




Failover直白说就是在A无法提供服务时,系统能够自动切换到失效备份B上继续提供服务,而切换过程对客户来讲完全无感知。Failover使用广泛,这里所说的A和B存在于各个领域,常用在计算机领域的数据库、应用、硬件设备等的时效切换。
在分布式数据库中,用户在执行DDL操作或者DML操作时,如果执行节点的服务崩溃或者出现网络异常,会使得事务过程中断而造成集群中主备节点数据不一致。为了解决这个问题,通常的解决方案就是引入Failover机制,来保证当出现执行节点的服务崩溃或者网络异常时,数据库系统能够自动的用备份节点对故障节点上运行的执行动作进行接管,从而保证集群中数据的一致性。
GBase 8a MPP Cluster数据库不例外,也是采用了Failover机制来进行故障切换。GBase 8a MPP Cluster所有GCluster节点均能作为接管节点来处理Failover,能实现Failover的并行处理。
Failover机制
GBase 8a MPP Cluster的Failover机制一般包括注册、故障检测接管以及接管节点如何选择、Failover恢复和故障节点重新加入等几个部分。在集群中某一协调节点发生节点故障时(包括进程死的软件故障或者系统宕机的硬件故障),GCware首先会检测到该节点上的故障,并将这一故障状态通知给集群内其他协调节点,此时GCware会协调这个节点从集群成员中离开并调整集群构成的元数据信息更新。当协调节点故障发生后,如果对集群的某节点的GCluster(分布式任务执行调度器)发出加载和增、删、改和查询任务时,GCware会根据集群内的协调节点间的负载均衡机制,将本来分配给故障节点的任务转移到在其他协调节点来执行,这样就完成了对协调节点故障的故障转移(Failover)。
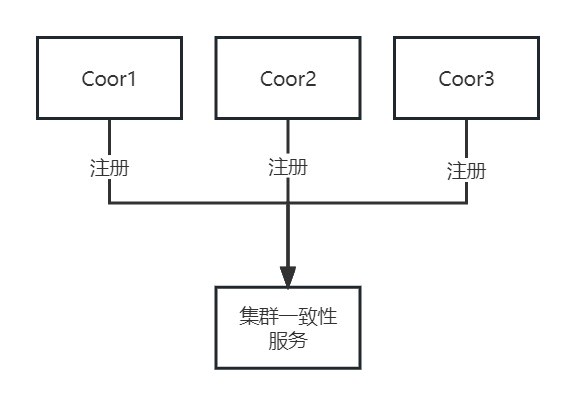
注册
当Coordinator节点上的GCluster服务启动时,会向集群一致性服务GCware注册接管连接,此时GCluster会与GCware之间建立一个长连接,GCluster定时向GCware发送心跳来保证连接有效。在执行DDL或DML时,GCluster会先向GCware记录Failover信息,如果任务未发生异常,则在任务完成后删除Failover信息,反之,则触发Failover接管流程。
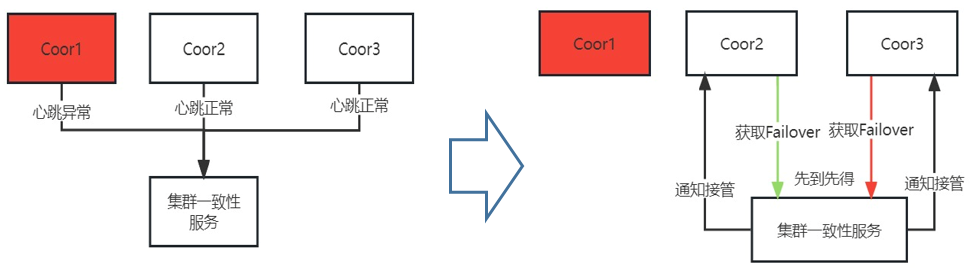
故障检测与接管
当Coordinator节点上的GCluster服务异常宕机或者与GCware服务之间的网络出现异常情况下,GCware无法正常收到GCluster发来的心跳时,GCware即认为GCluster服务故障,开始触发Failover接管流程。
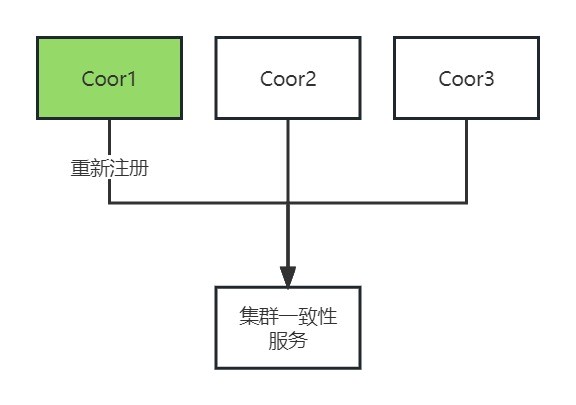
故障节点重新加入
Coordinator节点上的GCluster服务重启后,重新向GCware注册,注册完成后,可正常承担接管任务。
Failover处理流程及操作
当执行某SQL的管理节点出现故障,无法正常完成SQL操作时,接管节点将读取记录于gcware中的SQL执行信息继续执行,该过程就是管理节点的failover机制,主要包括如下的执行流程。
1.GCluster向GCware注册
2.Gcware添加到节点列表
3.集群中存在Failover(若不存在也会生成Failover,
但takeover node为空)
4.通知GCluster来接管Failover
5.GCluster处理Failover
6.处理完毕GCluster继续向GCware获取下一个未接管的Failover继续处理
查看Failover
执行命令:gcadmin showfailover
如果没有Failover则显示“gcadmin
showfailover: no gcluster failover information now”,否则列出Failover信息,例如:
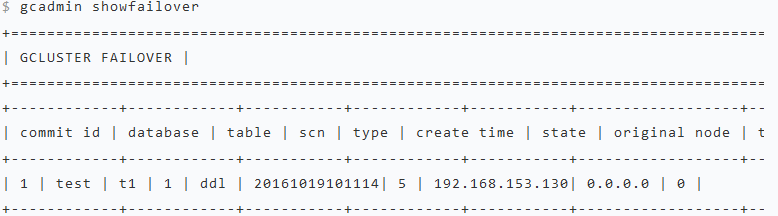
内容说明:
- commit id: failover 的唯一标识,64 位数字
- database: 数据库名
- table: 表名
- scn: scn 号
- type: ddl/dml/rebalance
- create time: 当前节点创建 failover 的时间
- original node: 发起节点
- takeover node:当前接管节点,如果没有发生接管则显示为0.0.0.0
- takeover num:failover的接管次数,gcware通知gcluster接管后这个值就加1
- state: failover 对应的状态当前如下:
- init:初始化,对应显示数字 0
- add_res :
添加集群锁,对应显示数字 1
- set_info
: 设置 failover 信息,对应显示数字 2
- set_status:
设置分片状态,对应显示数字 3
- set_rebalance_info:设置 rebalance 信息,对应显示数字 4
- set_rebalance_status:设置 rebalance 状态,对应显示数字 5
如果需要查看更详细的Failover信息,则使用如下命令:
gcadmin showfailoverdetail [xml_file_name]
参数说明:
Commitid:Failover 的唯一标识,该参数必须输入,同gcadmin
showfailover的Commitid;
Xml_fil_name:保存 failover 信息的文件名,可选,若不输入则将Failover
信息打印到屏幕;
增加的内容:
content: failover 完整信息,最大 256k
status: failover 操作的对象状态即对应的是哪个节点哪个分片的状态。例如 node1.n1 init 含义就是 node1 节点上 n1 分片尚未提交处于初始化状态
rebalance_information:rebalance 独有信息(
含distribution_id, current_scn, current_step, 中间表名),ddl dml 显示为空标签
sdm: 仅用于rebanlance,由如下字段联接而成:
NodeId.Suffix : 某个节点的某个分片;
curRowid:rebalance 执行到哪一行了;
Blockid BlockNum:上一批rebalance执行到哪一行;
强制Failover【慎用】
采用Python接口来在特殊情况下进行Failover的清除,不到万不得已的情况下慎用强制清除,使用之前要充分与GBase支持人员沟通。
Python的命令为:
deletefailoverforce(commitid),成功返回0,非0表示失败。其中commitid是通过gcadmin showfailover查询出来的commitid。
[gbase@localhost ~]$ python
>>>import gcware
>>> gcware.deletefailoverforce(20) #20是需要删除的commitid。
0
>>>quit()
