torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device)
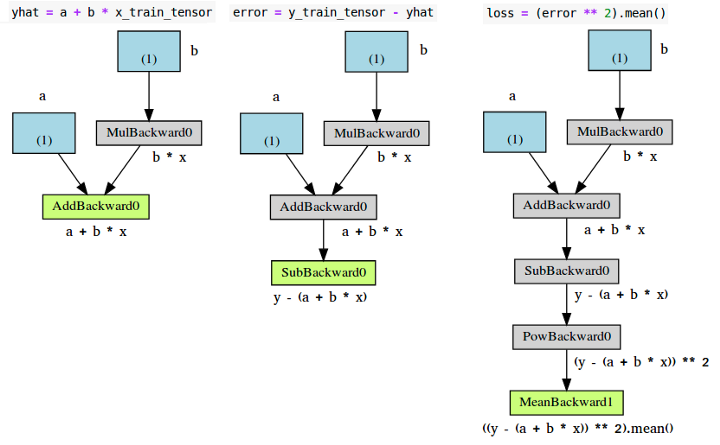
for epoch in range(n_epochs): yhat = a + b * x_train_tensor error = y_train_tensor - yhat loss = (error ** 2).mean()
# No more manual computation of gradients! # a_grad = -2 * error.mean() # b_grad = -2 * (x_tensor * error).mean()
# We just tell PyTorch to work its way BACKWARDS from the specified loss! loss.backward() # Let's check the computed gradients... print(a.grad) print(b.grad)
# What about UPDATING the parameters? Not so fast...
# FIRST ATTEMPT # AttributeError: 'NoneType' object has no attribute 'zero_' # a = a - lr * a.grad # b = b - lr * b.grad # print(a)
# SECOND ATTEMPT # RuntimeError: a leaf Variable that requires grad has been used in an in-place operation. # a -= lr * a.grad # b -= lr * b.grad
# THIRD ATTEMPT # We need to use NO_GRAD to keep the update out of the gradient computation # Why is that? It boils down to the DYNAMIC GRAPH that PyTorch uses... with torch.no_grad(): a -= lr * a.grad b -= lr * b.grad
# PyTorch is "clingy" to its computed gradients, we need to tell it to let it go... a.grad.zero_() b.grad.zero_()
torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) print(a, b)
lr = 1e-1 n_epochs = 1000
# Defines a SGD optimizer to update the parameters optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs): yhat = a + b * x_train_tensor error = y_train_tensor - yhat loss = (error ** 2).mean()
loss.backward()
# No more manual update! # with torch.no_grad(): # a -= lr * a.grad # b -= lr * b.grad optimizer.step()
# No more telling PyTorch to let gradients go! # a.grad.zero_() # b.grad.zero_() optimizer.zero_grad()
print(a, b)
让我们检查一下之前和之后的两个参数,以确保一切正常:
# BEFORE: a, b tensor([0.6226], device='cuda:0', requires_grad=True) tensor([1.4505], device='cuda:0', requires_grad=True) # AFTER: a, b tensor([1.0235], device='cuda:0', requires_grad=True) tensor([1.9690], device='cuda:0', requires_grad=True)
torch.manual_seed(42) a = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) b = torch.randn(1, requires_grad=True, dtype=torch.float, device=device) print(a, b)
lr = 1e-1 n_epochs = 1000
# Defines a MSE loss function loss_fn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs): yhat = a + b * x_train_tensor
# No more manual loss! # error = y_tensor - yhat # loss = (error ** 2).mean() loss = loss_fn(y_train_tensor, yhat)