




我们将探索量化和可视化分类数据。
目录

分 类 数 据
我们可以将数据大致分为日期值、连续值和分类值。在本节中,我们将探索量化和可视化分类数据。
实战操作
(1)选择具有object数据类型的列。
>>> fueleco.select_dtypes(object).columns
Index(['drive', 'eng_dscr', 'fuelType', 'fuelType1', 'make', 'model',
'mpgData', 'trany', 'VClass', 'guzzler', 'trans_dscr', 'tCharger',
'sCharger', 'atvType', 'fuelType2', 'rangeA', 'evMotor', 'mfrCode',
'c240Dscr', 'c240bDscr', 'createdOn', 'modifiedOn', 'startStop'],
dtype='object')
(2)使用.nunique方法确定基数。
>>> fueleco.drive.nunique()
7
(3)使用.sample方法查看一些值。
>>> fueleco.drive.sample(5, random_state=42)
4217 4-Wheel ...
1736 4-Wheel ...
36029 Rear-Whe...
37631 Front-Wh...
1668 Rear-Whe...
Name: drive, dtype: object
(4)确定缺失值的数量和百分比。
>>> fueleco.drive.isna().sum()
1189
>>> fueleco.drive.isna().mean() * 100
3.0408429451932175
(5)使用.value_counts方法汇总一列。
>>> fueleco.drive.value_counts()
Front-Wheel Drive 13653
Rear-Wheel Drive 13284
4-Wheel or All-Wheel Drive 6648
All-Wheel Drive 2401
4-Wheel Drive 1221
2-Wheel Drive 507
Part-time 4-Wheel Drive 198
Name: drive, dtype: int64
(6)如果摘要中的值太多,则可能要查看前6个值并折叠其余值。
>>> top_n = fueleco.make.value_counts().index[:6]
>>> (
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... ).make.value_counts()
... )
Other 23211
Chevrolet 3900
Ford 3208
Dodge 2557
GMC 2442
Toyota 1976
BMW 1807
Name: make, dtype: int64
(7)使用Pandas绘制计数并将其可视化。
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> top_n = fueleco.make.value_counts().index[:6]
>>> (
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... )
... .make.value_counts()
... .plot.bar(ax=ax)
... )
>>> fig.savefig("c5-catpan.png", dpi=300)
其输出结果如图5-1所示。
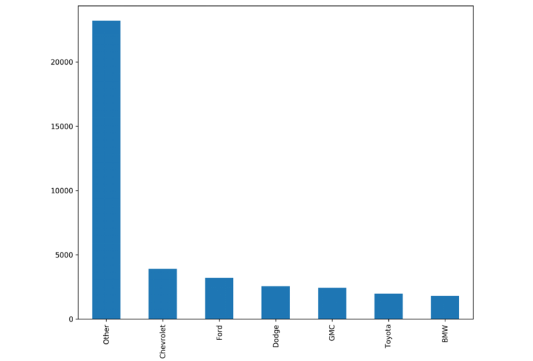
图5-1 使用Pandas可视化分类
(8)使用seaborn绘制计数并将其可视化。
>>> import seaborn as sns
>>> fig, ax = plt.subplots(figsize=(10, 8))
>>> top_n = fueleco.make.value_counts().index[:6]
>>> sns.countplot(
... y="make",
... data=(
... fueleco.assign(
... make=fueleco.make.where(
... fueleco.make.isin(top_n), "Other"
... )
... )
... ),
... )
>>> fig.savefig("c5-catsns.png", dpi=300)
其输出结果如图5-2所示。
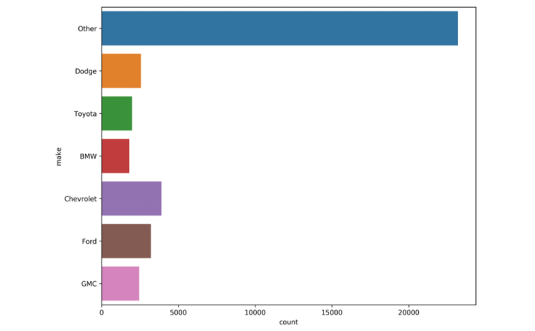
图5-2 使用Seaborn可视化分类
原理解释
当检查分类变量时,我们想知道有多少个唯一值。如果这是一个很大的值,则该列可能不是分类的,而是自由文本或数字列(这可能是因为Pandas遇到无效的数字,Pandas不知道如何将其存储为数字)。
.sample方法可以让我们对某些值做一些研究。对于大多数列来说,确定有多少缺失值很重要。看起来好像有超过1000行,或大约3%的缺失值。一般来说,我们需要与行业专家(SME)进行交流,以确定为什么会有这些缺失值,以及是否需要评估或丢弃它们。
下面就来研究drive缺失的行。
>>> fueleco[fueleco.drive.isna()]
barrels08 barrelsA08 ... phevHwy phevComb
7138 0.240000 0.0 ... 0 0
8144 0.312000 0.0 ... 0 0
8147 0.270000 0.0 ... 0 0
18215 15.695714 0.0 ... 0 0
18216 14.982273 0.0 ... 0 0
... ... ... ... ... ...
23023 0.240000 0.0 ... 0 0
23024 0.546000 0.0 ... 0 0
23026 0.426000 0.0 ... 0 0
23031 0.426000 0.0 ... 0 0
23034 0.204000 0.0 ... 0 0
我们最喜欢使用的检查分类列的方法是.value_counts方法,这是一个很好的起点,因为可以从该方法的输出中找到许多其他问题的答案。默认情况下,.value_counts方法不显示缺失值,但是可以使用dropna参数来解决此问题。
>>> fueleco.drive.value_counts(dropna=False)
Front-Wheel Drive 13653
Rear-Wheel Drive 13284
4-Wheel or All-Wheel Drive 6648
All-Wheel Drive 2401
4-Wheel Drive 1221
NaN 1189
2-Wheel Drive 507
Part-time 4-Wheel Drive 198
Name: drive, dtype: int64
最后,可以使用Pandas或Seaborn可视化此输出。条形图是执行此操作的合适图。但是,如果这是基数较高的列,则对于有效图而言,可能有太多条形。你可以按照步骤(6)中的操作来限制列数。在使用Seaborn的情况下,则可以使用countplot的order参数。
使用Pandas可以进行快速绘图,因为这通常是一个方法调用。当然,Seaborn库也有自己的特色技巧并且是在Pandas中不容易做到的,在后面的秘笈中将会看到这一点。
扩展知识
某些列报告为object数据类型,但此类列并不是真正的分类。在此数据集中,rangeA列具有object数据类型。但是,如果使用分类方法 .value_counts进行检查,则会发现rangeA并不是真正的分类,而是一个貌似分类的数字列。
这是因为,正如我们从.value_counts方法的输出中看到的那样,某些条目中有斜杠(/)和短横(-),而Pandas不知道如何将这些值转换为数字,因此它将整列保留为字符串列。
>>> fueleco.rangeA.value_counts()
290 74
270 56
280 53
310 41
277 38
..
328 1
250/370 1
362/537 1
310/370 1
340-350 1
Name: rangeA, Length: 216, dtype: int64
查找特殊字符的另一种方法是使用.str.extract方法(该方法可以使用正则表达式)。
>>> (
... fueleco.rangeA.str.extract(r"([^0-9.])")
... .dropna()
... .apply(lambda row: "".join(row), axis=1)
... .value_counts()
... )
/ 280
- 71
Name: rangeA, dtype: int64
这意味着rangeA列实际上具有两种类型,即float和string。其数据类型被报告为object,因为该类型可以包含异构类型的列。缺失值被存储为NaN,而非缺失值则是字符串。
>>> set(fueleco.rangeA.apply(type))
{<class 'str'>, <class 'float'>}
以下是缺失值的计数。
>>> fueleco.rangeA.isna().sum()
37616
根据fueleconomy.gov网站的数据,rangeA列值表示混合动力车辆的第二种燃料类型的范围(包括E85、电力、天然气和液化石油气等)。使用Pandas时,可以将缺失值替换为0,将短横(-)替换为斜杠(/),然后拆分并取每一行的平均值(在出现了短横/斜杠的情况下)。
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... )
0 0.0
1 0.0
2 0.0
3 0.0
4 0.0
...
39096 0.0
39097 0.0
39098 0.0
39099 0.0
39100 0.0
Length: 39101, dtype: float64
还可以通过对数字列进行分箱(binning)处理来将它们视为分类。Pandas有两个强大的函数来辅助划分,即cut和qcut。可以使用cut函数来切成等宽的箱子或由我们指定箱子的宽度。对于rangeA列来说,大多数值都是空的,所以可将该列值替换为0,并据此划分为10个等宽的箱子。具体划分如下。
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... .pipe(lambda ser_: pd.cut(ser_, 10))
... .value_counts()
... )
(-0.45, 44.95] 37688
(269.7, 314.65] 559
(314.65, 359.6] 352
(359.6, 404.55] 205
(224.75, 269.7] 181
(404.55, 449.5] 82
(89.9, 134.85] 12
(179.8, 224.75] 9
(44.95, 89.9] 8
(134.85, 179.8] 5
dtype: int64
另外,qcut函数—表示分位数剪切(quantile cut)—会将条目切成相同大小的箱子。但是,由于rangeA列严重偏斜,并且大多数条目为0,而我们无法将0量化到多个箱子中,因此这种方法是失败的。但是它确实(某种程度上)适用于city08。之所以出现这种情况是因为city08的值是整数,因此它们不会平均划分到10个存储桶中,但是大小很接近。
>>> (
... fueleco.rangeA.fillna("0")
... .str.replace("-", "/")
... .str.split("/", expand=True)
... .astype(float)
... .mean(axis=1)
... .pipe(lambda ser_: pd.qcut(ser_, 10))
... .value_counts()
... )
Traceback (most recent call last):
...
ValueError: Bin edges must be unique: array([ 0. , 0. , 0. , 0.,
0. , 0. , 0. , 0. , 0. ,
0. , 449.5]).
>>> (
... fueleco.city08.pipe(
... lambda ser: pd.qcut(ser, q=10)
... ).value_counts()
... )
(5.999, 13.0] 5939
(19.0, 21.0] 4477
(14.0, 15.0] 4381
(17.0, 18.0] 3912
(16.0, 17.0] 3881
(15.0, 16.0] 3855
(21.0, 24.0] 3676
(24.0, 150.0] 3235
(13.0, 14.0] 2898
(18.0, 19.0] 2847
Name: city08, dtype: int64
推荐书单
《Pandas1.x实例精解》

本书详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
购买链接:https://u.jd.com/9IOYicg

精彩回顾
长按关注《Python学研大本营》 长按二维码,加入Python读者群

