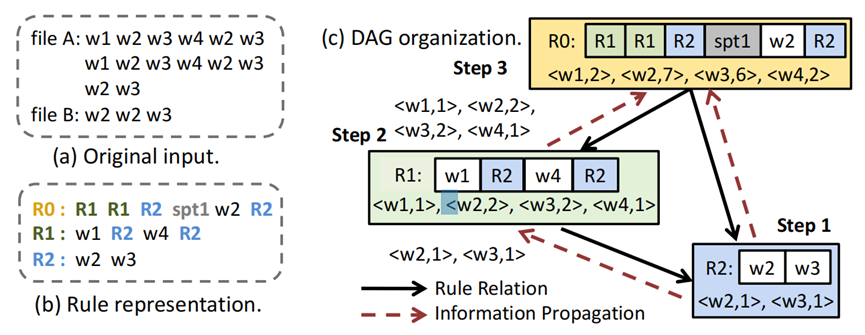
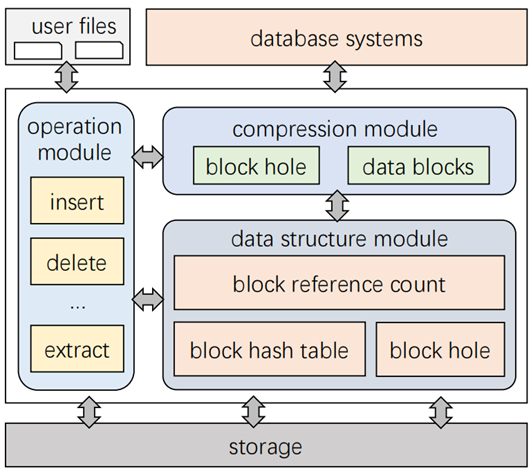
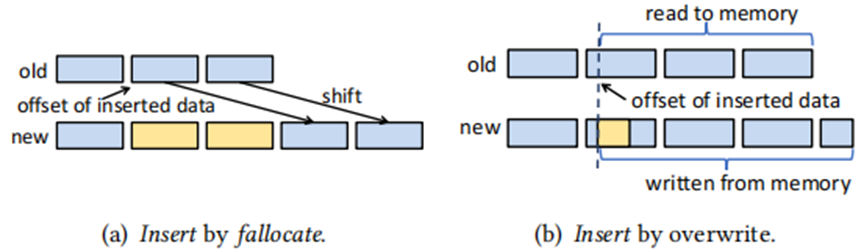
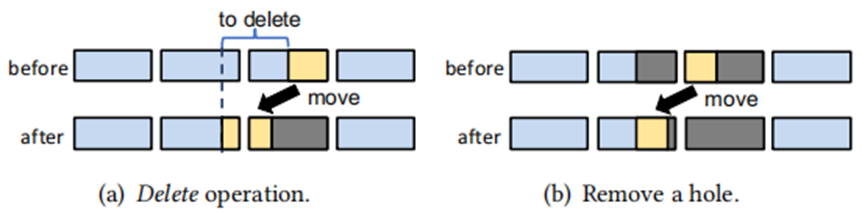
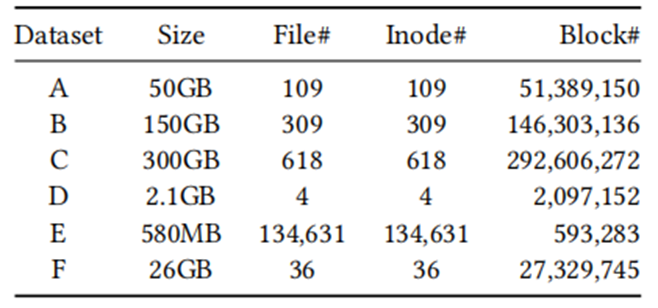
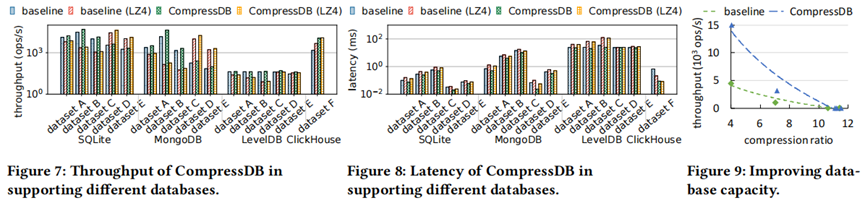
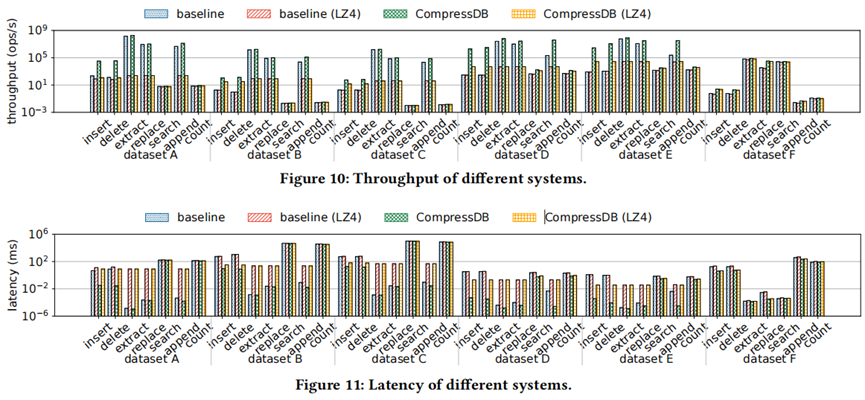
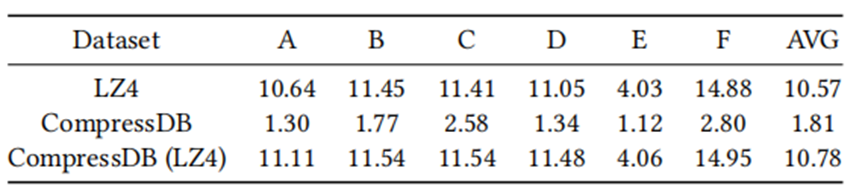
面对指数级数据量的增长,现在大数据系统使用数据压缩来减少存储空间,但是频繁的压缩和解压操作会花费很大的开销,因此产生了对于压缩数据直接执行数据操作的想法。本文带来的是张峰老师团队发表于数据库领域国际顶级会议SIGMOD 2022上的论文《CompressDB:
Enabling Efficient Compressed Data Direct Processing for Various Databases》。本文努力通过开发一种高效的技术来支持压缩数据的更新、插入和删除操作,从而实现一个支持数据查询和操作的、空间高效的大数据系统。现代大数据系统正面临着指数级增长的数据量,并使用数据压缩来减少存储空间。为了避免持续的压缩和解压缩操作的开销,现有的研究系统探索了对压缩数据直接执行数据操作的想法。目前的解决方案基本上只能在查询处理上面有着不错的效果,但是一个完整的数据库系统需要支持数据查询以及一些数据操作,特别是数据记录的更新、插入、删除操作。以往的数据库对于这些操作都需要对较多的数据进行解压后重新压缩。导致比较大的开销。本文开发了一个新的存储引擎,称为CompressDB,它可以支持直接对压缩数据的数据查询和数据操作,并可以支持各种数据库系统。文章发现,当基于规则的数据库的规则DAG深度较浅的时候,基于规则的压缩方法就适用于数据库的操作(DAG表示的基于rule的组织形式,是一个有向无环图)。因此较之前研究的TADOC[]进行了一些新的设计。为了使CompressDB能够无缝支持各种数据库,所以文章在文件系统中开发CompressDB,可以在文件系统层处理读写操作。由于有些文件系统不支持CompressDB开发了通用的操作,例如插入和删除,并且提供了api。TADOC[1]是一种基于规则的直接在压缩数据上操作的解决方案,它可以从三个层次来解释:Element元素、Rule规则和DAG。Element:最小的不可分割的最小处理单元。元素可以是规则,也可以是数据单元,例如来自原始文件中的单词。Rule:元素的字符串。TADOC使用一个规则来表示重复的内容,并且一个规则由子模块和数据单元组成。DAG:按规则压缩的表示法。不同规则之间的关系可以被组织成一个有向无环图(DAG)。图1展示了三层的关系,采用规则来减少数据的冗余。这种方式可以直接在压缩数据上进行数据分析。TADOC将数据分析转化为基于规则的DAG遍历。Element level:TADOC中最小的处理单元是一个word,粒度太小,对于大数据系统而言通常以1KB或4KB大小的块粒度处理数据。Rule level:TADOC中的规则较为复杂,对应的DAG深度也很深,所以导致TADOC无法进行删除操作。DAG level:TADOC需要将处理压缩数据的完整的DAG加载到内存中,这对于大数据的处理是十分低效的。CompressDB注重解决这些限制。通过从三个层次重新设计系统来实现有效的随机更新。Element level design:允许规则中保留数据洞(data holes),利用数据洞去进行数据块的对齐操作,应对数据更新后有可能出现不对齐的情况。Rule level design:有效的定位和合并规则,除了叶子节点,其余节点被组成一个树状结构,只有叶子节点包含数据块。这样可以简化拆分和合并的操作;而且可以采用哈希表来定位叶子节点中的数据;数据洞也只存在叶子节点中,更方便数据操作。DAG level design:限制有效的随机更新规则的深度。虽然较深的规则DAG可以帮助减少冗余,但是如果更新数据会引起灾难性的性能下降。因此限制了DAG的深度。CompressDB与字符串压缩有着一定的区别:CompressDB将数据划分为不同的数据块,不区分数据类型,字符串压缩通常只用来处理文本数据;CompressDB一个支持各大数据库系统的存储引擎而不是一般的算法;CompressDB提供了一系列的操作,而且可以和用户交互。而字符串压缩算法侧重压缩特定的任务。CompressDB在存储层工作,因此构建在CompressDB上的数据库系统可以自动利用其直接处理压缩数据的能力。CompressDB总体框架如图2所示。主要包括数据结构模块,压缩模块和操作模块。三个模块相互协作来解决随机更新的各种复杂问题。这个模块为压缩模块和操作模块提供了必要的数据结构。此处介绍三种数据结构。blockHashTable. 这个数据结构提供了从块的哈希值到块号的映射。可以快速定位压缩过程中下层的块的位置,对于相同的哈希值的块需要进一步比较内容是否一致,对哈希冲突具有一定的弹性。blockRefCount.记录了在文件系统中引用一个块的次数,例如一个块被引用了两次,就意味着一个文件中出现了两次或者两个文件中各出现了一次。这个数据结构可以进行判断是否可以在删除时直接释放块或者能否在插入或者替换时直接修改块。BlockHole. 记录了由插入和删除操作引起的hole的结构。在随机更改时,有可能导致数据块不对齐的情况出现,为了不破坏压缩情况所以添加hole数据结构。当数据第一次输入到CompressDB时,使用基于规则的方法将文件压缩到系统中。将每一个块视为一个节点,中间节点为规则,叶子节点为数据。原始文件被组织成一个树状结构。系统采用块的hash表来识别相同的块然后进行合并,并且他们的上层指针指向同一块。然后更新blockRefCount,这样就实现了较浅DAG,压缩过程也变得简单。如图3(a)到图3(b)。为了适应文件系统,本文选择了块级压缩方案,在每次修改之后都对相关的数据块进行检查,这样不需要对所有修改过的块进行追踪。相较于文件级压缩方案(在所有文件修改后再检查所有的文件数据块)而言更加合适。压缩的步骤中只在更新操作时需要O(n)的时间,其他步骤只涉及有限的操作例如哈希、删除哈希、释放块这些简单的操作。故整体压缩的复杂度为O(n).操作模块中包括提取(extract)、替换(replace)、插入(insert)、删除(delete)、搜索(search)和计数(count)。图3中给出了相应操作的示例。插入。如图4所示,有两种已有的插入方法供选择,一种是图4(a)所示的fallocate方式进行插入,但是需要插入的数据是块大小的整数倍。系统选择了图4(b)的读写系统调用的方式,读取插入位置后的所有内容然后进行写入,这种方法对于较大的插入成本极大,而且会导致压缩效果降低,例如图5所示原AB文件相同可以进行压缩而插入后二者压缩效果大大降低。因此本文取二者的精华,一方面为了确保高性能,本文通过将数据块直接插入到块序列中来执行插入。另一方面为了支持不同大小的插入情况,采用BlockHole数据结构进行数据块的补齐,这样可以确保插入后数据块的对齐。对于其他操作来说,可以将有BlockHole的块视为常规块一起处理。删除。本文采用带有BlockHole数据结构的删除操作,如图6(a)所示,数据删除后可以保留BlockHole。由于删除操作会留下大量的BlockHole,所以需要一个BlockHole合并的操作,详细的说就是删除的时候涉及到多个BlockHole时,可以重新排列所涉及的数据块中的剩余数据。如果有BlockHole的大小大于数据块的大小,就可以将冗余块去除,如图6(b)中完全为黑色的数据块。提取。为了执行提取操作,本文采用的是在inode遍历数据块获得偏移量,然后在数据块中进行根据偏移量来找到具体数据。替换。CompressDB的替换不采取“删除后插入“的操作而是直接对元数据进行覆盖。如果要修改的数据块被多个指针引用的话,不能直接进行覆盖,所以分配了另一个块来进行修改。如果仅仅被一个块引用,则直接进行修改。此处还应该利用哈希表来确定新的块是否为重复块。搜索。返回用户查询内容的位置。主要分为三个步骤,第一步进行块内的搜索,如果当查询的内容全部落在一个块内,就直接获得块内的偏移量。第二步进行块间的搜索,检查连续数据块内的内容获得每个数据块内的情况。第三步进行结果的合并,获得最终的结果。添加。将新来的数据添加到文件的末尾。为了更好地提高性能,会先检查是否有必要分配新的数据块,如果有重复数据块,只需要添加一个指针,不需要分配额外的数据块。计数。返回用户查询内容出现的频率。类似于搜索操作,可以先获得块内数据出现的频率,然后再根据哈希表来获得数据块出现的频率。“Baseline”表示采用对文件进行线性扫描的方法,“Baseline(LZ4)”表示使用LZ4压缩的方法;“CompressDB”表示基于现有系统的CompressDB,包括单节点上的FUSE和分布式的MooseFS。“CompressDB(LZ4)”表示在CompressDB上进行正常的压缩。在实验中选择了四个数据库,SQLite, LevelDB, MongoDB 和Click House。实验选用了6个数据集,如表1所示。这些数据集的大小结构内容均为真实文档构成。实验设备:对于ABC三个大型数据集而言部署了五个节点的集群,每个节点包括Intel Xeon Platinum 8369HB CPU at 3.30GH,16GB内存,操作系统为Ubuntu 18.04.5,硬盘为400GB ESSD。对于DEF三个数据集使用了一台Intel i9-9900K CPU,内存为64 GB,操作系统为Ubuntu 18.04.5,硬盘为6TB WD BLUE 3.5。吞吐量。图7所示为CompressDB对于不同数据库的吞吐量。CompressDB比Baseline提高了40%吞吐量,对于大数据集CompressDB有着最好的吞吐量,对于小数据集也有着出色的吞吐量。延迟。如图8所示,CompressDB有着一定的延迟优势。CompressDB减少了从磁盘读取的数据量,此外在分布式环境中存在传输的开销,表现出更高的延迟。改善了数据库的压缩能力。如图9所示CompressDB与Baseline在相同的压缩率的情况下可以有着更加优秀的性能。对于不同的操作,如图10,图11所示CompressDB对于各种操作的吞吐量和延迟都有着极大的提升。其中extract的效率最高,主要是因为其没有写操作。此外文章还做了关于总体分析的实验以及内存消耗的实验,更多细节可查看原文。本文开发了一种新的存储引擎,CompressDB,可以直接对压缩后的数据直接更新。具体来说,文章将CompressDB集成到文件系统中,这些文件系统可以支持各种数据库系统。此外,CompressDB还可以将操作下推到存储层。文章详细讨论了如何实现对压缩数据的随机更新的想法,并准备了一个全面的实验分析来显示CompressDB的优点。实验表明,CompressDB显著提高了其他数据库系统的性能,同时节省了空间。[1] Feng Zhang, Jidong Zhai, Xipeng Shen, Dalin
Wang, Zheng Chen, Onur Mutlu, Wenguang Chen, and Xiaoyong Du. 2021. TADOC: Text
analytics directly on compression. The VLDB Journal 30, 2 (2021), 163–188.
| 重庆大学计算机科学与技术专业硕士一年级在读学生,重庆大学START团队成员。 | 
|
时空艺术团队(START,Spatio-Temporal Art)来自重庆大学时空实验室,旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!