




本期主要介绍如何在R语言中计算全局莫兰指数(Global Moran'I)。更多内容可关注微信公众号【日常分享的小懒猫】。
全局莫兰指数(Global Moran's I) 可用来反映自然或社会要素在空间上的关联程度,是揭示其空间分布规律的一种空间统计方法,Global Moran's I取值范围为[-1, 1],大于0为正相关,小于0为负相关,等于0表示随机分布,其计算公式可参考文献(周扬等,2022[1])。

1、数据准备
对于全局莫兰指数的计算,需要准备两份数据:分别为空间权重矩阵数据以及要计算的指标数据。本文以我国31个省份的空间邻接0-1矩阵为例(相邻表示1,不相近为0),计算2001-2020年31个省份的人均GDP全局莫兰指数。其中,空间矩阵邻接0-1矩阵为对称矩阵形式的矩阵,人均GDP数据为面板形式。注意矩阵的省份顺序应于指标数据的省份顺序保持一致。
1.1 读入空间权重矩阵
#微信公众号:日常分享的小懒猫
install.packages("ape")
library(ape)
library(dplyr)
W <- read.csv("空间权重矩阵.csv", row.names = "VAR")
W <- as.matrix(W)
W
head(W)
# 北京 天津 河北 山西 内蒙古 辽宁 吉林 黑龙江 上海 江苏 浙江 安徽 福建 江西 山东 河南 湖北 湖南 广东 广西 海南 重庆 四川 贵州 云南 西藏 陕西 甘肃 青海 宁夏 新疆
#北京 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#天津 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#河北 1 1 0 1 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#山西 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
#内蒙古 0 0 1 1 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0
#辽宁 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1.2读入数据
GDP_df <- readxl::read_xlsx("面板数据.xlsx")
head(GDP_df)
# ID province region year GDP
# <dbl> <chr> <chr> <dbl> <dbl>
#1 1 北京 东部地区 2020 164889
#2 2 天津 东部地区 2020 101614
#3 3 河北 东部地区 2020 48564
#4 4 山西 中部地区 2020 50528
#5 5 内蒙古 西部地区 2020 72062
#6 6 辽宁 东北地区 2020 58872
2、计算截面数据的莫兰指数
全局莫兰指数的计算可利用ape包中的Moran.I() 函数进行计算。
Moran.I(x, weight, scaled = FALSE, na.rm = FALSE,
alternative = "two.sided")
其中,x为待计算的指标数据,weight为空间权重矩阵,scaled表示是否对系数进行标准化。
2.1计算
#微信公众号:日常分享的小懒猫
GDP_2017 <- GDP_df %>% filter(year == "2017")
Moran.I(GDP_2017$GDP, W)
2.2 结果
结果共有4个参数,分别为observed、expected、sd、p.value,表示莫兰指数及其对象的期望、方差以及p值。
$observed
[1] 0.3646392
$expected
[1] -0.03333333
$sd
[1] 0.1124035
$p.value
[1] 0.0003992633
可以看出,对于2017年的人均GDP,全局莫兰指数为0.3646392,并且p值小于0.01,具有显著的空间自相关效应。
3、计算面板数据的莫兰指数
对于面板形式的数据,可以按照一年一个数据进行计算,但过程麻烦。而利用循环进行计算,则具有更大的便利性,可以大量节省时间。因此,本文主要展示如何利用R语言中的循环函数对多年形式的面板数据进行全局莫兰指数的一次计算,以及导出计算结果。
3.1 全局莫兰指数计算
Moran_all <- tapply(GDP_df$GDP, GDP_df$year, Moran.I, W)
Moran_all
结果
$`2001`
$`2001`$observed
[1] 0.3250341
$`2001`$expected
[1] -0.03333333
$`2001`$sd
[1] 0.1052729
$`2001`$p.value
[1] 0.0006636421
$`2002`
$`2002`$observed
[1] 0.32981
$`2002`$expected
[1] -0.03333333
$`2002`$sd
[1] 0.1059336
$`2002`$p.value
[1] 0.0006079849
观察Moran_all结果可以发现,该结果为一个列表,里面存放了每一年的莫兰指数以及对应的期望、方差、P值等数据,因此接下来利用for循环对数据结果进行提取。
3.2 利用for循环提取列表数据
#微信公众号:日常分享的小懒猫
moran_dat = data.frame()
for (i in names(Moran_all)){
moran_df = data.frame(year = i,
moran = Moran_all[[i]][[1]],
expected = Moran_all[[i]][[2]],
sd = Moran_all[[i]][[3]],
p.value = Moran_all[[i]][[4]] )
moran_dat = rbind(moran_dat, moran_df)
}
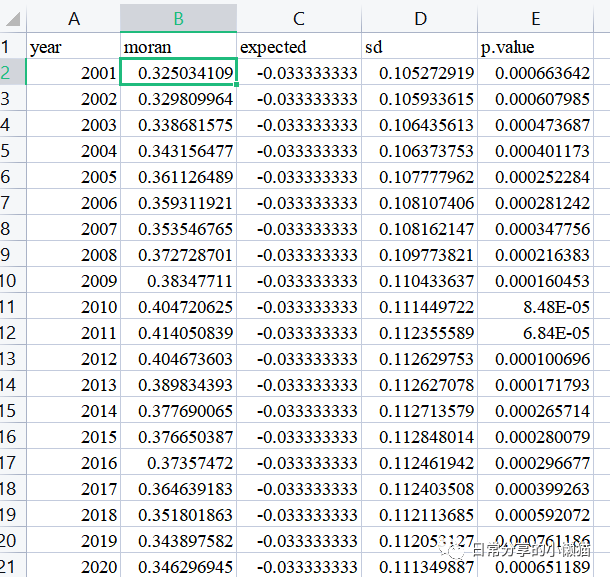
moran_dat
# year moran expected sd p.value
#1 2001 0.3250341 -0.03333333 0.1052729 6.636421e-04
#2 2002 0.3298100 -0.03333333 0.1059336 6.079849e-04
#3 2003 0.3386816 -0.03333333 0.1064356 4.736874e-04
#4 2004 0.3431565 -0.03333333 0.1063738 4.011727e-04
#5 2005 0.3611265 -0.03333333 0.1077780 2.522839e-04
#6 2006 0.3593119 -0.03333333 0.1081074 2.812416e-04
#7 2007 0.3535468 -0.03333333 0.1081621 3.477556e-04
#8 2008 0.3727287 -0.03333333 0.1097738 2.163833e-04
#9 2009 0.3834771 -0.03333333 0.1104336 1.604531e-04
#10 2010 0.4047206 -0.03333333 0.1114497 8.476678e-05
#11 2011 0.4140508 -0.03333333 0.1123556 6.837819e-05
#12 2012 0.4046736 -0.03333333 0.1126298 1.006956e-04
#13 2013 0.3898344 -0.03333333 0.1126271 1.717931e-04
#14 2014 0.3776901 -0.03333333 0.1127136 2.657142e-04
#15 2015 0.3766504 -0.03333333 0.1128480 2.800787e-04
#16 2016 0.3735747 -0.03333333 0.1124619 2.966769e-04
#17 2017 0.3646392 -0.03333333 0.1124035 3.992633e-04
#18 2018 0.3518019 -0.03333333 0.1121137 5.920725e-04
#19 2019 0.3438976 -0.03333333 0.1120531 7.611857e-04
#20 2020 0.3462969 -0.03333333 0.1113499 6.511886e-04
3.3 写出
write.csv(moran_dat, file = "moran_dat.csv")
4、其他
其他研究方法或绘图方法可进一步阅读公众号【日常分享的小懒猫】 上的文章,欢迎关注转发分享。完整数据及代码
如有帮助请多多点赞哦!
参考资料
周扬,黄晗,刘彦随: 中国村庄空间分布规律及其影响因素[J].地理学报,2020,75(10):2206-2223.
