




点击蓝字 关注我们
大家好,我是段春印。毕业后就一直在金融行业从事数据领域方面的工作,先后负责过数据仓库、BI、大数据平台以及整个中台的建设工作。
今天给大家分享的是《Apache DolphinScheduler在消费金融领域的生产实践》相关主题,主要包括在选型调度系统时积累的经验以及在生产实践中遇到的问题。
文|段春印
编辑整理| 曾辉
讲师介绍

段春印
唯品富邦消费金融-大数据中心经理
我今天分享的内容分为4个部分
选型背景
应用现状
优化改造
后续计划
我们选型的原则有三个:开源、简单、兼容性好。
希望选择一个免费、社区活跃度高,同时易于进行二次开发的调度系统。当然,我们对于扩容也有要求,确保能够在线简单完成扩容。
在选型的过程中,我们主要对比了以下几款调度系统:XXL-JOB、Airflow、Oozie 和 Apache DolphinScheduler。
在公司筹备期,我们的调度除了DS,其他调度工具都已经存在了(采购的软件里面包含了调度系统)。
其实最早在2019年的时候我就关注到Apache DolphinScheduler了,因为在上家单位是在银行,银行对于系统的选型是比较严格的,一般都会采用商业版,基于 Apache DolphinScheduler 是开源的原因,最终没有投产使用。
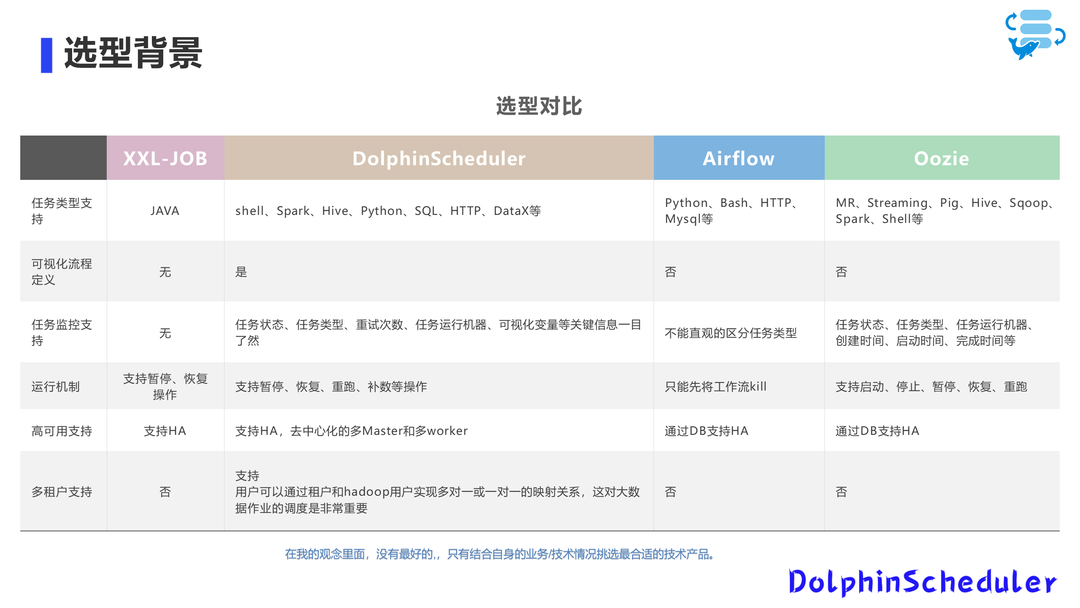
Apache DolphinScheduler 在任务类型支持、可视化流程、任务监控、高可用性、多租户支持等方面表现优秀,包括任务监控支持、运行机制、高可用支持和多租户支持。
当时我们要做大数据调度的选型,整体看来看 XXL-JOB 和 airflow 是不行的,而 Apache DolphinScheduler 在整个调度工具中,可视化的能力是不错的,同时相较于Oozie,最终我们选择了 Apache DolphinScheduler,主要是因为多租户支持的优势,选用的版本是1.3.6。
实际上,我们认为在进行开源软件选型时,没有最好的选择,只有结合自身业务需求找到最适合自己的方案。我们选用Apache DolphinScheduler,是因为它更符合我们的需求。比如去中心化的容错性,去中心化的部署模式和容错性高决定让我选择了它,并且我们要在调度方面做两件事。
消费金融的业务其实跟银行差不多,只不过我们大多数做的是贷款业务。在系统方面,有信贷核心、风控、支付、营销、总账等系统,都会涉及跑批,凡涉及跑批的事情,那么都会涉及调度,为了便于后续的统一管理,需要把调度工具进行统一。
因为在上家银行工作时,上下游用的调度工具不同,甚至在数仓,ODS 和DW用的也是不同的调度工具,会带来很多问题,尤其是上下游做数据依赖任务等待,会遇到较多的问题,基本上每周都有四五天,在晚上起夜去处理因为数据依赖等待带来的问题,除此还有一些数据质量、任务报错的问题,这个会很痛苦。
所以来到现在这家公司之后,在调度上我想做的第一个事情,就是把调度工具统一。
主要为了解决上下游全链路数据依赖和统一管理的问题。我们的目标目前基本上已经达成。
目前调度已经统一了,并且也实现了统一调度,包括 ODS 、数仓、数据集市、各业务系统的交互,统一由DS进行调度,还有下游系统,如营销、风控的贷中贷后的管理,基本上都是用 Apache DolphinScheduler 来做的统一调度。
Apache DolphinScheduler 在2021 年上线的,目前有 9 个节点,2 个master、 7 个worker, 38 个项目。为什么项目这么多,是因为我们把能做批量任务的项目都纳入了进来,已经覆盖到整个数仓、集市及下游系统。
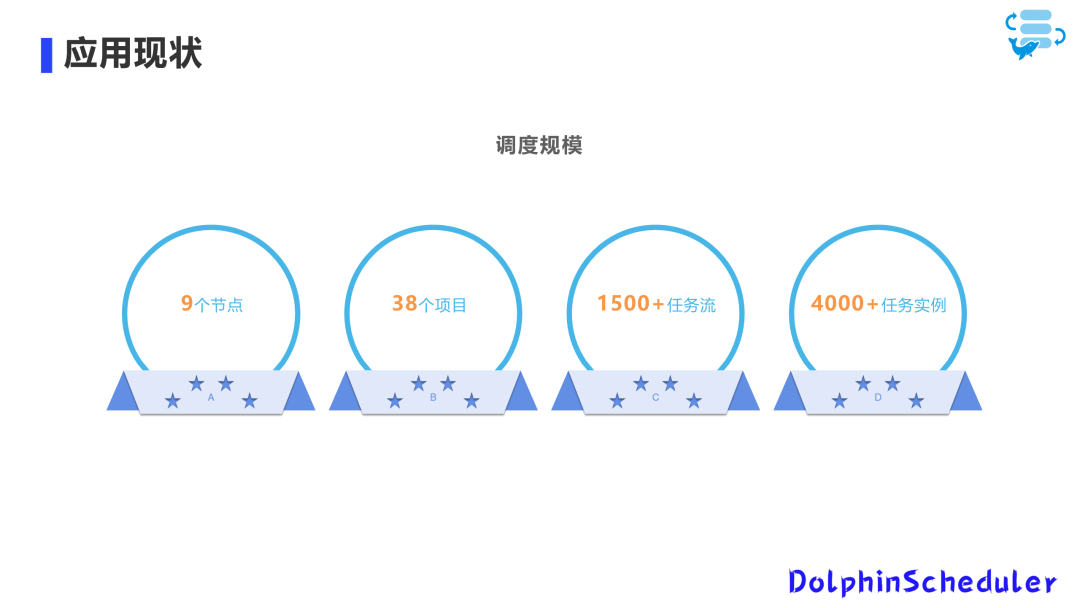
一年就上了1500+的任务流,任务实例是大概4000+,这是目前整个调度的一个规模。
应用场景分为 6 大类:数据采集、数据加工、数据质量检核、集市加工、数据卸载和业务监控告警。
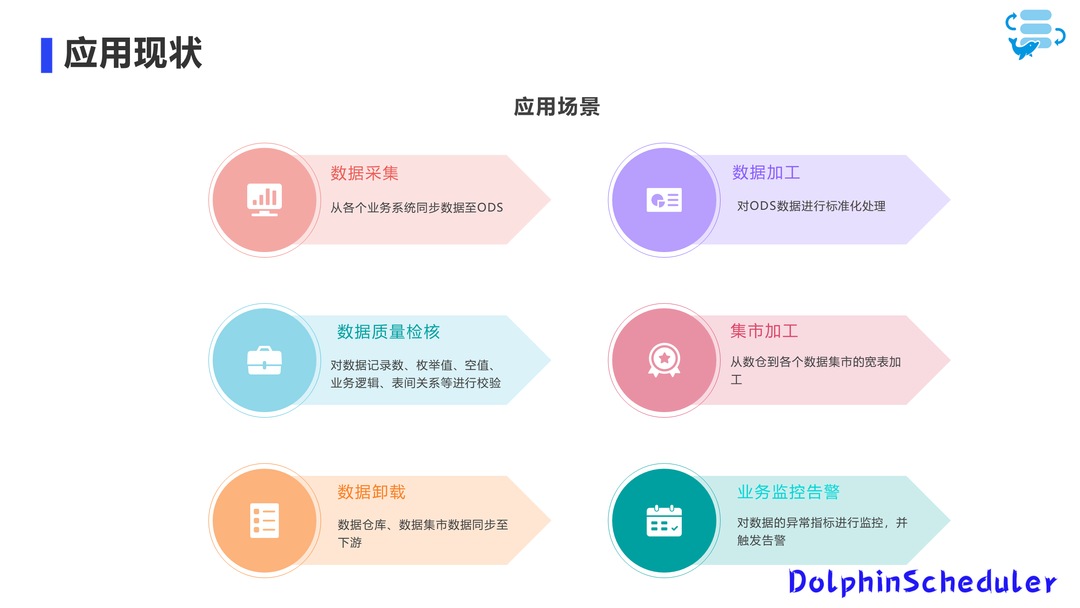
其中,数据采集主要包括从上游同步数据到数仓,数据加工是 ODS 到数仓的标准化处理和数据清洗,数据质量检核是针对数据质量问题进行检查,集市加工涉及从数仓到集市的数据加工,数据卸载是数仓到数据集市的数据同步卸载,以及数据集市到下游系统的数据同步。
目前,Apache DolphinScheduler 整体运行稳定,没有出现过什么大的故障,唯一的故障是因为Master线程限制的问题(最多100),导致了一次服务重启。
这里可以提醒大家一下:Master 不是有100的线程阈值嘛,整个上游任务出现了等待超过了100的阈值,忘了设置优先级造成堵塞,造成“重启”的小事故。
我们在当时碰到一个很头疼的问题,大家应该知道1.x 的版本,上游任务失败之后,随之下游的任务也会失败,等我们处理完上游任务的时候,还得把下游任务重跑一遍,这让我们感到很痛苦。
针对这个痛点,我们就做了一些改造,大家可以看到下图:
解决思路:比如上游失败了,我们会告警运维人员去处理,同时让下游的任务不失败,处于就继续等待状态,通过这样的动作,会减少很多运维的工作。
其次还有“重跑”的优化,因为从 ODS 到整个下游数据加工的链路很长,如果说某个上游任务出错了或者说数据质量有问题,这时候要重跑,怎么办?我们不可能把每个任务的依赖都找出来重新再跑,而且也很难找全,类似这个情况在我们这边发生了很多次,也是让我们很痛苦!
解决思路:针对任务链路很长的情况,当某个上游任务出错或数据质量有问题时,我们优化了重跑功能。通过分析上下游任务依赖关系,形成一个血缘关系视图,实现一键到底的重跑功能。
关于统一告警,我们已经加入了这个功能。
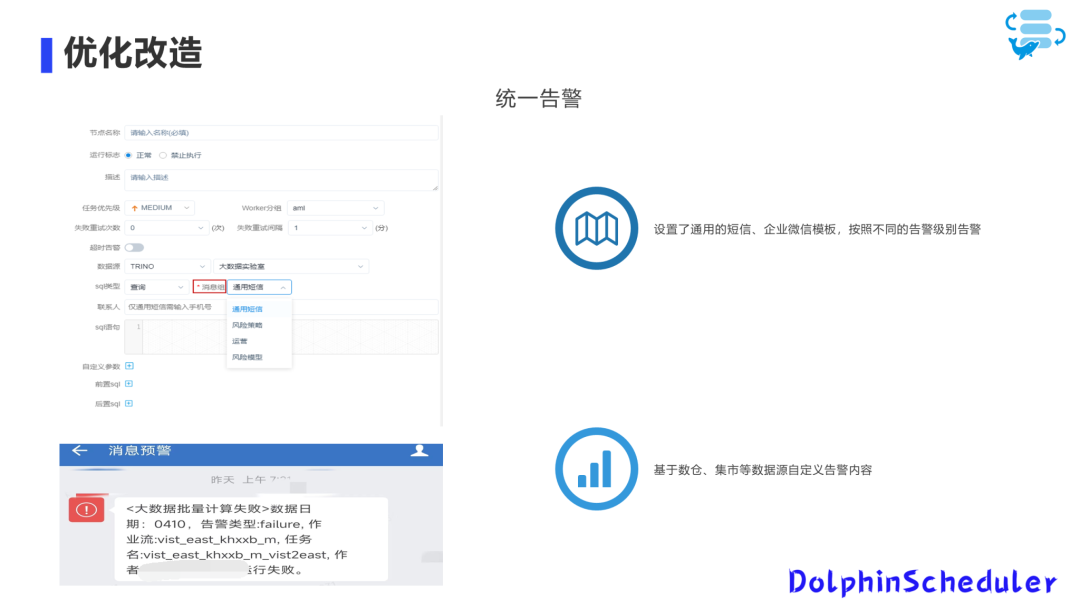
大家可以看到下图,我们需要设置通用短信模板以及企业微信模板。
我们会根据告警级别进行分类,因为不同级别的告警需要采取不同程度的处理措施。
此外,我们还将这个功能应用于业务监控告警,特别是针对数据分析的同学,他们可以进行异常指标监控。通过编写SQL语句,根据需求定制一些SQL,然后自定义内容并选择通用模板。只要生成了数据,系统就会自动发送到相应的企业微信中。
这个示例展示了我们在技术层面上将告警信息发送到企业微信的应用情景。
我们的大数据底座是 CDH,数据质量检核采用 Trino 引擎,通过编写自定义SQL进行检核。编写Shell脚本,我们将数据查询结果按照0和非0进行判断,以此作为判断错误的依据。若结果为0,我们认为该结果正常;若为非0,则强制报错。由于下游任务对此有强制依赖,因此错误发生时,下游任务会处于等待状态。
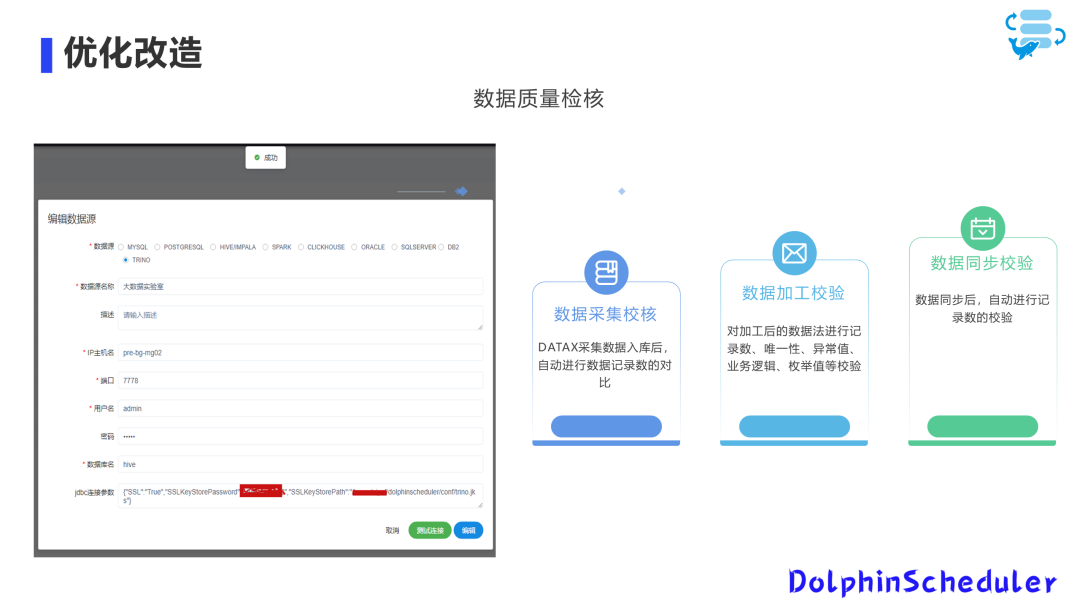
在数据采集环节,我们进行了封装,可以自动进行数据记录数的校验。在数据同步过程中,会自动进行比对,因此没有必要单独编写SQL进行比对。如果记录数不正确,特别是在跨库情况下,系统会报错。
数据加工校验和数据同步校验也是使用Trino进行自定义编写的。我们编写了跨库自动同步的逻辑,并通过单独编写的Shell脚本封装了这一部分。
为了提升安全性操作要求,我们需要对权限操作进行细化。当前版本的权限控制较粗糙,仅能达到项目级别,但我们期望实现按钮级别的权限控制。目前,我们正在规划相应的改进措施以完善这一部分。
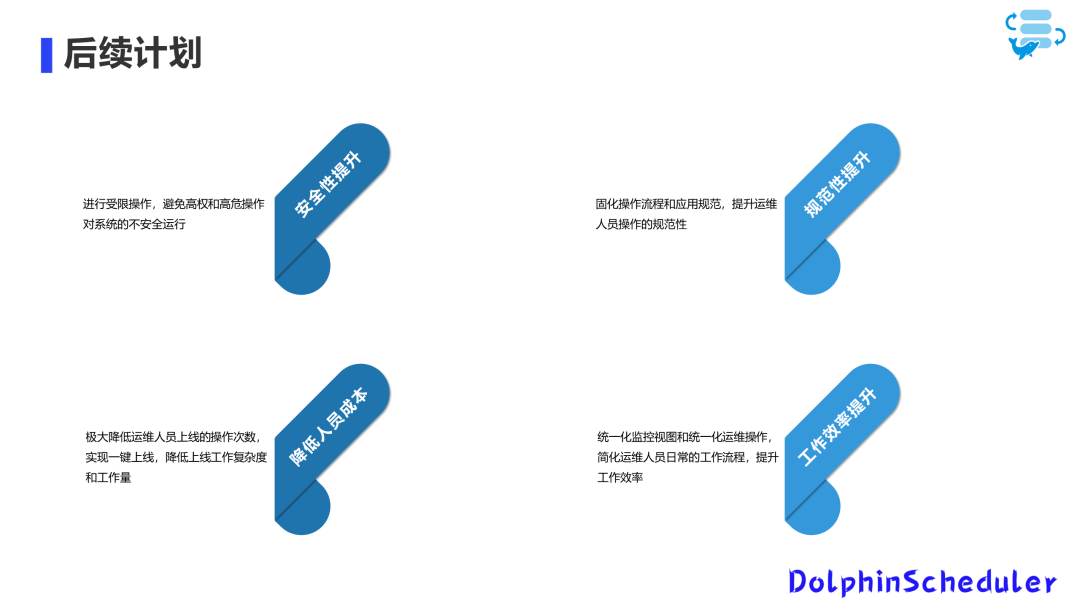
在规范性方面,我们计划对一些固定流程进行固化,因为当前开发过程中有许多模板。例如,整个数据仓库的ODS和数据同步流程相对较为固定。
未来,我们将实现这些流程的自动化。例如,根据特定模板自动生成相应脚本,直接导入到生产库中,并自动生成调度流程。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表(Good First Issue):https://github.com/apache/dolphinscheduler/contribute
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22help+wanted%22+q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://github.com/apache/dolphinscheduler/blob/8944fdc62295883b0fa46b137ba8aee4fde9711a/docs/docs/en/contribute/join/contribute.md
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
