




背景:
路径分析,就是把用户在APP或者网站等的访问行为流转, 多用来辅助分析用户行为偏好、优化改进产品设计。大部分第三方数据平台都会直接提供路径分析的功能,比如国内的神策,海外的Google Analytics。但是如果因为条件所限无法使用这些平台,或者觉得这些平台提供的路径分析局限性比较大,我们也可以基于用户的原始行为数据,用SQL一步步徒手做出来路径分析,并作桑基图。
首先仍然假设我们有一张这样的用户行为数据表events:event,user_id,time,
即包含用户id,事件名和时间。
本文会包括的内容:
1首先选择路径中要包含的事件,并形成session。
2根据分析目的进行路径分析。
3.路径分析畅想

为什么会有这么多session查询的文章,后边的每篇是对前序文章的修正和补充。
本文在之前session的逻辑基础上,获取了每个session的session_id,在session中的位置,当前事件名,时间,当前事件的后一个事件和前一个事件名,以方便后续计算。如对session逻辑较为清楚,可仅查看输出的session表的数据表结构,然后跳过此环节。
以下SQL代码参考:
select session_id,sess_position as rank,event as current_node,time1,lead(event) over (partition by session_id order by time asc) as target_node,lag(event) over (partition by session_id order by time asc) as qianyige_nodefrom(select sess_1st.user_id,concat(cast(sess_1st.user_id as string),'-',cast(sess_1st.session_id as string)) as session_id,sess_1st.currentsession_starttime,sess_1st.currentsession_endtime,sess_1st.currentsession_endtime-sess_1st.currentsession_starttime as sess_length,a.time,a.time1,a.event,row_number() over (partition by sess_1st.user_id,sess_1st.session_id order by a.time asc) as sess_position,count() over (partition by sess_1st.user_id,sess_1st.session_id) as sess_depth,a.lenfrom(select user_id,event,time,max_time,currentsession_starttime,if(lead(beforesession_endtime,1) over (PARTITION BY user_id ORDER BY time asc) is null,max_time,lead(beforesession_endtime,1) over (PARTITION BY user_id ORDER BY time asc)) as currentsession_endtime,row_number() over (partition by user_id order by time asc) as session_idfrom(SELECTuser_id,event,time,max_time,if (a.end_time - a.begin_time is null or a.end_time - a.begin_time>1200,1 , 0) as se,if (a.end_time - a.begin_time is null or a.end_time - a.begin_time>1200,lag(EXTRACT(EPOCH FROM time),1,null) over (PARTITION BY user_id ORDER BY time asc),null) as beforesession_endtime,if (a.end_time - a.begin_time is null or a.end_time - a.begin_time>1200,EXTRACT(EPOCH FROM time),null) as currentsession_starttimeFROM(SELECT user_id,event,time,EXTRACT(EPOCH FROM time) AS end_time,lag(EXTRACT(EPOCH FROM time),1,null) over (PARTITION BY user_id ORDER BY time asc) AS begin_time,max(EXTRACT(EPOCH FROM time)) over (PARTITION BY user_id) as max_timeFROM eventsWHERE to_date(time)='2023-04-05' andevent in ('$AppStart','inRoom','CommodityDetail','AddToShoppingCart','roomaddToCart'))aorder by user_id,time asc)sess where se=1)sess_1stleft join(SELECTuser_id,event,time,a.end_time - a.begin_time,EXTRACT(EPOCH FROM time) as time1,case when a.end_time - a.begin_time<=1200 then a.end_time-a.begin_time else null end as lenFROM(SELECT user_id,event,time,EXTRACT(EPOCH FROM time) AS begin_time,lead(EXTRACT(EPOCH FROM time),1,null) over (PARTITION BY user_id ORDER BY time asc) AS end_timeFROM eventsWHERE to_date(time)='2023-04-05' andevent in ('$AppStart','inRoom','CommodityDetail','AddToShoppingCart','roomaddToCart'))aorder by user_id,time asc)aon sess_1st.user_id=a.user_id and a.time1>=sess_1st.currentsession_starttime and a.time1<=sess_1st.currentsession_endtimeorder by a.user_id,a.time asc)a
输出结果命名为session表,如下:
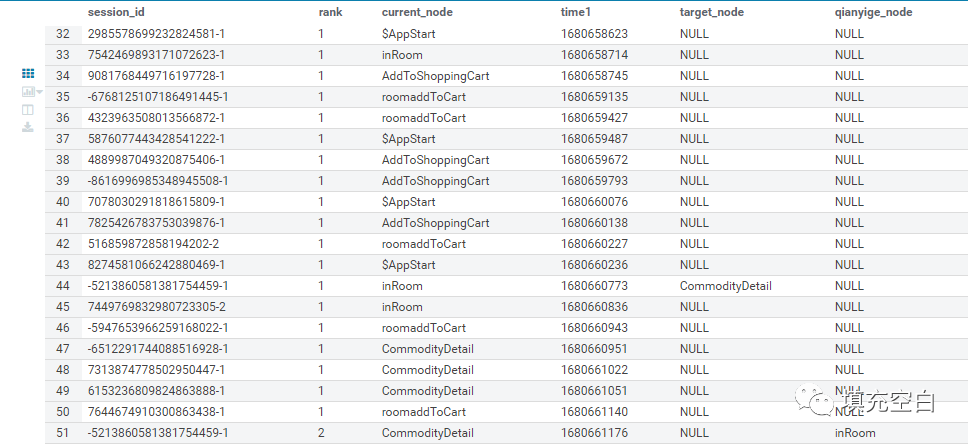

二、根据分析目的进行路径分析
1.不选择明确的开始事件和结束事件,只看不同会话的流转走向。
缺点是可能每个会话的开始行为不一样,可能有些会话中一开始才进入了商详页开始购买路径,有些用户第10步才进入商详页才开始购买路径。整体用户行为路径图较散。意义不大。
此处做简单拆解,思路:
统计一中每种路径的具体“流量”是多少。
有多少是第一步从A到了B节点。
有多少是第一步从B到了C节点。
....
有多少是第2步从B到了C节点。
有多少是第2步从C到了D节点。
具体代码如下:
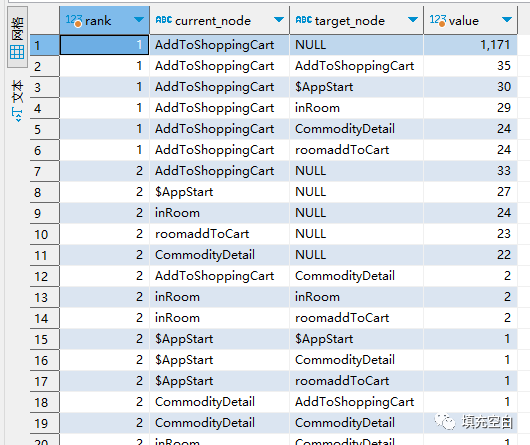
select rank,current_node,target_node,count(distinct session_id) as valuefromsession agroup by 1 ,2,3order by 1 asc ,4 desc
输出结果如下:
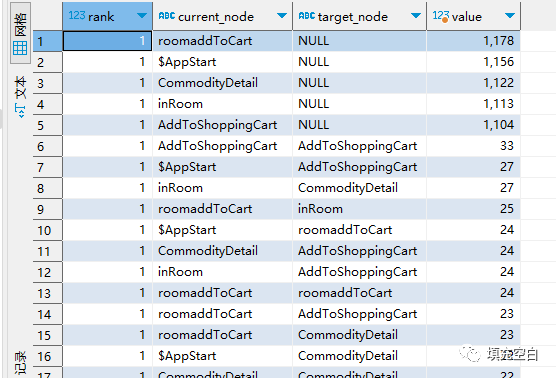

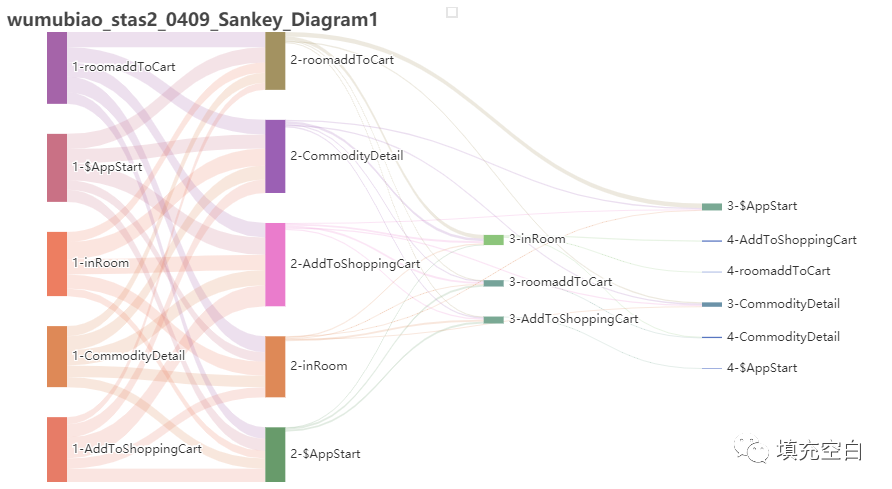
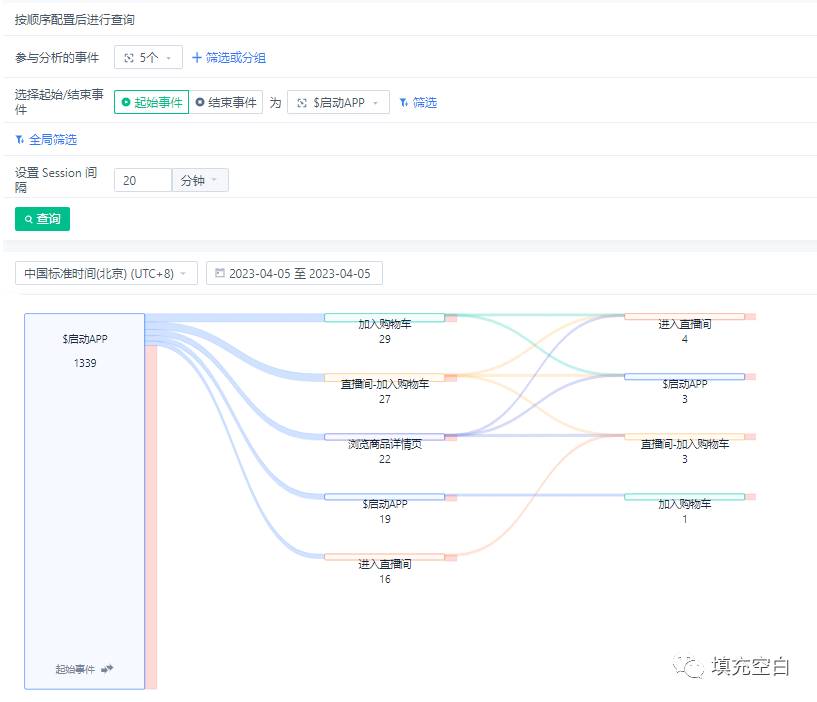
以下wumubiao_stas2_0409_Sankey_Diagram1为去掉target_node=null的桑基图。
select session_id,min(time1) as min_timefrom session awhere current_node='$AppStart'group by session_id
2)排序行为序列。将2.1的1)中找到的session,匹配查找对应的事件,并对session中的事件进行排序。
select a.session_id,row_number() over (partition by b.session_id order by b.time1 asc) as rank,b.current_node,b.target_node,b.timefrom(select session_id,min(time1) as min_timefrom session awhere current_node='$AppStart'group by session_id)aleft join session bon a.session_id=b.session_id and b.time1>=a.min_time
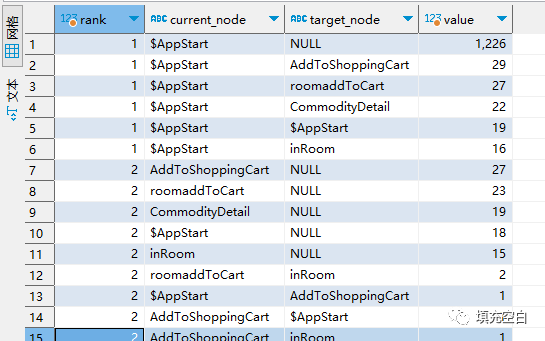
3)计算每种路径流转的具体流量。每层流转时,开始事件,结束事件,及其流量数(会话数)。整体代码如下:
select rank,current_node,target_node,count(distinct session_id) as valuefrom(select a.session_id,row_number() over (partition by b.session_id order by b.time1 asc) as rank,b.current_node,b.target_node,b.timefrom(select session_id,min(time1) as min_timefrom session awhere current_node='$AppStart'group by session_id)aleft join session bon a.session_id=b.session_id and b.time1>=a.min_time)agroup by 1 ,2,3order by 1 asc ,4 desc
输出结果如下示例:
import pandas as pdfrom pyecharts.charts import Sankeyfrom pyecharts import options as optsimport os###先清除下数据def clear():os.system('cls')clear()# 读取CSV文件drawable_df = pd.read_csv('sta_0409.csv')# 低于多少流量的路径不绘制value_threshold = 0# 绘制到路径的第几层node_level = 10# 保存输出的文件名称title = 'sta_0409_Sankey_Diagram1'links = []nodes_set = set()for index, series in drawable_df.iterrows():# 将节点的名称加工成 <rank>-<node_name> 形式source = f'{int(series["rank"])}-{series["current_node"]}'target = f'{int(series["rank"])+1}-{series["target_node"]}'value = series['value']if value < value_threshold:continueelse:# 构造符合pyecharts要求的links数据link = {'source': source,'target': target,'value': value}nodes_set.add(source)nodes_set.add(target)links.append(link)# 构造符合pyecharts要求的nodes数据nodes = [{'name': x} for x in sorted(nodes_set, key=lambda x: int(x.split('-')[0]))]# 使用pyecharts生成桑基图diagram = (Sankey().add('', # 图例名称nodes, # 节点数据links, # 边和流量数据# 设置透明度、弯曲度、颜色linestyle_opt=opts.LineStyleOpts(opacity = 0.2, curve = 0.5, color = "source"),# 标签显示位置label_opts=opts.LabelOpts(position="right"),# 节点之前的距离node_gap = 30,).set_global_opts(title_opts=opts.TitleOpts(title = title)))os.makedirs('export/', exist_ok=True)diagram.render(f'export/{title}.html')
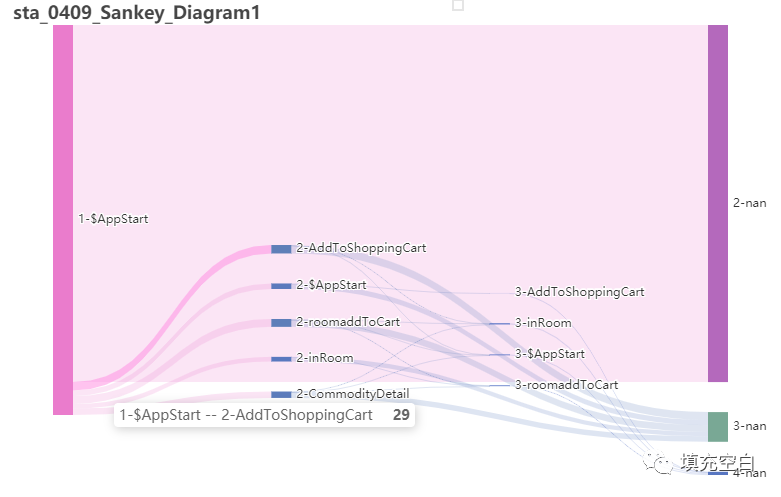
python运行后输出桑基图结果sta_0409_Sankey_Diagram1如下:
 ,
,
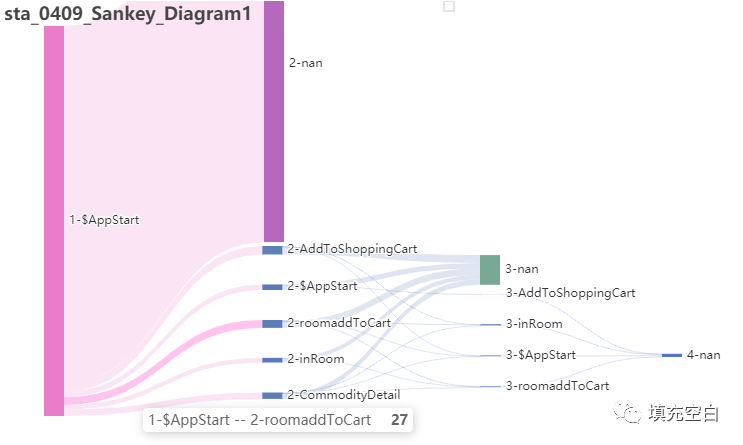
如你所见,因为上述2.2步骤中输出的csv文件中每层有target_node=null,即流失部分(该层路径流转时,结束事件未在所选事件中),都显示在最后了。但似乎这样也是合理的。用户的最后一个行为都是流失,只是有的是第2步,有的是第3步....等。
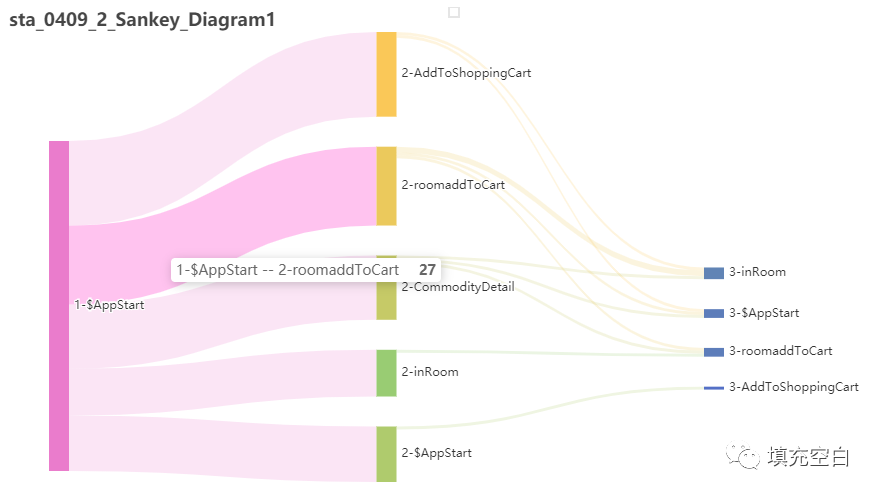
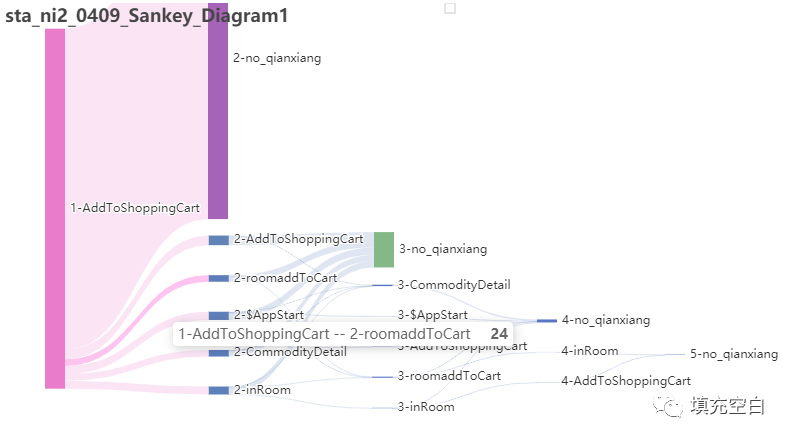
如果只是想看行为流,不显示流失事件时,可将target_node=null的数据2.2查询的结果中直接删除,绘制桑基图如下(sta_0409_2_Sankey_Diagram1):
select rank,current_node,qianyige_node as target_node,count(distinct session_id) as valuefrom(select a.session_id,row_number() over (partition by b.session_id order by b.time1 desc) as rank,b.current_node,b.qianyige_node,b.timefrom(select session_id,max(time1) as max_timefrom session awhere current_node='$AppStart'group by session_id)aleft join session bon a.session_id=b.session_id and b.time1<=a.max_time)agroup by 1,2,3order by 1 asc ,4 desc
结果如下:
# 读取CSV文件drawable_df = pd.read_csv('sta_ni2_0409.csv')# 保存输出的文件名称title = 'sta_ni2_0409_Sankey_Diagram1'
输出桑基图如下:
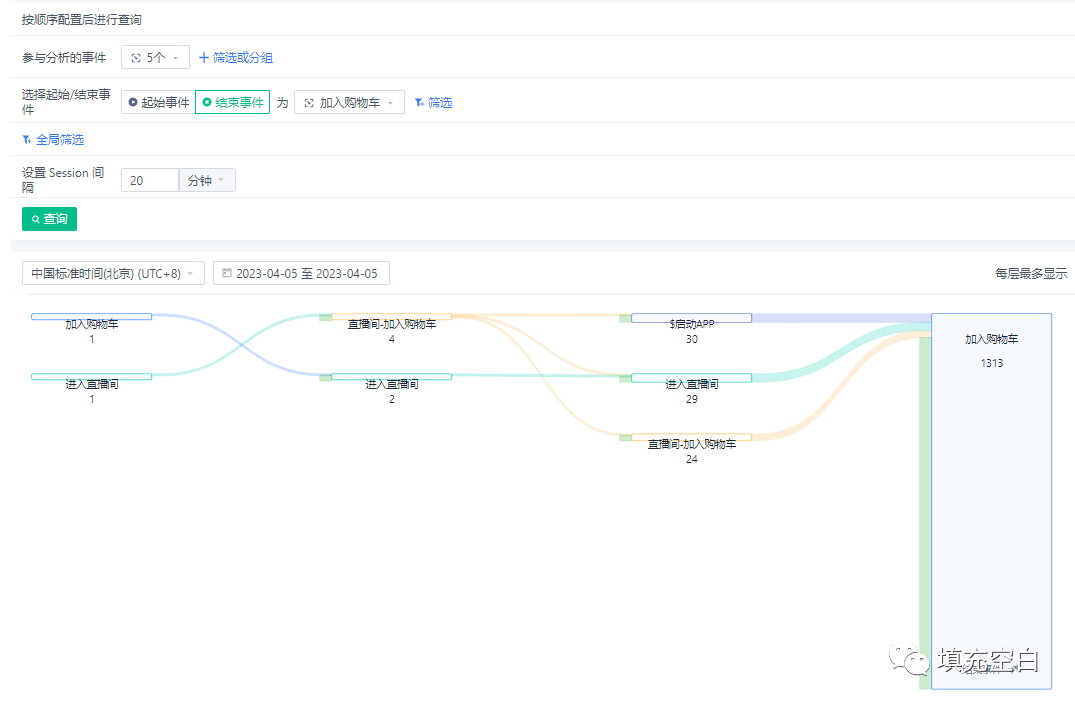

祝大家好运!
