




异常轨迹检测旨在提取道路上车辆的异常运动。由于不同时间和地点的交通状况不同,使得异常轨迹检测具有挑战性。其次,基于距离度量计算正常路线并识别异常值的解决方案具有很高的时间复杂度,这阻碍了它们在线异常值检测中的使用。本次为大家带来国际数据库领域的顶级会议VLDB的论文:《DeepTEA: Effective and Efficient Online Time-dependent Trajectory Outlier Detection》

一.背景
随着移动电话和车辆中位置感测设备(如GPS)广泛应用,我们目前已能够收集大量车辆在行驶过程中产生的轨迹数据。在城市计算领域,从这些轨迹数据中提取异常值是一个备受关注的研究问题。该问题通常用于检测异常驾驶行为,例如出租车和拼车公司可能寻找在载客时走异常路线的司机,并进一步检查是否存在欺诈行为。尽管多数轨迹异常值解决方案基于形状,但这种方法无法考虑到异常值会随时间变化的事实。相比之下,近年来研究者们开始探索寻找时间相关轨迹的问题,这些解决方案考虑了影响依赖于时间的正常路线的不同因素,例如事故、路障和高峰时间等。接下来,采用基于距离的措施来区分异常轨迹和正常路线,然而该方法存在两个主要缺点。首先,寻找合适的阈值可能极具挑战性。其次,这些基于距离度量计算正常路线并识别异常值的解决方案具有极高的时间复杂度,这限制了它们在线异常值检测中的应用。
论文提出了一种名为DeepTEA的有效时间相关异常值检测框架。该框架可以从行驶期间的实时交通状况中推导出潜在交通模式,以捕捉动态交通状况,例如{平滑→拥挤},并通过优化证据下限 (ELBO) 来最大化在动态交通条件下观察轨迹的可能性,导出潜在交通模式以捕获动态交通状况。接着,基于这些潜在交通模式,获得了时间相关的正常轨迹。本文还利用基于学习到的潜在交通模式的生成网络,在潜在交通模式下最大化观察到的轨迹的生成。在潜在交通模式下无法生成的轨迹则被标记为时间相关的异常值。此外,作者对该框架进一步提出了一种近似在线检测算法(DeepTEA-A)。其中,时间相关路线的潜在表示由协同训练神经网络在给定起点、目的地位置和出发时间的交通状况下进行近似。
二.DeepTEA模型
2.1 总体框架
图 1显示了 DeepTEA 的框架。它包含一个推理网络和一个生成网络。给定轨迹 T,论文推断出旅行期间的潜在交通模式q(z|T)。轨迹观察 τ 反映了时间相关的轨迹转换,用于对推理网络中的潜在时间相关路径r建模。之后,时间相关路线r用于生成轨迹观测值 τ。
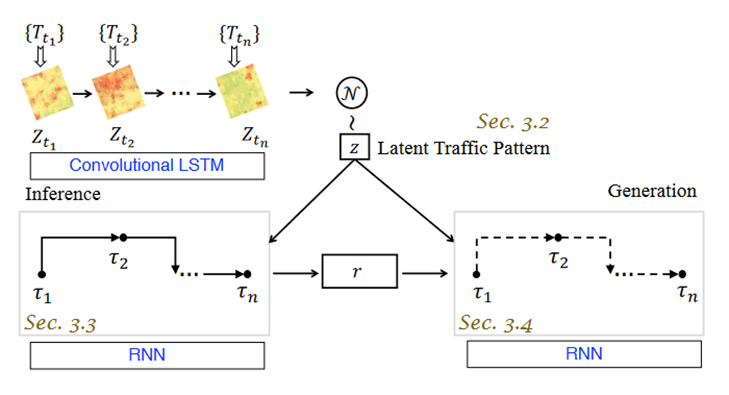
图1 总体框架图
2.2 潜在交通模式推断
论文从时间ti的轨迹集{Tti}中学习潜在交通模式,这里作者使用时间点序列来表示旅行时间,为了更好地组织来自{Tti}的交通信息,作者使用具有每个网格单元中平均速度的地图网格矩阵Zti来模拟ti处的交通状况。从图1可以看出,网格矩阵中的红色表示平均速度较低,这些位置的交通拥堵。绿色表示平均速度高,交通顺畅。而黄色表示交通状况即将拥堵,平均速度低于绿色单元格但仍高于红色单元格。为了解决特定时间跨度不同位置的流量多样性问题,作者通过 CNN 模型来捕获它。对于没有车辆的位置,CNN 模型可以从有车辆的单元格中学习缺失值,而不是将它们表示为缺失单元格。由于交通状况实时频繁变化,作者使用 RNN 模型来捕捉不断变化的交通动态。这样,RNN 模型就可以很好地捕获交通状况背后的转变。然后作者使用 RNN 模型的隐藏状态来推断具有高斯分布的潜在流量模式 z。
2.3 潜在的时间相关路线推断
轨迹T不仅能够反映其位置pti,还可以通过两个连续的轨迹点pti-1和pti之间的转换传递潜在的交通模式z。作者使用o(pti, z)来表示轨迹T所背后的观测τi。由于对来自轨迹T的观测pti和z的组合进行建模具有一定挑战性,作者采用神经网络来处理这些观察结果的组合。接着,作者研究了轨迹T可能穿过的潜在时间相关路线r。例如在城市道路交通拥堵时,司机通常会选择高峰时段畅通无阻的高速公路。为了区分潜在交通模式下轨迹的正常过渡与异常情况,作者设计了一个组件,从轨迹中模拟潜在时间相关的正常路线,其中潜在交通模式z提供时间相关的交通信息。然后,推理网络可以从轨迹T中推断出潜在的随时间变化的路线r、潜在的随时间变化的路线类型k以及潜在的交通模式z。
2.4 轨迹观察生成
轨迹观测生成的目标是根据其推断出的潜在时间依赖路线r、时间依赖路线类型k和潜在交通模式z,最大化生成轨迹观测τi的概率,即o(pti, z)。作者设计一个RNN神经网络来生成T的轨迹观测τi
2.5 最优化
论文的目标是最大化观察轨迹的边际对数似然:
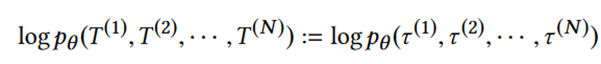
论文通过最大化边际对数似然的证据下限 (ELBO) [1]来优化边际对数似然。
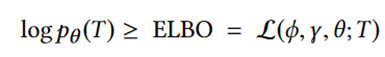
2.6 模型训练时间复杂度
训练DeepTEA的总体复杂度为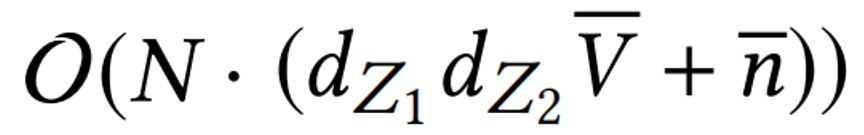 ,其中N是轨迹的数量,
,其中N是轨迹的数量,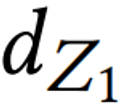 和
和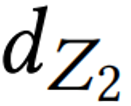 是Z的大小,
是Z的大小, 是时间间隔的平均数,
是时间间隔的平均数, 是轨迹的平均长度。
是轨迹的平均长度。
三.基于DeepTEA 在线轨迹异常值检测
3.1 在线检测
图2显示了在线异常轨迹检测的过程。算法通过基于第二节DeepTEA模型学习得到的参数 φ、γ、θ 生成观察到的轨迹来检测异常值。具体来说,可以根据 γ 中的参数计算潜在时间相关路径的分布qγ (r|T)。潜在交通模式 z 可以基于 φ 和 Z 中的参数获得,Z 是从轨迹集 {T} 聚合而来的。给定qγ (r|T)中分量的第 k 个均值 uk,作者应用 RNN 神经网络生成轨迹观测值。
给定学习到的qγ (r|T)和潜在交通模式 z,实时给出的轨迹 T 的异常分数sa (τ1:i):
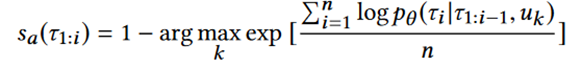
在在线设置中,给定先前的轨迹观测值 τ1:i ,下一个进入的轨迹观测值 sa (τ1:i+1) 的异常分数可以基于先前的轨迹 τ1:i 更新为:
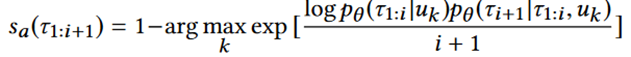
在线检测的整体过程如下:算法输入是轨迹T,以及从DeepTEA模型训练中学到的模型参数φ、γ和θ。对于新来的轨迹观测τ1:i,如果它发生了变化,就更新潜在的交通模式z。然后,作者根据τ1:i计算观察到轨迹观测τ1:i+1的似然。最后,返回异常得分。
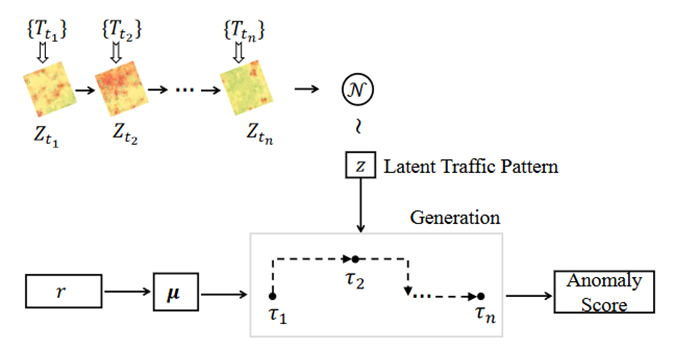
图2 DeepTEA在线检测
3.2 在线检测时间复杂度
检测的总体复杂度为 O(dZ1dZ2),其中 dZ1 和 dZ2是 Z 的大小。
四.DeepTEA-A 模型:近似在线检测
4.1 近似算法
基于τ1+i的τ1+i的异常得分的在线更新依赖于t1+i时间的交通状况矩阵Z的卷积计算,这对于大型道路网络来说可能很费时,它可能使在线检测过程变得缓慢。因此论文进一步提出一种近似算法,以加快在线异常轨迹检测的速度。论文提出了一种近似算法来加速在线异常轨迹检测,其利用时间间隔为τ1的交通状况矩阵 Z 作为旅行期间交通状况的近似值。这样,交通状况矩阵Z的卷积只需要对第一个轨迹观测值τ1计算一次。对于τ1+1异常分数的在线更新,不再需要卷积计算。给定源起点ST和目的地DT,从q(k|ST, DT,ZST)中得出最佳潜在路径类型 k 来近似最佳潜在路径模式 uk,它需要从qγ (r|T) 的 k 均值中找到T ),其中ZST是行程开始时的交通状况。这样,在行程开始时给定 ST、DT和ZST就可以获得最佳潜在路径类型 k。从第二次轨迹观察开始,不再需要重新计算最佳潜在路线模式来更新异常分数。
4.2 近似算法时间复杂度
新轨迹观测到来时近似在线检测的总体复杂度为 O(dht(dht+dτ1))。由于 dht 和 dτ1 是常数,近似的时间复杂度为 O(1)。
五.实验
5.1 数据集
论文在两个真实数据集上评估论文的方法。第一个数据集(XN)是一个开放的GPS数据集,包含2016年10月1日至10月7日中国西安二环周边地区的GPS数据。第二个数据集(CD)是一个开放的GPS数据集,包含2016年10月1日至10月7日中国成都二环路周边地区的GPS数据。
5.2 效益评估
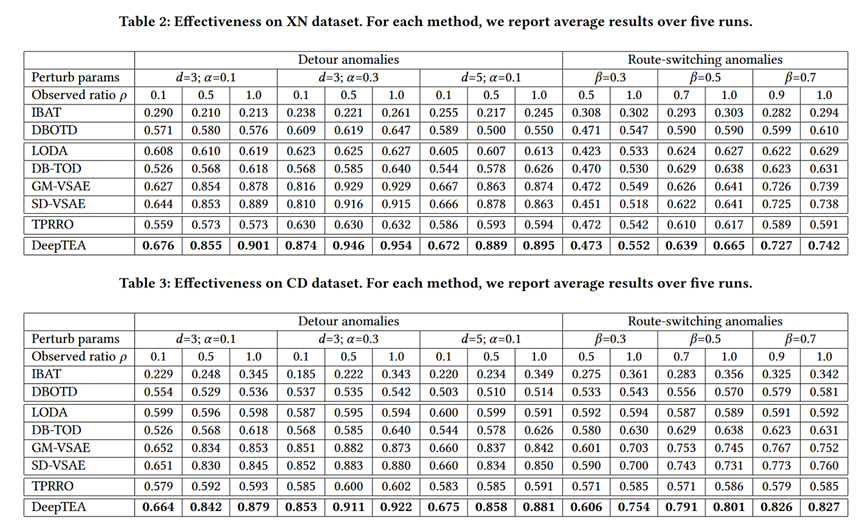
论文在变化观测比率(ρ),检测绕行异常,路线切换异常三个方面开展实验,实验结果表明论文提出得基于DeepTEA模型在三个方面得异常检测效果均优于其他方法。
5.3 在线近似检测效益
论文评估了 DeepTEA-A 在两种异常类型上的有效性,即图 3中的绕行 (D) 和线路切换 (RS) 异常。与 DeepTEA 相比,DeepTEA-A 在 XN 和 CD 数据集上的 PR-AUC 值略有下降,即平均下降 1.16%。这意味着,对于仅以起点、目的地位置和出发时间的交通状况为条件的潜在时间相关路线,在两种异常类型 D 和 RS 中,时间相关异常值检测的性能略有下降。
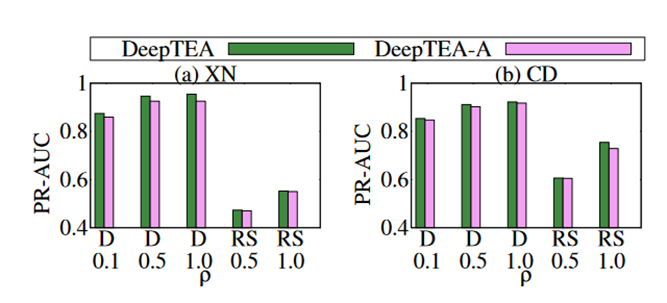
图3 DeepTEA-A检测效果
5.4 效率评估
论文评估了图 4 (d) 中所有数据集上所有方法的完整观察的一条轨迹的平均检测时间从图 4 (d) 中,可以看出:(1) DB-TOD 在 XN 和 CD 数据集上以最快的速度检测异常值。原因是 DB-TOD 通过在训练阶段最大化似然来学习具有线性函数的参数。并且学习到的参数在在线检测阶段只需要一个快速的线性运算,这只依赖于他们模型中的少量参数。 (2) 方法 LODA、SD-VSAE 和本文的近似版本 DeepTEA-A 比其他方法执行得更快,只有 DB-TOD 除外。原因是 LODA 集成了一些弱分类器,它们是快速线性函数。作为 DB-TOD,线性函数对于在线检测非常有效。而且线性函数的数量并不多。对于 SD-VSAE,它通过将 k 次最可能的潜在路径计算替换为仅按起点和目标位置计算一次来降低计算成本。 SD-VSAE 在线检测的计算成本为 O(1)。尽管本文的近似方法考虑了旅行期间交通状况的更多信息,但本文通过基于出发时间的交通状况来近似潜在交通模式来减少其时间成本。论文的近似方法在线检测的时间成本也是 O(1)。 (3) 大多数基于度量的方法在线检测的速度较慢,例如 DBOTD、IBAT 和 TPRRO。他们通常需要根据密度或距离度量从数据集中为给定的起点、目的地位置和旅行时间找到正常的时间相关的正常路线。然而,这些步骤对于在线检测来说通常很耗时。他们需要首先提取时间相关的正常路线,然后通过预定义的阈值将测试轨迹与时间相关的正常路线进行比较。 (4) 近似方法DeepTEA-A 的检测时间比DeepTEA 快。原因是论文通过在训练阶段使用协同训练网络仅根据出发时间的交通状况来学习潜在交通模式的参数,从而减少了标准方法的时间成本。学习到的参数可以直接用于在线检测异常值,而无需在轨迹动态移动时更新潜在交通模式。
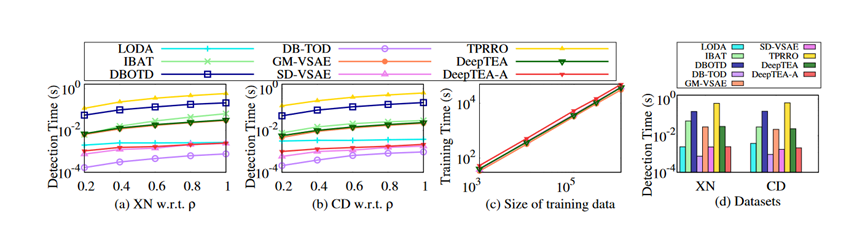
图4 检测效率
六.总结
论文研究了在线时间相关的异常轨迹检测问题。作者在旅行时间内从轨迹中学习潜在模式,并使用学习到的潜在模式来检测轨迹中的异常。对于在线检测,DeepTEA支持在新的轨迹点到来时更新异常分数,此时行程还没有结束。此外,作者提出了一种近似在线检测算法 DeepTEA-A,以通过协同训练网络减少时间成本。实验结果表明,论文的模型在检测异常值时更有效。此外,DeepTEA-A 可以更有效地检测在线时间相关的异常轨迹。
参考文献
|

