




点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
哈喽大家好,我是六哥~
继上篇咱们讲过Hive高频函数中的
窗口函数、字符处理函数后
有读者留言 能否讲讲其他易错函数
所以针对公众号的『工具&语言』板块
我打算陆续盘一盘日常工作中那些
常用到的、易采坑的、难理解的函数
争取用大白话、有实例的方式唠明白
可以作为日常工作中的备忘知识手册
忘记了来翻一翻,立马唤醒知识点
上俩篇系列分享可戳👇
—— 行列转换函数
日常工作中,这类函数照猫画虎大概都会写
但总觉得用起来有点心虚,挺容易报错
所以我会一一总结下:
常用到的函数有啥?
原理是啥?区别是啥?
还有一些巧用方式的分享
内含 使用注意事项+实例
( 注:含常用场景总结,可收藏慢看)
注:含常用场景总结,可收藏慢看)
------正文手动分割线------
本文结构速览:
一、常用情景总结
二、行转列函数
三、列转行函数
常用场景
实际工作场景中
由于数据库中数据存储格式的不同
需要对一些字段做拆分或者整合处理
或者根据具体需求的分析场景
想对表格数据做一些定制化转换
比如想从多行变一行输出
比如想从一行做多行膨胀
....
上述情况,就会用到行列转换函数
总结下来,根据场景常用的函数有这些:
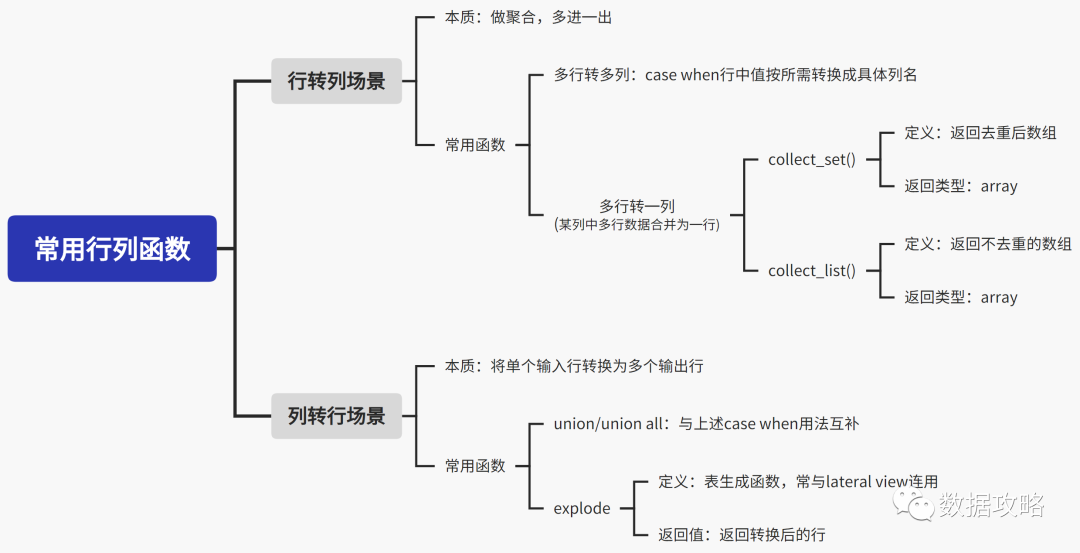

行转列
▌collect_set()&collect_list()
▼ 含义:将某列中的值,按所需从多行折叠在1行
▼ 语法:
collect_set(colname)## 定义:将colname指定的列值聚合为一个无重复元素的数组## 返回类型:去重后的数组arraycollect_list(colname)## 定义:将colname指定的列值聚合为一个数组## 返回类型:数组array
▼ 注意点:
相同点: 二者功能类似,都是聚合函数,可将同组数据聚合成数组在一行中
colname值为NULL时,该行不参与计算
区别点:
collect_set()中,会去除重复元素
collect_list()中,不去除重复元素,与distinct连用可实现collect_set()功能
▼ 常用姿势:
常与contact_ws结合使用,即按照分组,将这列元素以指定分隔符拼接成字符串做输出 有时需要输出的array中的元素保持一定顺序,有2种方法可实现:
方法一:利用distribute和sort by,先在内部排序后,再进行剩余操作,可以实现让collect_set/collect_list有序行转列。
方法二:利用sort_array(),如:
select sort_array(collect_set(colname)) as col
▼ 举例说明:
-----------数据集声明-----------+---------+---------+|usr_id |order_id |+---------+---------+|1001 |123001 ||1001 |124001 ||1001 |123001 ||1002 |133002 ||1002 |134002 |+---------+---------+# collect_set #SELECT usr_id,collect_set(order_id) AS order_idFROM order_detailGROUP BY usr_id#返回结果:集合的内容去重usr_id order_id1001 | [123001,124001]1002 | [133002,134002]# collect_list #SELECT usr_id,collect_list(order_id) AS order_idFROM order_detailGROUP BY usr_id#返回结果:集合的内容去重usr_id order_id1001 | [123001,124001,123001]1002 | [133002,134002]
▌case when
▼ 用法:在此场景中可将某列中的值转化为列名,即宽表形式输出
▼ 语法:
SELECT 分组字段m,MAX(case when xx='a' then result else null end) as cola_result,MAX(case when xx='b' then result else null end) as colb_result,MAX(case when xx='c' then result else null end) as colc_resultFROM tableGROUP BY 分组字段m;
列转行
▌explode:
▼ 含义:将hive一行数据转为多行的UDTF
▼ 语法:
explode(<var>)## 参数值: var为array或者map类型## 返回值:返回转换后的行- 如果参数是array,则将array转为多行- 如果是map类型,转换为包含key、value两列的行
▼ 举例说明:
-----------数据集声明-----------+---------+---------+|col1 |col_map |+---------+---------+|1001 |{c1::123001,c2:124001} ||1002 |{c2::133002,c3:134002} |+---------+---------+SELECT EXPLODE(col_map) as (key,value) FROM table#返回结果:key valuec1 123001c2 124001c2 133002c3 134002
▼ 注意点:
在select中只可出现一个explode函数,不可以出现表的其他列
不能与group by、cluster by、distribute by、sort by联用
不能嵌套使用
针对上述情况,如何办?
▌lateral view:
▼ 作用:lateral view是Hive中提供给UDTF的结合,它可以解决UDTF不能添加额外的select列的问题。
▼ 语法:
lateral view udtf(expression) tableAlias as columnAlias (,columnAlias)*##参数说明:- udtf(expression):使用的UDTF函数,例如explode();- tableAlias:表示UDTF函数转换的虚拟表的名称;- columnAlias:表示虚拟表的虚拟字段名称,如果分裂之后有一个列,则写一个即可;如果分裂之后有多个列,按照列的顺序在括号中声明所有虚拟列名,以逗号隔开。
▼ 举例说明:
-----------数据集声明-----------+---------+---------+|pageid |col_list |+---------+---------+|page1 |[1,2,3] ||page2 |[4,5,6] |+---------+---------+SELECT pageid, new_colFROM table LATERAL VIEW explode(col_list) tmptable AS new_col;#返回结果:pageid new_colpage1 1page1 2page1 3page2 4page2 5page2 6
▌union/union all:
▼ 用法:在此场景中即根据所需做行的拼接
▼ 语法:与前面case when用法互补,即
SELECT 分组字段m,'a' as xx,cola_result as resultFROM tableunion allSELECT 分组字段m,'b' as xx,colb_result as resultFROM tableunion allSELECT 分组字段m,'c' as xx,colc_result as resultFROM table
▼ 注意点:
相同点:union和union all功能实现类似,且都需要前后连接的sql语句中字段个数和类型均要一致。
区别点:
union会去除重复内容
union all会如实保留
如若盼 追更 【日常学习】干货系列 

 往期好文推荐
往期好文推荐 更多 『求职干货』 & 『日常学习』 系列好文,等你发现~

Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的
点个在看,肝『干货』更有动力
