




本文将带你解读Transformer的论文《Attention Is All You Need》,以及Tensorflow中转化器模型的详细实现。


连接所有的部件:Transformer
一旦定义了组件并创建了编码器、解码器和linear-softmax
最终层,就将这些部件连接起来形成模型,即Transformer。
值得一提的是创建了3个掩码,每个掩码都可以:
编码器掩码:它是一个填充掩码,用来丢弃注意力计算中的填充标记。 解码器掩码1:这个掩码是填充掩码和前瞻掩码的结合,它将帮助因果注意丢弃“未来”的标记。取填充掩码和前瞻掩码之间的最大值。 解码器掩码2:它是填充掩码,应用于编码器-解码器注意力层。
class Transformer(tf.keras.Model):
def __init__(self,
vocab_size_enc,
vocab_size_dec,
d_model,
n_layers,
FFN_units,
n_heads,
dropout_rate,
name="transformer"):
super(Transformer, self).__init__(name=name)
# 构建编码器
self.encoder = Encoder(n_layers,
FFN_units,
n_heads,
dropout_rate,
vocab_size_enc,
d_model)
# 构建解码器
self.decoder = Decoder(n_layers,
FFN_units,
n_heads,
dropout_rate,
vocab_size_dec,
d_model)
# 建立线性转换和softmax函数
self.last_linear = layers.Dense(units=vocab_size_dec, name="lin_ouput")
def create_padding_mask(self, seq): #seq: (batch_size, seq_length)
# 创建用于填充的掩码
mask = tf.cast(tf.math.equal(seq, 0), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :]
def create_look_ahead_mask(self, seq):
# 创建因果注意的掩码
seq_len = tf.shape(seq)[1]
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len, seq_len)), -1, 0)
return look_ahead_mask
def call(self, enc_inputs, dec_inputs, training):
# 创建编码器的填充掩码
enc_mask = self.create_padding_mask(enc_inputs)
# 创建因果注意的掩码
dec_mask_1 = tf.maximum(
self.create_padding_mask(dec_inputs),
self.create_look_ahead_mask(dec_inputs)
)
# 为编码器-解码器的注意创建掩码
dec_mask_2 = self.create_padding_mask(enc_inputs)
# 调用编码器
enc_outputs = self.encoder(enc_inputs, enc_mask, training)
# 调用解码器
dec_outputs = self.decoder(dec_inputs,
enc_outputs,
dec_mask_1,
dec_mask_2,
training)
# 调用线性和Softmax函数
outputs = self.last_linear(dec_outputs)
return outputs
正如所看到的,然后调用编码器、解码器和最后的linear-softmax
层,从Transformer模型中得到预测的输出。

训练Transformer模型
现在已经详细描述了论文中的组件,准备实现它们并在一个NMT问题上训练一个Transformer模型。
这里不会在本文中处理数据的问题。总之,创建词汇表,标记(包括eos
和sos
标记),并填充句子。然后创建一个数据集,一个批量数据生成器,用于批量训练。
需要创建一个自定义的损失函数来屏蔽填充的标记。
def loss_function(target, pred):
mask = tf.math.logical_not(tf.math.equal(target, 0))
loss_ = loss_object(target, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
使用论文中描述的Adam优化器,其中beta1=0.9
,beta2=0.98
和epsilon=10e-9
。然后创建一个调度器,根据以下情况改变训练过程中的学习率:
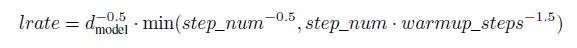
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = tf.cast(d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
主训练函数
train
函数与许多其他Tensorflow训练相似,是一个通常的序列到序列任务的训练循环:
对于批处理生成器上的每次迭代,生成批处理大小的输入和输出 获得从0到length-1的输入序列和从1到length的实际输出,即每一个序列步骤中预期的下一个词。 调用转化器以获得预测结果 计算实际输出和预测值之间的损失函数 应用梯度来更新模型中的权重,同时更新优化器 计算批量数据的平均损失和准确度 在每个历时显示一些结果并保存模型
def main_train(dataset, transformer, n_epochs, print_every=50):
''' Train the transformer model for n_epochs using the data generator dataset'''
losses = []
accuracies = []
# 在每一个epoch中
for epoch in range(n_epochs):
print("Inicio del epoch {}".format(epoch+1))
start = time.time()
# 重置损失和精度计算
train_loss.reset_states()
train_accuracy.reset_states()
# 获得一批输入和目标
for (batch, (enc_inputs, targets)) in enumerate(dataset):
# 设置解码器的输入
dec_inputs = targets[:, :-1]
# 设置目标输出,右移
dec_outputs_real = targets[:, 1:]
with tf.GradientTape() as tape:
# 调用转化器并获得预测的输出
predictions = transformer(enc_inputs, dec_inputs, True)
# 计算损失
loss = loss_function(dec_outputs_real, predictions)
# 更新权重和优化器
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
# 保存并存储指标
train_loss(loss)
train_accuracy(dec_outputs_real, predictions)
if batch % print_every == 0:
losses.append(train_loss.result())
accuracies.append(train_accuracy.result())
print("Epoch {} Lote {} Pérdida {:.4f} Precisión {:.4f}".format(
epoch+1, batch, train_loss.result(), train_accuracy.result()))
# 在每个epoch上对模型进行检查
ckpt_save_path = ckpt_manager.save()
print("Saving checkpoint for epoch {} in {}".format(epoch+1,
ckpt_save_path))
print("Time for 1 epoch: {} secs\n".format(time.time() - start))
return losses, accuracies
就这样有了训练模型的所有必要元素,只需要创建它们并调用训练函数:
# 清理会话
tf.keras.backend.clear_session()
# 创建Transformer模型
transformer = Transformer(vocab_size_enc=num_words_inputs,
vocab_size_dec=num_words_output,
d_model=D_MODEL,
n_layers=N_LAYERS,
FFN_units=FFN_UNITS,
n_heads=N_HEADS,
dropout_rate=DROPOUT_RATE)
# 定义一个分类的交叉熵损失
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction="none")
# 定义一个指标来存储每个历时的平均损失
train_loss = tf.keras.metrics.Mean(name="train_loss")
# 定义一个矩阵来保存每个历时的准确度
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name="train_accuracy")
# 创建学习率衰减的调度器
leaning_rate = CustomSchedule(D_MODEL)
# 创建Adam优化器
optimizer = tf.keras.optimizers.Adam(leaning_rate,
beta_1=0.9,
beta_2=0.98,
epsilon=1e-9)
#创建检查点
ckpt = tf.train.Checkpoint(transformer=transformer,
optimizer=optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print("Las checkpoint restored.")
# 训练模型
losses, accuracies = main_train(dataset, transformer, EPOCHS)

进行预测
当训练一个ML模型时,不仅对优化损失或准确率感兴趣,也希望模型能做出足够好的预测,在这种情况下,看看模型如何处理新句子。predict
函数将向模型输入一个标记化的句子,并返回预测的新句子,在示例中,是一个从英语到西班牙语的翻译。
这些是该过程中的步骤:
将输入的句子符号化为一个符号序列 将最初的输出序列设置为 sos
标记直到达到最大长度或模型返回 eos
标记为止获得下一个词的预测。模型返回logits,记住在损失计算中应用 softmax
函数。获取概率最高的单词在词汇表中的索引 将预测的下一个词与输出序列连接起来
def predict(inp_sentence, tokenizer_in, tokenizer_out, target_max_len):
# 使用tokenizer_in对输入序列进行标记。
inp_sentence = sos_token_input + tokenizer_in.encode(inp_sentence) + eos_token_input
enc_input = tf.expand_dims(inp_sentence, axis=0)
# 设置初始输出句子为sos
out_sentence = sos_token_output
# 重塑输出
output = tf.expand_dims(out_sentence, axis=0)
# 对于最大目标长度的令牌
for _ in range(target_max_len):
# 调用转化器并获得对数
predictions = transformer(enc_input, output, False) #(1, seq_length, VOCAB_SIZE_ES)
# 提取下一个词的对数
prediction = predictions[:, -1:, :]
# 取最高的概率
predicted_id = tf.cast(tf.argmax(prediction, axis=-1), tf.int32)
# 检查它是否是eos标记
if predicted_id == eos_token_output:
return tf.squeeze(output, axis=0)
# 将预测的词与输出的序列相连接
output = tf.concat([output, predicted_id], axis=-1)
return tf.squeeze(output, axis=0)
最后一个函数接收一个英语句子,调用转换器将其翻译成西班牙语,并显示结果。
def translate(sentence):
# 获得输入句子的预测序列
output = predict(sentence, tokenizer_inputs, tokenizer_outputs, MAX_LENGTH).numpy()
# 将标记序列转化为一个句子
predicted_sentence = tokenizer_outputs.decode(
[i for i in output if i < sos_token_output]
)
return predicted_sentence
在这个示例中,只是试验了一些模型维度的值和前馈网络的单位,对模型进行了一个小时的训练。如果想优化模型,可能应该用更长的时间和许多不同的超参数值来训练它。
一些翻译的例子是:
# 展示一些翻译
sentence = "you should pay for it."
print("Input sentence: {}".format(sentence))
predicted_sentence = translate(sentence)
print("Output sentence: {}".format(predicted_sentence))
Input sentence: you should pay for it.
Output sentence: Deberías pagar por ello.
# 展示一些翻译
sentence = "we have no extra money."
print("Input sentence: {}".format(sentence))
predicted_sentence = translate(sentence)
print("Output sentence: {}".format(predicted_sentence))
Input sentence: we have no extra money.
Output sentence: No tenemos dinero extra.
# 展示一些翻译
sentence = "This is a problem to deal with."
print("Input sentence: {}".format(sentence))
predicted_sentence = translate(sentence)
print("Output sentence: {}".format(predicted_sentence))
Input sentence: This is a problem to deal with.
Output sentence: Este problema es un problema con eso.
希望你喜欢尝试使用Transformer模型。
推荐书单

《PyTorch深度学习简明实战》
本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
【半价促销中】购买链接:https://item.jd.com/13512395.html


精彩回顾
《探索Python FastAPI核心功能和CRUD实例讲解》
《知识图谱并不难,用Neo4j和Python打造社交图谱(下)》
《知识图谱并不难,用Neo4j和Python打造社交图谱(中)》
长按关注《Python学研大本营》,加入读者群 长按访问【IT今日热榜】,发现每日技术热点

