




DSE精选文章
An Adaptive Elastic Multi-model Big Data Analysis and Information Extraction System
文章介绍
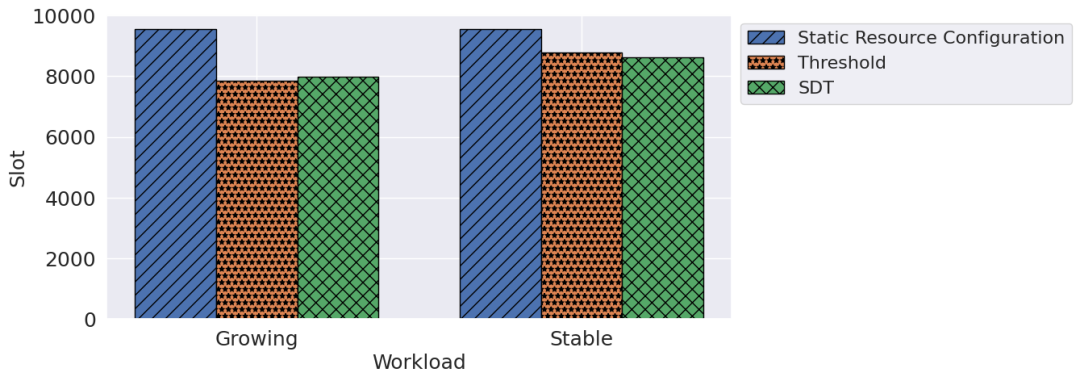
随着行业和特定领域环境下的多样化应用,对半结构化和非结构化数据以及跨数据模型的多源信息提取变得越来越普遍。然而,多模型信息抽取往往需要在云端部署多个数据模型管理、存储、分析子系统,多个子系统同时资源利用率不高,资源浪费现象往往比较严重。为此,文章设计并实现了一种自适应伸缩的多模型大数据分析和信息抽取系统,能够支持关系型、图型、文档型、键型等数据模型的数据维护和跨模型查询,提供高效的跨模型信息提取。在此基础上,文章提出了基于控制论的自学习动态阈值弹性伸缩算法。根据多模型大数据分析的实时性要求,动态调整各子系统资源分配。该方法使伸缩资源的阈值动态可调,并能针对调整结果进行学习,解决了经典阈值法依赖专家经验或系统测试设定阈值,和难以兼顾QoS保障和资源利用率的问题。在真实数据集中模拟常见云应用工作负载评估时,系统可以在对性能影响小于5%的前提下减少30%的资源量,不仅保证了多模型查询和信息提取的性能和服务质量,而且显着降低了系统资源的总消耗和成本。论文的主要贡献如下:
(1)总结了经典阈值方法的问题,并提出了一种基于控制论的自学习动态阈值方法。
(2)设计并实现了一种自适应伸缩的多模型大数据分析和信息提取系统。
(3)在真实数据集中模拟常见云应用工作负载,对提出的方法进行实验评估。与基线方法相比,该方法具有更好的总体效果。
实验效果
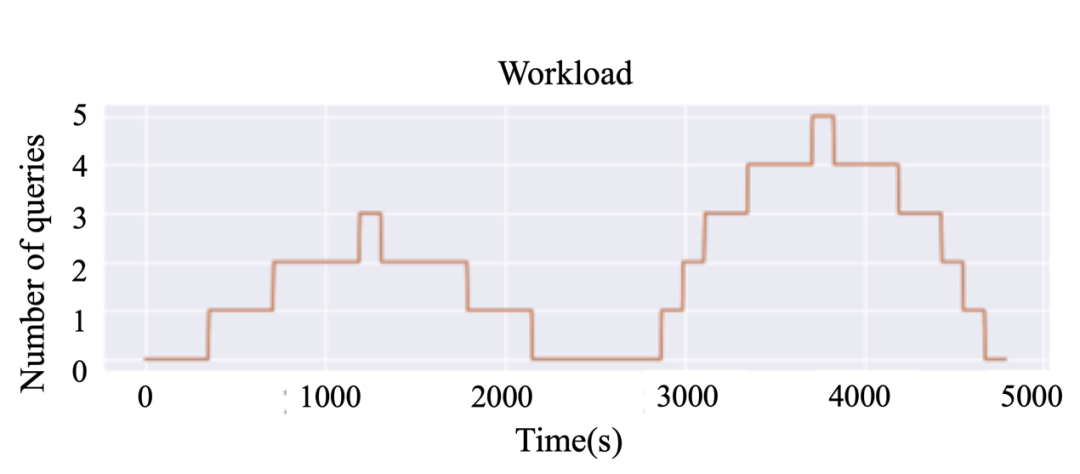
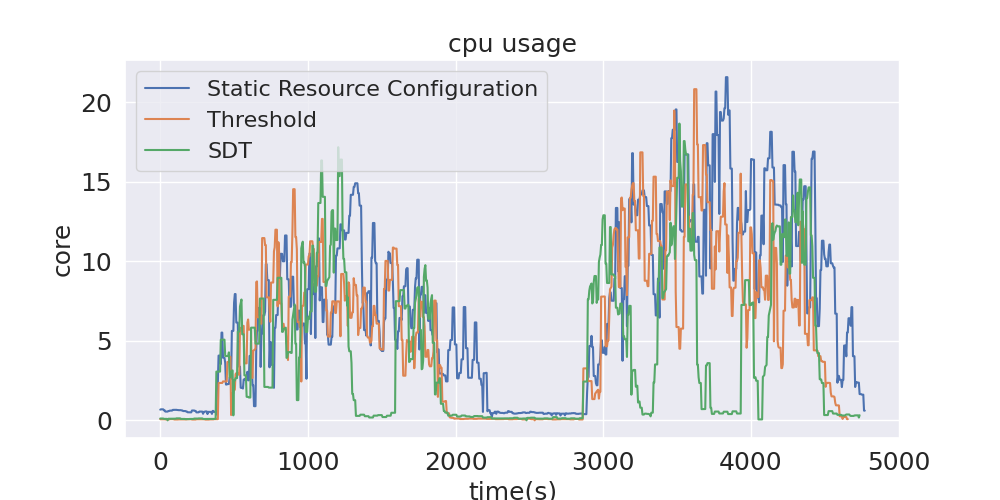
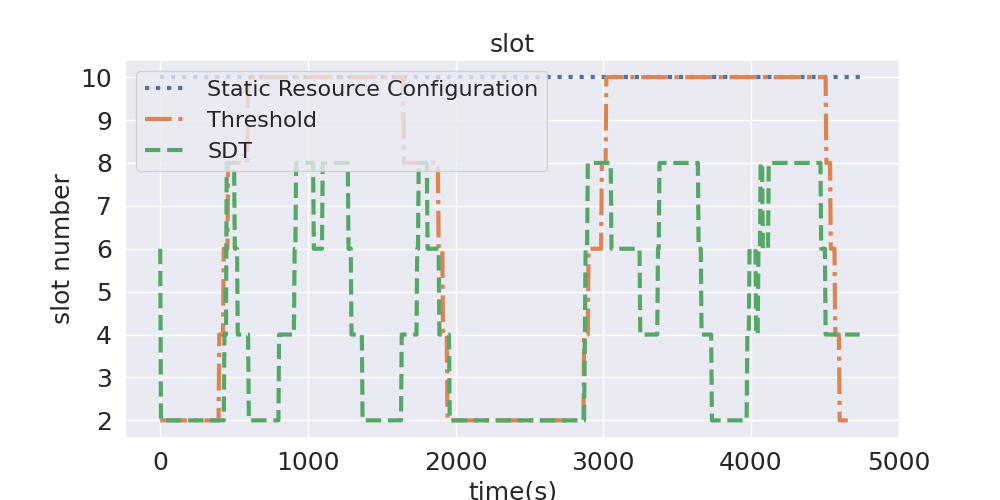
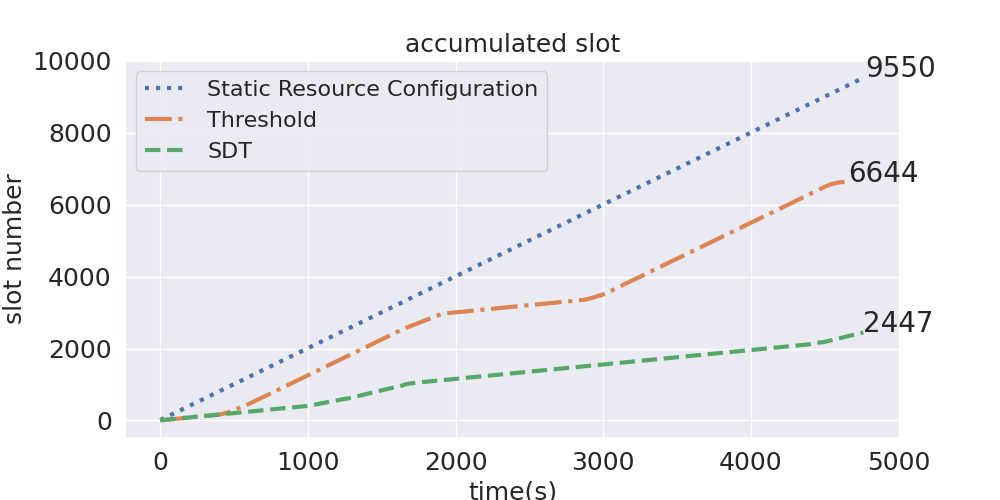
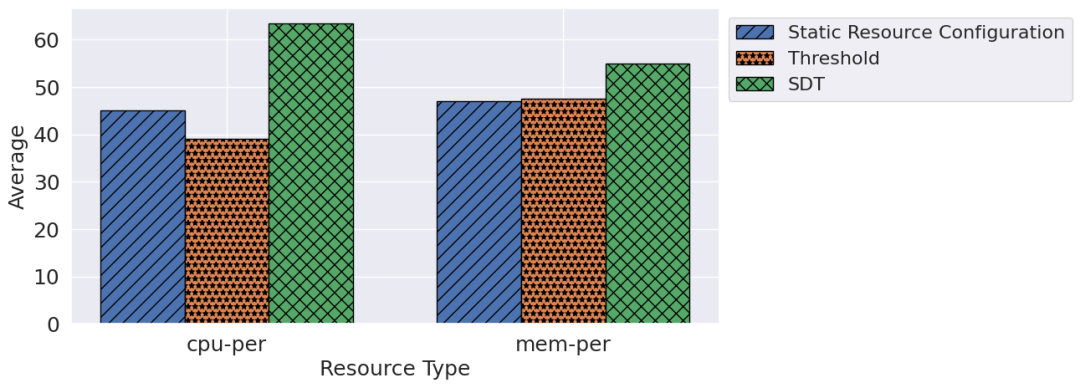
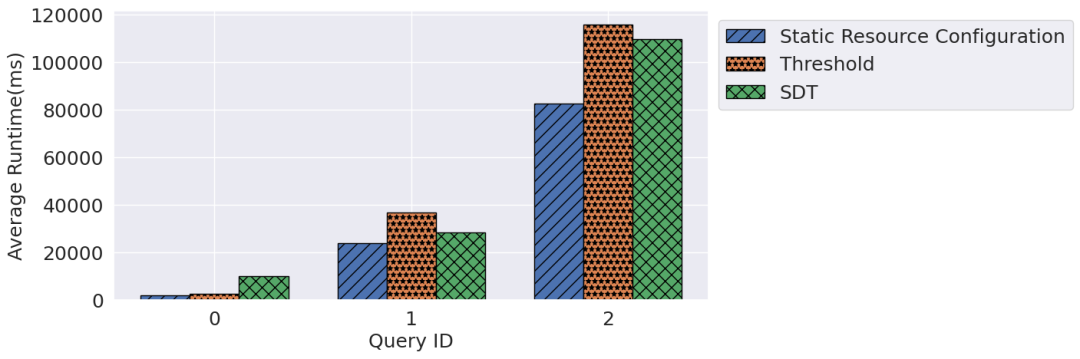
图6展示了无弹性伸缩,文中方法和基线方法的查询性能变化。在大部分情况下,该方法较基线方法花费更少的查询时间。
结语
作者简介


期刊简介



文章转载自CCF数据库专委,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
