




如何使用 Python 执行探索性数据分析?

这是一篇用Jupyter Notebook 预测心力衰竭数据集分析的简单分步指南。
介绍
在我们构建和训练模型之前,了解我们的数据非常重要,这样我们才能决定使用哪个模型。因此,我们将对预测心力衰竭数据集进行探索性数据分析。该数据集包含 12 个可用于预测心力衰竭死亡率的特征。本研究的目的是预测患者是否在随访期间死亡。
概述
在本文中,我们想讨论:
探索性数据分析的目的。 如何开始探索性数据分析以及如何获得数据的初步概览。 如何执行单变量和双变量分析。
探索性数据分析
探索性数据分析,简称 EDA,被定义为一种分析数据集以总结其主要特征的方法。EDA的目的是:
发现数据集中的模式。 发现异常。 形成关于数据行为的假设。 验证假设。
第 1 步:导入库和数据集
第一步是导入所需的库。最重要的是 Pandas(用于数值表和系列的数据操作和分析)和 Numpy 库(用于大型、多维数组和矩阵)。

图 1:导入库
之后,我们需要将保存在桌面上的 csv 文件读取到 DataFrame 中:

图 2:将 CSV 文件读入 Dataframe
第 2 步:数据集的初步概述 使用df.head()可以查看 DataFrame 的前五行:

图 3:前五行
使用df.tail()显示 DataFrame 的最后五行:

图 4:最后五行
为了更好地了解数据集的形状,df.shape提供了观察数(行)和特征数(列):

表 1:数据集的行数和列数
要查找每列中的缺失值以及值的数据类型,我们使用df.info():
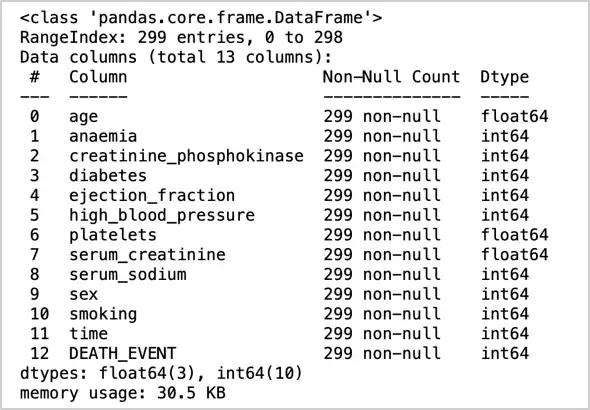
图 5:值的数据类型
正如我们所见,没有列有缺失值,数据只有浮点值和整数值。
共有三种不同类型的分析:
单变量分析。 双变量分析。 多元分析。我们将从单变量分析开始,这是分析数据的最简单形式。
第三步:单变量分析
单变量分析的主要目的是获取数据、汇总数据并找到值之间的模式。它包括集中趋势(均值、众数和中位数)和分散(范围、方差、最大和最小四分位数以及标准差)。要获取 DataFrame 中所有数字列的基本汇总统计信息,我们将使用df.describe():
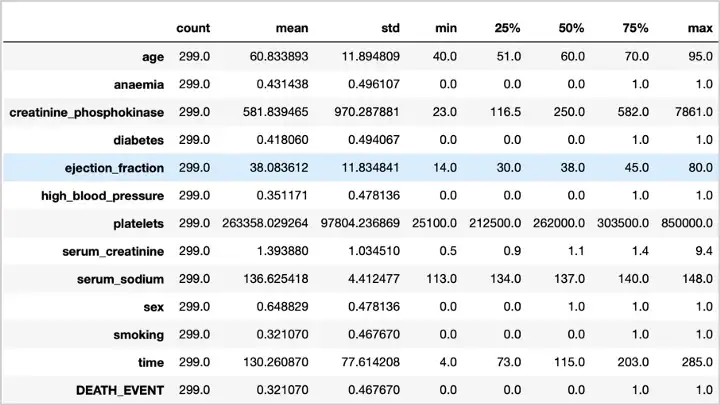
图 6:描述性统计
贫血、糖尿病、高血压和吸烟等特征并不是真正的数字特征。事实上,它们具有绝对性质。对于分类特征,df.describe()不包括描述性统计数据,如均值和标准差。总体而言,数值属性的均值大于中值。因此,分布呈正偏态。
目标变量
在下一节中,我们将分析目标变量。目标变量死亡事件是离散的,是一个分类问题。
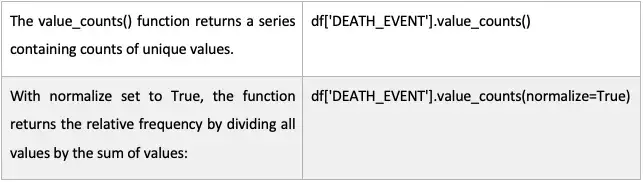
表 2:函数 value_count()
函数的结果按降序排列。因此,第一个元素是最常出现的元素。

表 3:频率表死亡事件
为了可视化有多少患者幸存下来以及有多少患者死亡,我们将使用条形图,其中每个条形代表一个变量的单个离散值,条形的高度等于数据点的数量。
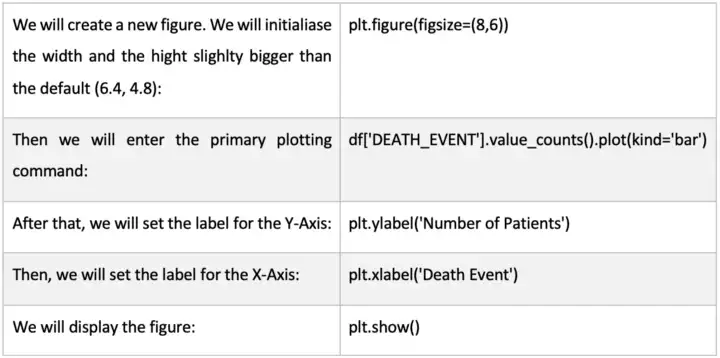
表 4:绘图
根据条形图,我们可以看到只有 1/3 的患者或 96 名患者 (32.11%) 死于心力衰竭,而 2/3 的患者或 203 名患者 (67.89%) 存活下来。它还向我们表明分布略微不平衡。在拟合模型时,这可能会导致类不平衡问题。
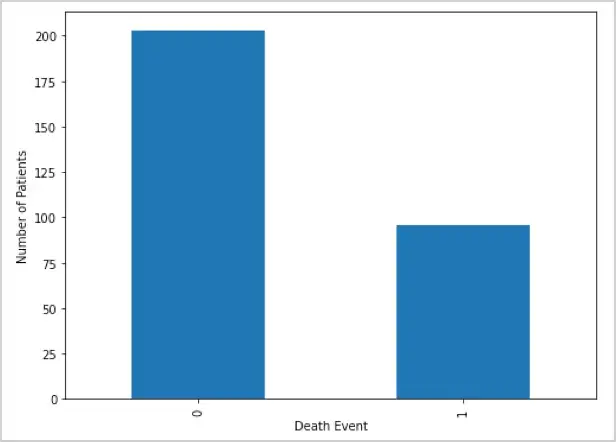
图 7:存活和死亡患者的频率
自变量年龄
我们将使用 Pandas DataFrame.hist() 输出直方图并显示年龄值的分布:

图 8:创建直方图
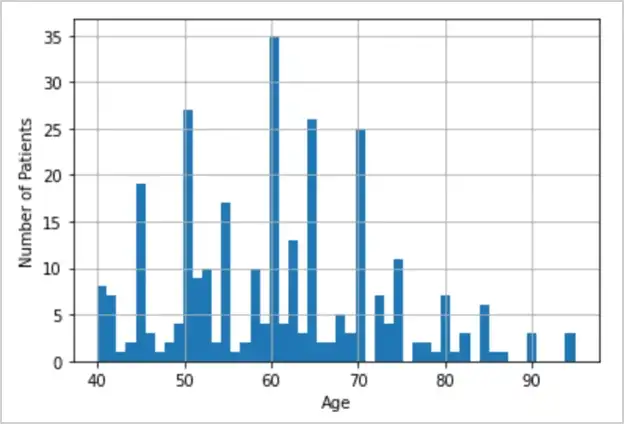
图 9:柱龄柱状图
60 至 70 岁的患者数量最多。年龄从40岁到95岁不等。之后,我们还将从年龄列绘制一个箱线图:

图 10:绘制柱龄箱线图
箱线图显示第一个百分位数(矩形的下边缘)、第三个百分位数(矩形的上边缘)、中位数(绿线)以及矩形上方和下方的点表示离群值。
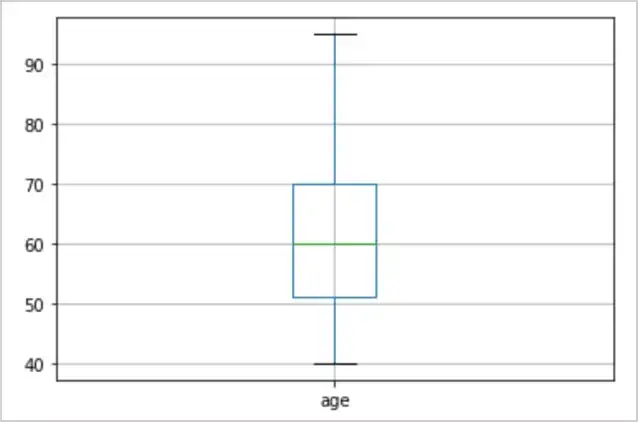
图 11:柱龄箱线图
25% 的患者年龄在 50 岁以下(25% 百分位数)。 50% 的患者年龄在 60 岁以下(中位数)。 75% 的患者年龄在 70 岁以下(75% 百分位数)。
其他自变量
不仅目标变量具有分类性质,而且其他一些自变量也具有分类性质。我们将查看每个值的计数,以了解每个类别在数据集中的表现情况。我们将使用value_counts()函数来查找分类特征性别、贫血、高血压、糖尿病和吸烟者的频率。频率如下:
超过 60% 的患者为男性,不到 40% 的患者为女性。 超过一半的患者患有贫血。 超过 60% 的患者患有高血压,而只有不到 40% 的患者没有高血压。 几乎 60% 的患者患有糖尿病。 几乎 70% 的患者是吸烟者。
附录:
完整代码:https://github.com/SteffiPGalway/ExploratoryDataAnalysis

推荐书单
《PyTorch深度学习简明实战 》

本书针对深度学习及开源框架——PyTorch,采用简明的语言进行知识的讲解,注重实战。全书分为4篇,共19章。深度学习基础篇(第1章~第6章)包括PyTorch简介与安装、机器学习基础与线性回归、张量与数据类型、分类问题与多层感知器、多层感知器模型与模型训练、梯度下降法、反向传播算法与内置优化器。计算机视觉篇(第7章~第14章)包括计算机视觉与卷积神经网络、卷积入门实例、图像读取与模型保存、多分类问题与卷积模型的优化、迁移学习与数据增强、经典网络模型与特征提取、图像定位基础、图像语义分割。自然语言处理和序列篇(第15章~第17章)包括文本分类与词嵌入、循环神经网络与一维卷积神经网络、序列预测实例。生成对抗网络和目标检测篇(第18章~第19章)包括生成对抗网络、目标检测。
本书适合人工智能行业的软件工程师、对人工智能感兴趣的学生学习,同时也可作为深度学习的培训教程。
作者简介:
日月光华:网易云课堂资深讲师,经验丰富的数据科学家和深度学习算法工程师。擅长使用Python编程,编写爬虫并利用Python进行数据分析和可视化。对机器学习和深度学习有深入理解,熟悉常见的深度学习框架( PyTorch、TensorFlow)和模型,有丰富的深度学习、数据分析和爬虫等开发经验,著有畅销书《Python网络爬虫实例教程(视频讲解版)》。
购买链接(新书限时5.5折):https://item.jd.com/13528847.html

精彩回顾
长按关注《Python学研大本营》 长按二维码,加入Python读者群

