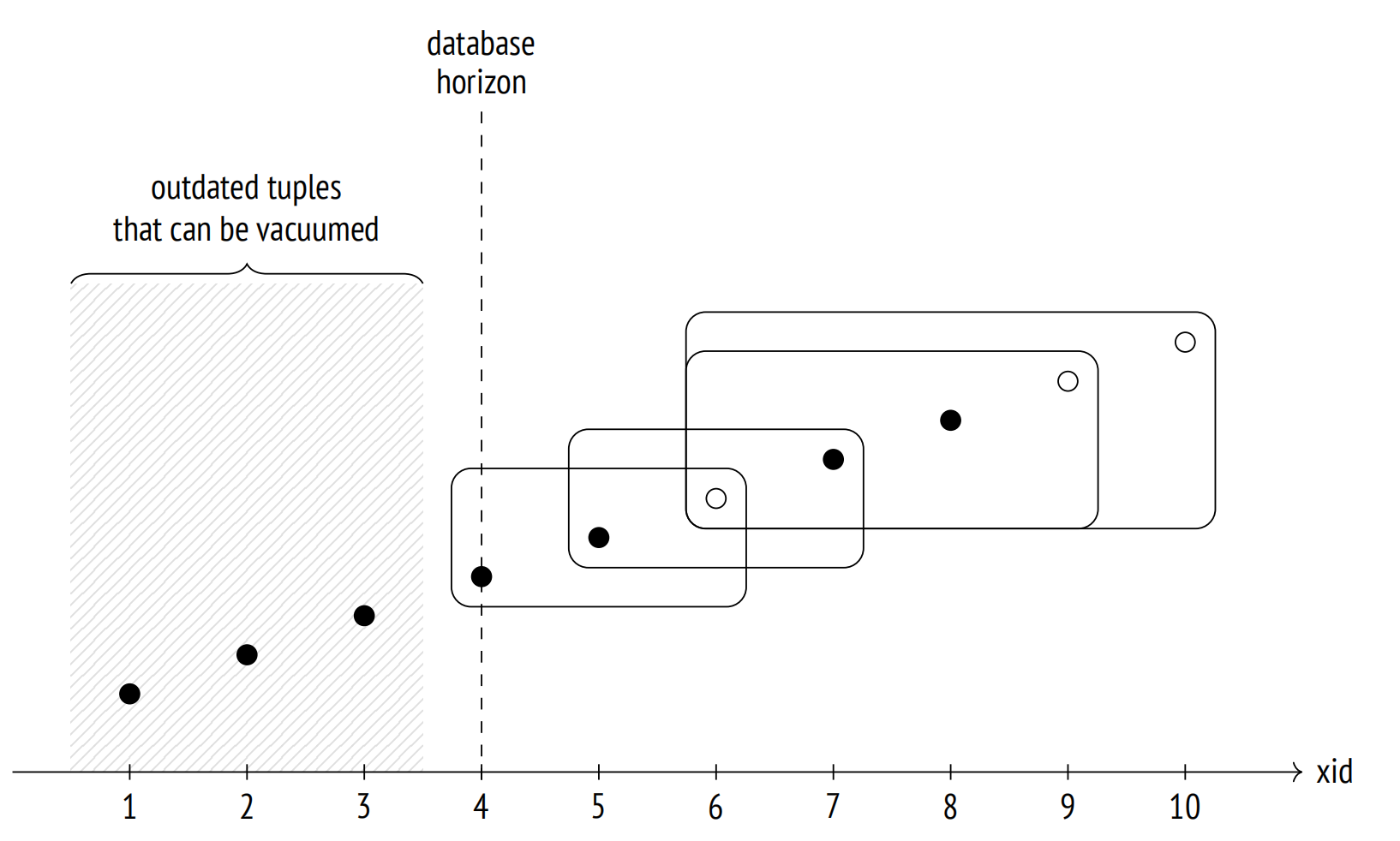
视界之内的事务(xid<xmin)已保证提交,活动会话可观测每个进程自己的视界:
SELECT pid,query,backend_xmin
FROM pg_stat_activity
WHERE pid = pg_backend_pid();
系统目录表(pg_catalog)有单独的视界,它考虑所有数据库下的所有事务。
堆尾截断:Heap Truncation
vacuum的具体操作可以分为多个阶段,其中有一个Heap Truncation阶段,数据文件的尾部包含一些empty pages,满足如下两个硬编码限制之一,可以回收操作系统空间。
- empty空间占表的十六分之一
- 达到1000个pages
autovacuum
在一次autovacuum_naptime周期内,对每个active db开一个autovacuum worker,总的autovacuum worker不超过autovacuum_max_workers。
针对autovacuum,需要单独调小autovacuum_work_mem参数,否则使用maintenance_work_mem,可能值过大。
生产环境如果active db比较多:
- 增大autovacuum_max_workers
- 调小autovacuum_work_mem,不直接使用maintenance_work_mem,以免内存使用过大。
管理freeze
有四个参数可以进行控制:
-
vacuum_freeze_min_age
-
vacuum_freeze_table_age
-
autovacuum_freeze_max_age
-
vacuum_failsafe_age
第一个参数vacuum_freeze_min_age是最基本freeze开始的阈值,但它不会出来VM文件中标记过的Page。
第二个参数vacuum_freeze_table_age会更加积极的对table进行处理,也包括VM文件中标记过的Page。
前两个参数的处理不一定包含所有场景,比如autovacuum被关闭或设置不恰当的场景,第三个参数autovacuum_freeze_max_age会强制出发,基于pg_class.relfrozenxid。
上面三个参数如果在table级进行设置,名称有一些差异,统一都以auto开头
- autovacuum_freeze_min_age and toast.autovacuum_freeze_min_age
- autovacuum_freeze_table_age and toast.autovacuum_freeze_table_age
- autovacuum_freeze_max_age and toast.autovacuum_freeze_max_age
第四个参数可以使用一种更安全的模式来保证autovacuum被快速执行,它会忽略autovacuum_vacuum_cost_delay (vacuum_cost_delay)操作代价及延迟参数的限制,同时也会跳过一些不必要的维护工作,例如索引的清理工作,此时vacuum操作将以最快的速度完成freeze来更好的预防事务ID回卷。
相当于:vacuum(freeze,index_cleanup false)
批量初始数据加载与Freeze
如果在同一个transaction里对table进行create或者truncate,由于会获得exclusive lock,该场景适合freeze,从而不需要紧接着对table做vacuum的操作。
不过需要注意对TOAST表不生效,所以如果长字段值还是会触发vacuum。
多元统计信息(Multivariate Statistics)
1.列之间存在依赖关系
CREATE STATISTICS flights_dep(dependencies)
ON flight_no, departure_airport FROM flights;
EXPLAIN SELECT * FROM flights
WHERE flight_no = 'PG0007'
AND departure_airport = 'VKO';
SELECT dependencies
FROM pg_stats_ext WHERE statistics_name = 'flights_dep';
2.多列DISTINCT
CREATE STATISTICS flights_nd(ndistinct)
ON departure_airport, arrival_airport FROM flights;
EXPLAIN SELECT DISTINCT departure_airport, arrival_airport
FROM flights;
SELECT n_distinct
FROM pg_stats_ext WHERE statistics_name = 'flights_nd';
3.mcv
CREATE STATISTICS flights_mcv(mcv)
ON departure_airport, aircraft_code FROM flights;
EXPLAIN SELECT * FROM flights
WHERE departure_airport = 'SVO' AND aircraft_code = '733';
SELECT values, frequency
FROM pg_statistic_ext stx
JOIN pg_statistic_ext_data stxd ON stx.oid = stxd.stxoid,
pg_mcv_list_items(stxdmcv) m
WHERE stxname = 'flights_mcv'
AND values = '{SVO,773}';
继续在PG的花园里挖呀挖,争取分享更多收获的花。
