




备注: 本次介绍版本为:2.19.09.0
概述
dble是爱可生基于MySQL开发的高可用,可扩展性的中间件。他的特点是:
数据水平拆分:随着业务的发展,可以使用dble替代原始的单MySQL实例 兼容MySQL,与MySQL协议兼容,在⼤多数情况下,您可以⽤它替换MySQL来为你的应⽤程序提供新的存储,⽽⽆需更改任何代码。 高可用性;dble可以作为集群运行,不受单点故障影响 SQL支持。支持92标准和MySQL官方语言 复杂查询优化。包括且不限于全局表连接分片表,ER关系,子查询简化选择等 分布式事务。使用两阶段提交的分布式事务。 dble开发是基于MyCat进行开发的
框架如下图
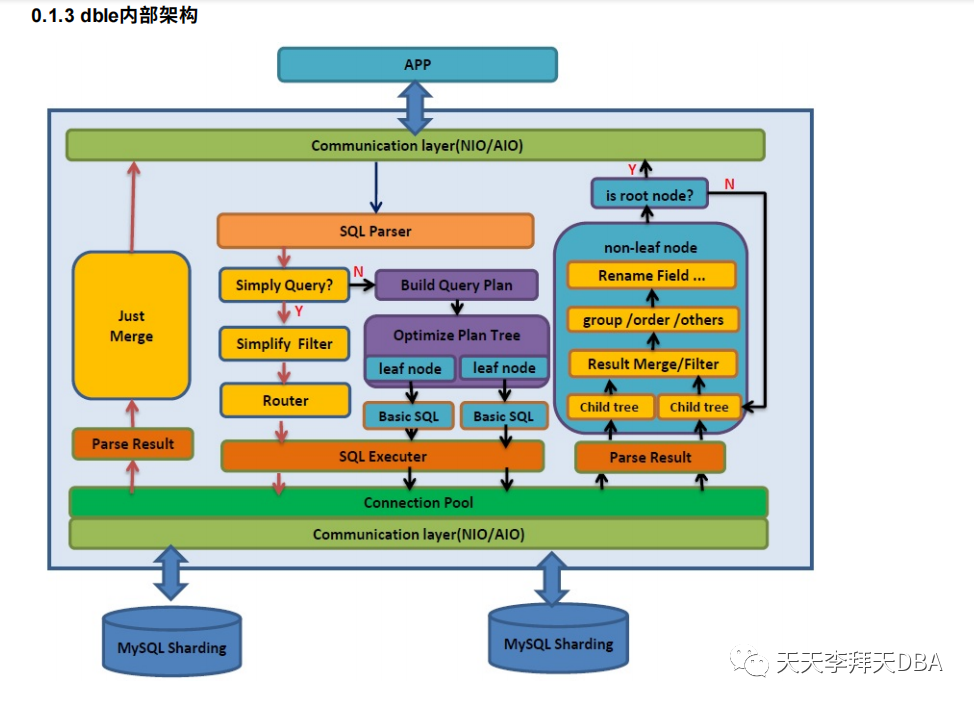
数据拆分
dble将数据表按照数据分片大致分文三类
全局表:该类型的表在每个MySQL节点上都有实体表,且存放着全量数据。一般可用作字典表,和多表关联,作为数据字典的表格 拆分表:设置为拆分表的表会按照指定拆分规则将数据分别存在不同的MySQL节点中,每个节点中表存放这部分数据。一般用在超大数据量的数据表上。通过水平拆分实现性能的优化 非拆分表:该类型表会存放在指定MySQL节点上,并且为全量数据。一般用在数据业务压力不大的表格上
dble 的配置文件
这里只介绍数据拆分,访问相关的三个配置文件的内部联系(每个文件的属性解释建议阅读官方文档,更为详细)
rule.xml server.xml schema.xml 其他文件:
wrapper: 该文件配置与JVM虚拟机等参数相关
log4j.xml:log4j2.xml 配置日志相关参数
cache配置:配置缓存相关参数
全局序列文件:全局序列相关配置
myid.properties: 集群相关配置
自定义拆分算法
自定义告警
rule.xml文件概述
该文件主要作用:
定义有哪些分片规则:tableRule 的名字(name) 每个tableRule 拆分的列,及该列的 使用的 function名字 创建分区算法 name,并指定使用的那种算法(Enum,NumberRange,Hash,StringHash,Date,PatternRange,jumpStringHash) 定义每个算法的属性(具体范例的文件: <mapfile>
hash分配的群建数,各区间长度。等)
schema.xml文件概述
该文件一共有三大块
dataHost : 针对的是物理节点(MySQL 所在服务器)的配置 dataNode:针对的是数据节点:设置数据保存的database(数据保存在哪个schema上) schema:设置schema分布在哪个数据节点上,schema 内部的表属性及关系的配置(表,主键,使用rule,父子表)
server.xml 文件
该文件包含
property:主要设置的是DBLE服务的相关配置(前后端连接,session内存配置,系统服务基本参数,一致性检查,心跳设置等) user (管理员用户配置) 用户名,是否是管理员用户 ,密码。连接属性配置 user(业务用户配置) 基本同上,但是没有是否为管理员属性 黑白名单 alarm(ucore告警grpc接⼝)
以上信息的详细信息可以查看官方中文文档,这里只是做些概述。下面内容是介绍 rule.xml
,schema.xml
,server.xml
文件的内部联系,这样可以方便大家在刚接触一个新的环境时最快了解线上DBLE环境的信息
首先是看下这三个文件关系的导图
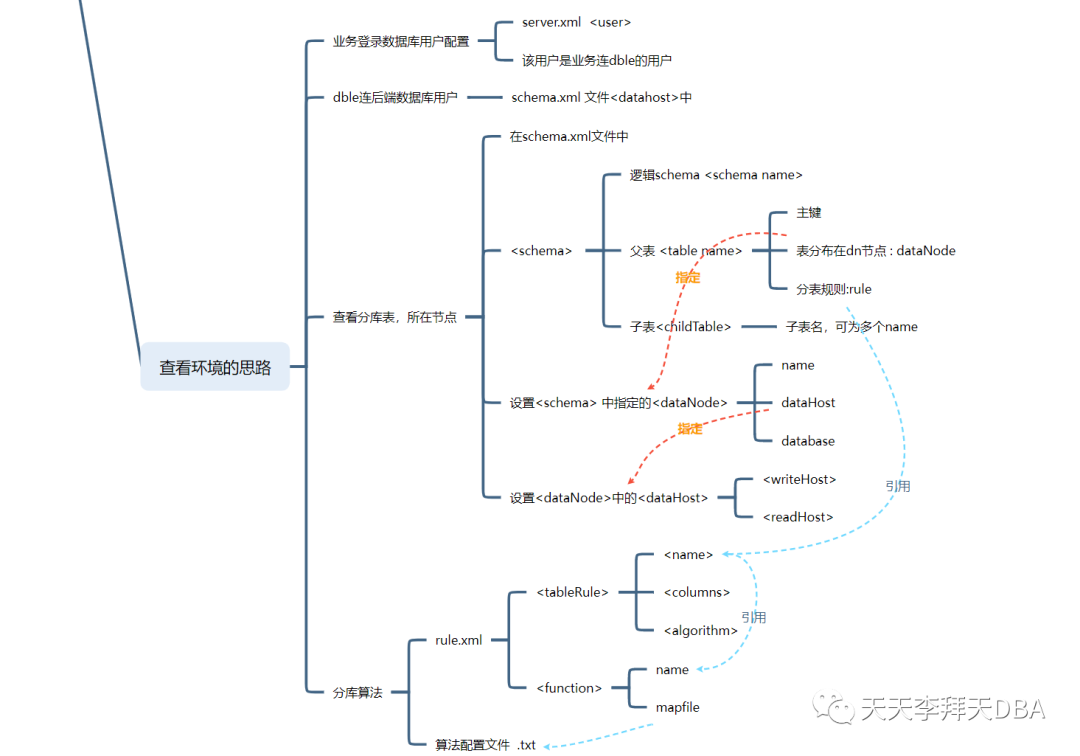
如上图所示我们可以按照下面思路阅读配置文件
1. 查看dble程序配置及访问用户
server.xml中查看 (该文件内的配置相对独立和其他两个( schema.xml,rule.xml
)关联少些)
在<system>
中获得消息
a. 查看dble业务账户登录端口(即客户端连dble):<property name="serverPort">8066</property>
b. manager用户登录端口<property name="managerPort">9066</property>
c.<user>
中获得信息 设置管理用户,业务用户连dble
的账号密码,及访问schema,table
及权限
2. 查看分库分表对应dataNode的配置
a. <schema>
中name
指定了要配置的逻辑 schema
名称(该schema
在物理MySQL节点上是没有的)
b. <schema>
子项的 <table >
设置的是这个逻辑 schema
中的表的属性:是否为 global
表,分表,父子表的关系以及表分布在哪个dataNode 和使用分片规则
例子如下
<schema name="dble_learn" >
<!-- global table -->
<table name="glo_conf" type="global" dataNode="dn7,dn8,dn9,dn10"/>
<!-- 父子表 table -->
<table name="tb_range_shard_par" primaryKey="ID" dataNode="dn7,dn8,dn9,dn10" rule="learn_rule_range">
<childTable name="tb_range_shard" primaryKey="ID" joinKey="ID" parentKey="ID" />
</table>
</schema>
c. 根据<scheam>
中定义 <table>
中的<dataNode>
找到对应dn节点的具体信息
<dataHost name="dataHost1" maxCon="1000" minCon="10" balance="0" switchType="-1" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="db_3307_write" url="li_cvm:3307" user="remote_user" password="remot23">
<!-- can have multi read hosts -->
<readHost host="db_3307_read" url="li_cvm:3307" user="readonly" password="re3"/>
</writeHost>
</dataHost>
<dataHost name="dataHost2" maxCon="1000" minCon="10" balance="0" switchType="-1" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="db_3308_write" url="li_cvm:3308" user="remote_user" password="remo123">
<!-- can have multi read hosts -->
<readHost host="db_3308_read" url="li_cvm:3308" user="readonly" password="re123"/>
</writeHost>
</dataHost>
3. 查看表的拆分规则
a. 在<table>
中的<rule>
指定了使用rule的名字
b. 通过上面的 rule
名字, 在<tableRule>
找打对应的name
c. 通过<tableRule>
找打对应的name 中的<algorithm>
找到对应的 <function>
d. 在<function>
中如果有<mapFile>
则需要在 配置文件目录 (./conf)
下有对应的文件
<tableRule name="learn_rule_range" >
<rule>
<columns>id</columns>
<algorithm>learn_dble_range</algorithm>
</rule>
</tableRule>
<tableRule name="learn_dble_date" >
<rule>
<columns>age</columns>
<algorithm>learn_dble_date</algorithm>
</rule>
</tableRule>
<!-- learn numberrange function -->
<function name="learn_dble_range" class="NumberRange">
<property name="mapFile">learn_dble_range.txt</property>
<property name="defaultNode">-1</property>
</function>
配置时遇到的坑
在使用 NumberRange
的分片算法中的的mapFile
写的模式,中的数据节点是使用该算法的<table>
指定的dataNode
节点的排序进行拆分的如:learn_dble_range.txt文件如下
1-99=0
100-199=1
200-299=2
300-399=3
对应的<table>
中的信息 dataNode
的顺序,注意索引从0开始:
<table name="tb_range_shard_par" primaryKey="ID" dataNode="dn7,dn8,dn9,dn10" rule="learn_rule_range">
其他详情请查看文档
date
分区算法 DBLE的date
算法不是按照日历中自然月时间进行分区的,而是按照将一天转化为86400000毫秒计算。在按照每个分区间隔天数进行计算,得出为第几个分区,如下例子
<function name="partbydate" class="date">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
<property name="sEndDate">2015-01-31</property>
<property name="sPartionDay">10</property>
<property name="defaultNode">0</property>
</function>
各个属性代表意思:
dateFormat:指定⽇期的格式。
sBeginDate:指定⽇期的开始时间。
sEndDate:指定⽇期的结束时间。该性质可以不配置或配置为空("")。
sPartionDay:指定分区的间隔,单位是天。
defaultNode:指定默认节点号。默认值为-1, 不指定默认节点。
举例说明:
当没配置 <sEndDate>
或为""时
第一个区间是从2015-01-01开始后十天都在第一个分片,以此类推 ;
如时间小于<sBeginDate>
则看 是否配置了<defaultNode>
有则分到这里,没有则报错;
如果超过了 sPartionDay*sBeginDate 得日期则会报错
ERROR 1064 (HY000): can't find any valid data node :tb_date_shard -> AGE_DATE -> 2022-08-09 23:59:59
如配置了
<sEndDate>
值
则以<sBeginDate>
开始以<sEndDate>
为结尾,作为一个环形索引;将数据的时间带入公式进行计算:index=((key - sBeginDate)/sPartionDay)%N
得出的index在这个环形索引中找到对应的数据节点
index = ('2015-01-31' - '2015-01-01')/10 =4
如果小于<sBeginDate>
则看是否配置了<defaultNode>
有则分到这里,没有则报错关于公式需要注意的是:
a. 当得出得index小于指定得dataNode数量时,则会忽略没分配到的
dataNode
:如index=3,而dataNode='dn1,dn2,dn3,dn4',那数据不会分到dn4上
b. 如果得出得index大于指定得dataNode
数量时,则会在加载配置时报错
ERROR 1064 (HY000): can't find any valid data node :tb_date_shard -> AGE_DATE -> 2022-08-09 23:59:59
3. 配置文件中的值不能有空格,尤其是关于表,列的值,rule引用等,否则会找不到对应的对象
4. 父表和字表不能是相同名字
