




数据分析利器Pandas推出了2.0版本,添加了什么新功能呢?我们一起来看看。

Python Pandas 2.0刚刚发布,以下是增加和改进的内容(这将会改变很多东西)。

如果你从事于数据科学领域(数据工程/科学/ML),可能已经知道Pandas是什么。
但是在谈到数据工程时,Pandas曾经受到很多人的诟病,因为它在处理大型数据集时性能总是不尽如人意。
为了解决性能问题,Pandas 2.0朝着这个方向迈出的重要一步,以下是它的三大特性。
操作更快、更节省内存
Pandas在后端增加了对 PyArrow 的支持。
PyArrow 后端是Pandas 2.0的一个新功能,它能让用户使用Apache Arrow作为Pandas DataFrames和Series的替代数据存储格式。
这意味着,当你在Pandas 2.0中读取或写入Parquet文件时,它将默认使用PyArrow 来处理数据,从而使操作更快,内存效率更高。

什么是PyArrow?
PyArrow 是一个提供列式内存格式的库,它是一种组织数据的方式,使其更容易被读取和并行处理。
在Pandas 2.0中使用PyArrow 后端可以使数据操作更快,内存效率更高,尤其是在处理大型数据集时。
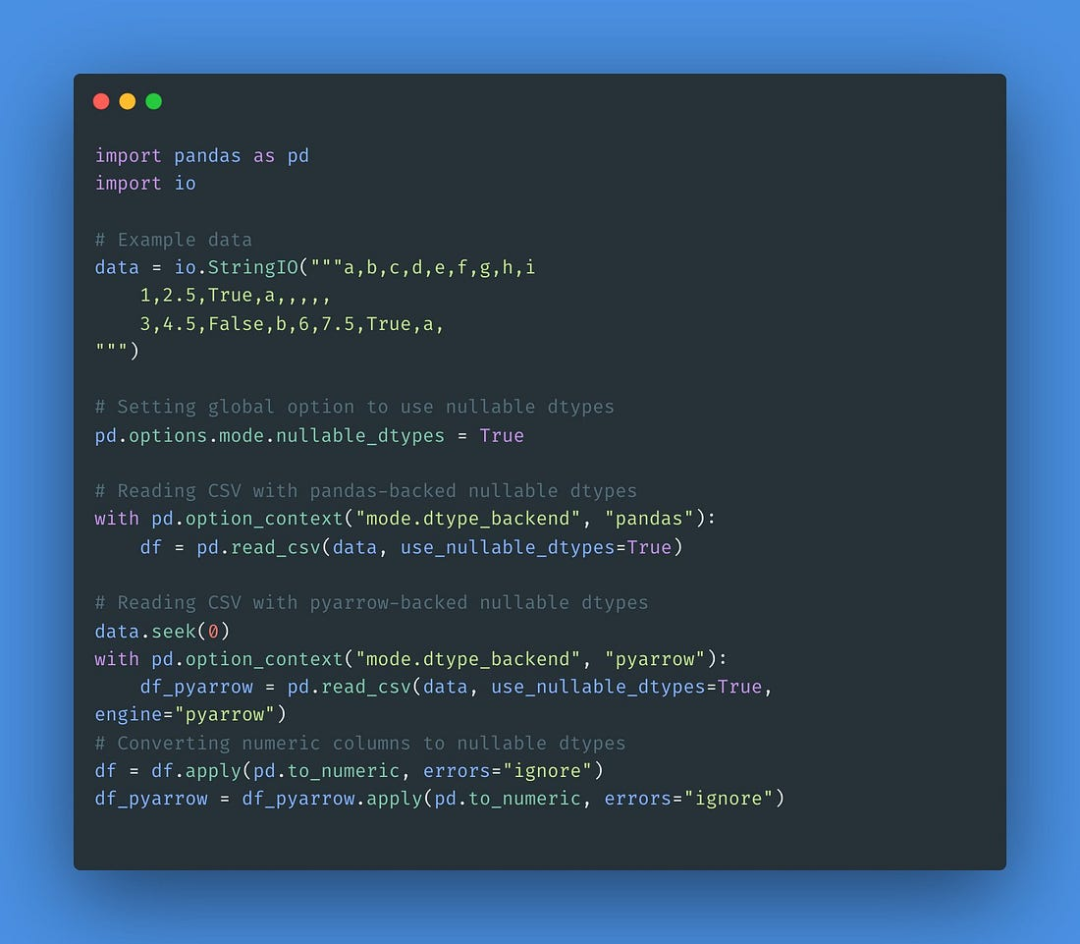
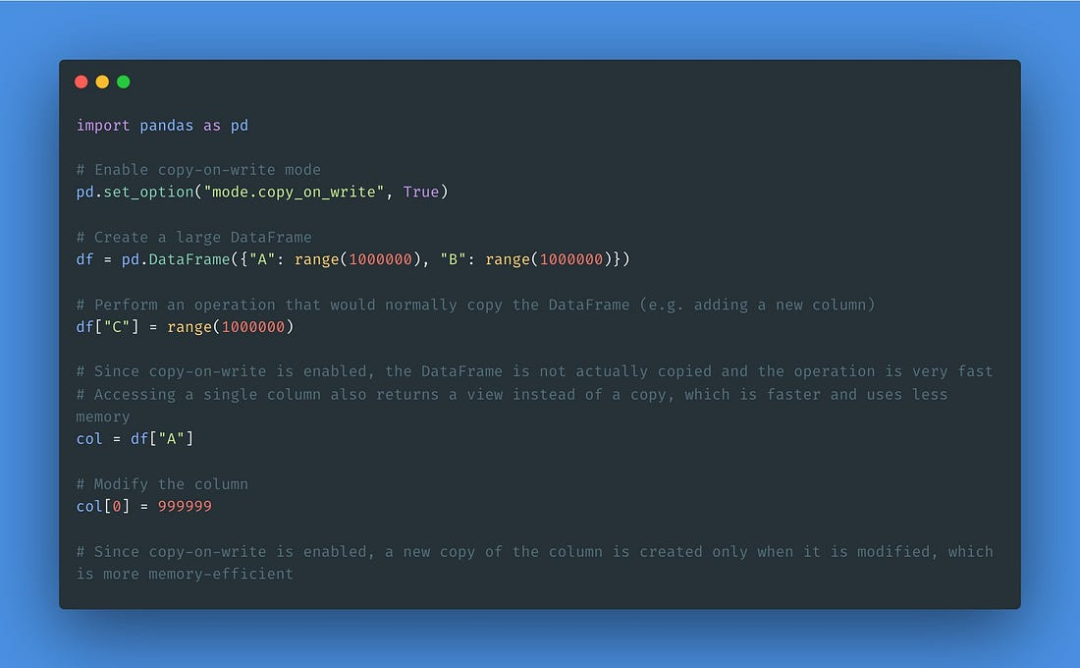
写入时复制的优化
这一新特性类似于Spark执行代码的方式。
这是一种内存优化技术,在Pandas中用来提高性能,减少处理大数据集时的内存使用。
其原理是,当你复制一个Pandas对象,如DataFrame或Series,而不是立即创建一个新的数据副本,Pandas将创建一个对原始数据的引用,推迟创建一个新的副本,直到你以某种方式修改数据。
这意味着,如果你有相同数据的多个副本,它们都可以引用相同的内存,直到你对其中一个进行修改。这可以大大减少内存的使用,提高性能,因为你不需要对数据进行不必要的复制。
总的来说,写时拷贝是一种强大的优化技术,可以帮助你更有效地处理大型数据集,并减少内存。
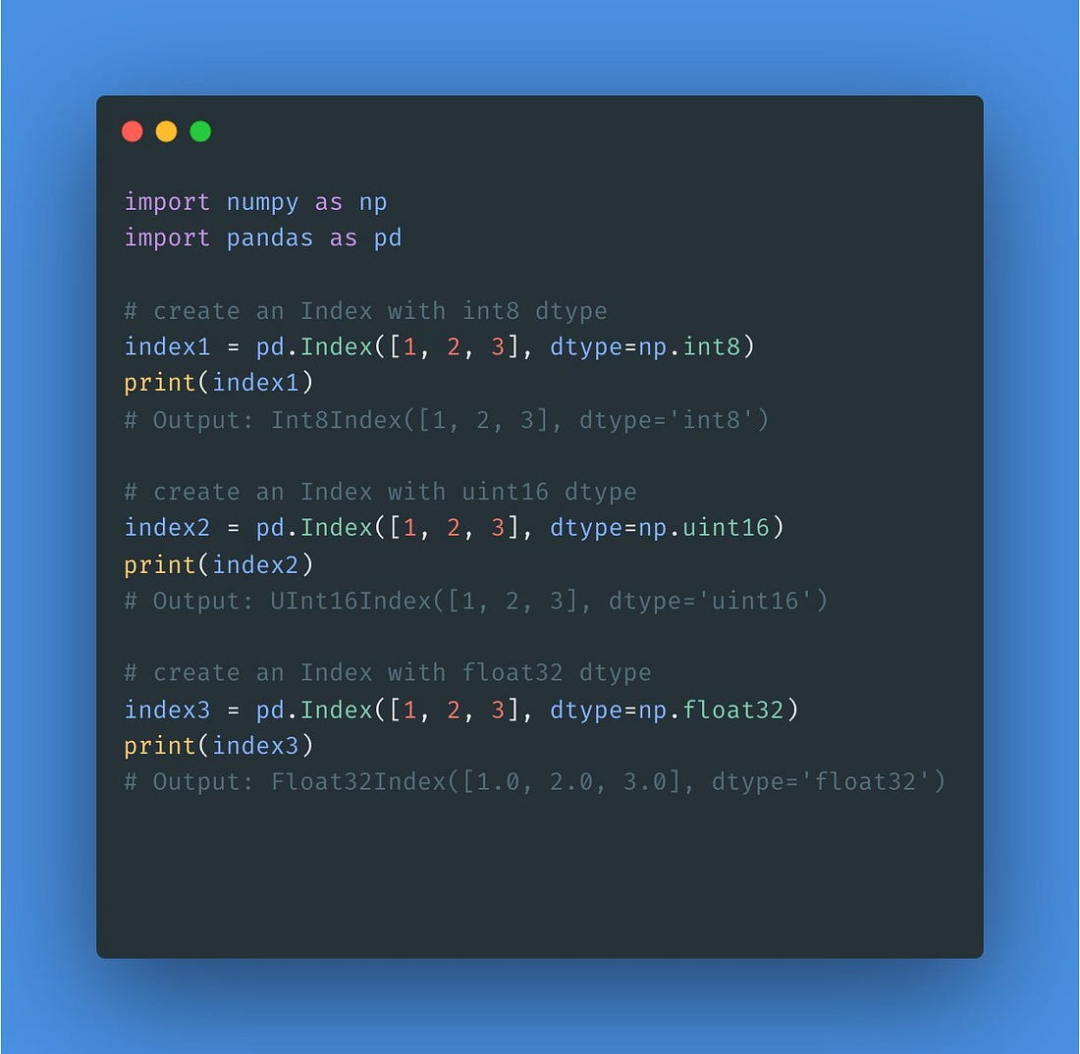
索引可以使用NumPy的数字类型
更好的索引,更快的访问和计算方式。Pandas 2.0允许Index持有任何NumPy的数字类型,包括int8, int16, int32, int64, uint8, uint16, uint32, uint64, float32, 和 float64。以前,只是支持int64、uint64和float64类型。
因此,以前创建64位索引的操作现在可以创建较低位数的索引,如32位索引。
总结
总结一下,
1. Pandas 2.0为后端开发增加了PyArrow,使操作更快、更有内存效率。
2. 新增了写时复制优化,类似于Spark和它执行代码的方式。
3. 索引现在可以容纳NumPy的数字类型,从而使操作更快。
推荐书单
《Pandas1.x实例精解》
《Pandas1.x实例精解》详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
【半价促销中】购买链接:https://item.jd.com/13255935.html


精彩回顾
长按关注《Python学研大本营》,加入读者群
长按访问【IT今日热榜】,发现每日技术热点

