




在 Oracle 数据库中,有时候会看到一个奇怪的事件:reliable message ,当这个事件出现在 TOP 5 中时,可能就会引起大家的焦虑。
我整理一下关于这个事件的种种情形,供大家参考。
Reliable Message 是一个通用等待事件,用于跟踪Oracle数据库中的许多不同类型的通道通信。
很多人简单的将这个等待归入 Message 消息空闲等待,这是不对的,当这个等待出现时,一定意味着某些进程的通道通讯受到阻塞。当然影响主要是进程级别的,不是全局影响。但是一旦大量进程遭受影响,那么这个等待事件毫无疑问就会十分突出。
案例一:集群故障
双节点RAC环境中,一个节点因为锁竞争而挂起,shutdown之后无法启动。解决之后查找故障原因。
检查当时的AWR信息发现Top 5 Timed Events显示如下信息:
Top 5 Timed Events Avg %Total
~~~~~~~~~~~~~~~~~~ wait Call
Event Waits Time (s) (ms) Time Wait Class
------------------------------ ------------ ----------- ------ ------ ----------
reliable message 354 89 251 219.4 Other
CPU time 32 78.3
db file sequential read 2,223 12 6 30.3 User I/O
control file sequential read 29,151 8 0 20.9 System I/O
db file scattered read 36 2 62 5.5 User I/O
-------------------------------------------------------------
这里最显著的事件是reliable message,这个事件Metalink的解释为:
When you send a message using the 'KSR' intra-instance broadcast
service, the message publisher waits on this wait-event until
all subscribers have consumed the 'reliable message' just sent.
The publisher waits on this wait-event for three seconds and
then re-tests if all subscribers have consumed the message, or
until posted.
也就是说当跨实例发送消息时,发送者期望收到订阅者的回复信息,如果得不到可信回复,就会一直处于等待。等待以3秒为周期进行反复尝试,知道收到所有订阅者的回复或者被唤醒。
那么在这个环境中,也就是说两个节点的通讯已经出现问题,一个节点得不到另外一个节点的回复,如果只是普通的服务请求,影响的只是个别进程,通常不会引起全局问题。
案例二:进程故障
以下是一位朋友提供的情形,例如当我们调用了 AQ ,但是没有设置 AQ进程,则数据库以此事件处于等待,设置 aq_tm_processes 参数 > 0 等待即可消除。
Althoug this is an old issue it just happened to in a test RAC.
"reliable message" is really not to worry for but if some sessions
are waiting and the wait time (secs) is increasing you may look at
parameter aq_tm_processes: it should not be ZERO.
If it is, set it to at least 2.
这种情况同样说的是进程等待,处于的空闲消息状态,因为工作任务得不到分配,当然需要关注和处理。
案例三:问题诊断
在遇到 reliable message 问题时,可以通过等待事件的参数进行进一步的诊断和分析。
在 v$event_name 视图中,我们可以找到该事件的三个参数的含义,三个参数分别代表 channel context ,channel handle ,broadcast message,获得这三个参数,就能够做出一定的判断:
SQL> select name,parameter1,parameter2,parameter3
from v$event_name where name='reliable message';
NAME PARAMETER1 PARAMETER2 PARAMETER3
----------------- --------------------- ----------------------- ------------------
reliable message channel context channel handle broadcast message
例如:在出现等待时,通过以下查询,获得 reliable message 的 P1 参数:
select to_char(p1, 'XXXXXXXXXXXXXXXX') event_param,
count(*), sum(time_waited/1000000) time_waited
from gv$active_session_history
where event = 'reliable message'
group by to_char(p1, 'XXXXXXXXXXXXXXXX')
order by time_waited desc
EVENT_PARAM COUNT(*) TIME_WAITED
--------------------------------------------------- ---------- -----------
3CCF8A1D8 572 904.548231
3CCF96200 109 69.145101
3CCF9AFF0 54 23.987554
通过 x$ksrcdes 可以找到 P1 参数代表的通道信息:
select name_ksrcdes
from x$ksrcdes
where indx = (select name_ksrcctx from x$ksrcctx where addr like '%&addr%');
SQL> /
Enter value for addr: 3CCF8A1D8
NAME_KSRCDES
---------------------------------------------------------------------------
RBR channel
进一步的通过 GV$CHANNEL_WAITS 可以查看数据库的各种类等待。
有了这些信息,通过匹配 MOS 上的BUG内容,基本就可以确定是否是已知问题引起的,例如 RBR 相关的BUG就是:
Bug 15826962 High "reliable message" wait due to "RBR channel"
BUG描述:Increased in 'reliable message' waits may be seen associated to KSR Reuse
Block Range (RBR) messaging during Securefiles free space search.
可以看到这个BUG是因为 Securefiles 的自由空间扫描引发的,影响版本是 11.2.0.3 。
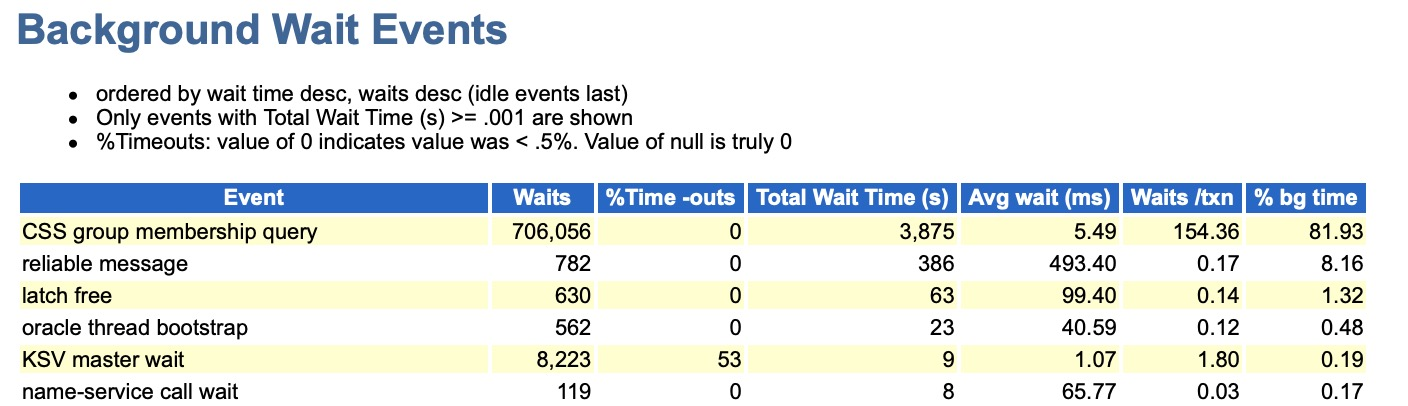
BUG 20470877 - LONG WAITS FOR "RELIABLE MESSAGE" AFTER A FEW DAYS OF UPTIME
BUG描述:CSS group membership query's are not processed fast enough because of congestion.
这个BUG 是因为 CSS 的成员查询阻塞导致的,影响版本是 12.1.0.2,当遇到Bug 20470877 时,通常可以在AWR报告中观察到类似如下的后台等待(CSS group membership query):
案例四:结果集缓存
如前所诉,当出现显著的 reliable message 等待时,应当诊断是哪一类通讯通道遇到问题,这可以通过统计 V$CHANNEL_WAITS 视图来获得。
例如如下案例,通过分析统计,处于第一位的是:Result Cache: Channel 。
SQL> SELECT CHANNEL,
2 SUM(wait_count) sum_wait_count
3 FROM GV$CHANNEL_WAITS
4 GROUP BY CHANNEL ORDER BY SUM(wait_count) DESC;
CHANNEL SUM_WAIT_COUNT
---------------------------------------------------------------- ----------------
Result Cache: Channel 429264591
RBR channel 323918
kxfp control signal channel 145021
MMON remote action broadcast channel 4146
obj broadcast channel 295
LCK0 ksbxic channel 27
parameters to cluster db instances - broadcast channel 2
这个问题是结果集缓存的Bug导致的,Bug号为19557279,该问题在Oracle 12.2版本中修复。参考:
Very High Waits for ‘reliable message’ After Upgrade to 11.2.0.4 When Using Result Cache (Doc ID 1951729.1)
如果未使用结果集缓存特性,可以通过临时关闭来解决:
SQL> alter system set result_cache_max_size=0;
System altered.
