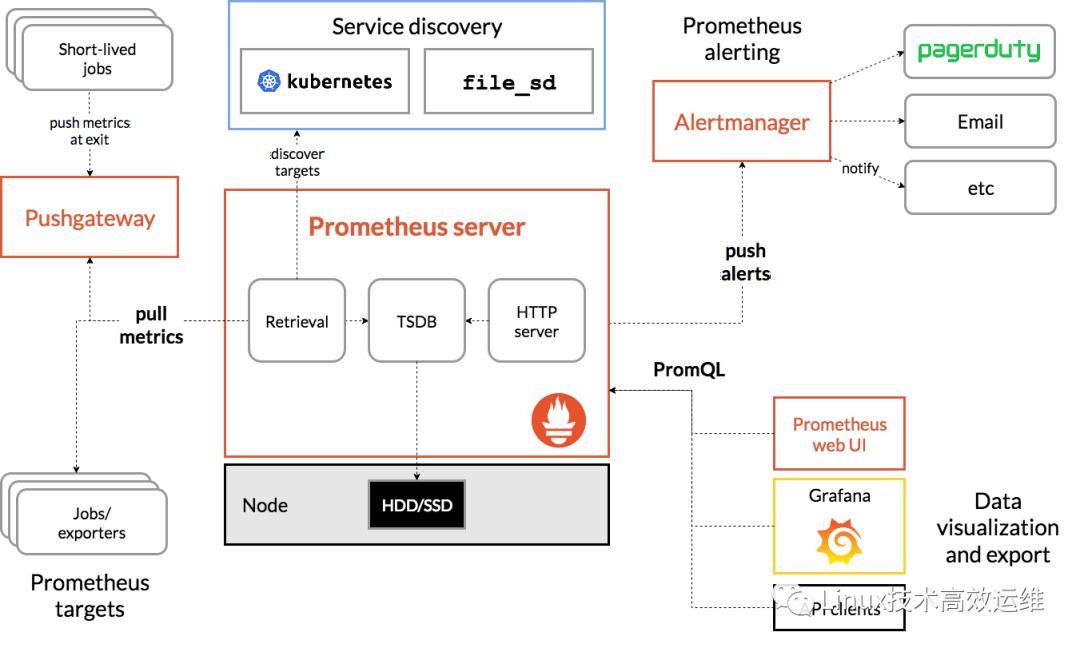
报警名称 | 表达式 | 采集数据时间(分钟) | 报警触发条件 | 是否已存在 |
KubeStateMetricsListErrors | (sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m])) sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m]))) > 0.01 | 15 | Metric List出错。 | 否 |
KubeStateMetricsWatchErrors | (sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m])) sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m]))) > 0.01 | 15 | Metric Watch出错。 | 否 |
NodeFilesystemAlmostOutOfSpace | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 5 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) | 60 | Node文件系统即将无空间。 |
|
NodeFilesystemSpaceFillingUp | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 40 and predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) | 60 | Node文件系统空间即将占满。 |
|
NodeFilesystemFilesFillingUp | ( node_filesystem_files_free{job="node-exporter",fstype!=""} node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 40 and predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) | 60 | Node文件系统文件即将占满。 |
|
NodeFilesystemAlmostOutOfFiles | ( node_filesystem_files_free{job="node-exporter",fstype!=""} node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 3 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) | 60 | Node文件系统几乎无文件。 |
|
NodeNetworkReceiveErrs | increase(node_network_receive_errs_total[2m]) > 10 | 60 | Node网络接收错误。 |
|
NodeNetworkTransmitErrs | increase(node_network_transmit_errs_total[2m]) > 10 | 60 | Node网络传输错误。 |
|
NodeHighNumberConntrackEntriesUsed | (node_nf_conntrack_entries node_nf_conntrack_entries_limit) > 0.75 | 无 | 使用大量Conntrack条目。 |
|
NodeClockSkewDetected | ( node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0 ) or ( node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0 ) | 10 | 出现时间偏差。 |
|
NodeClockNotSynchronising | min_over_time(node_timex_sync_status[5m]) == 0 | 10 | 出现时间不同步。 |
|
KubePodCrashLooping | rate(kube_pod_container_status_restarts_total{job="kube-state-metrics"}[15m]) * 60 * 5 > 0 | 15 | 出现循环崩溃。 |
|
KubePodNotReady | sum by (namespace, pod) (max by(namespace, pod) (kube_pod_status_phase{job="kube-state-metrics", phase=~"Pending|Unknown"}) * on(namespace, pod) group_left(owner_kind) max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"})) > 0 | 15 | Pod未准备好。 |
|
KubeDeploymentGenerationMismatch | kube_deployment_status_observed_generation{job="kube-state-metrics"} != kube_deployment_metadata_generation{job="kube-state-metrics"} | 15 | 出现部署版本不匹配。 |
|
KubeDeploymentReplicasMismatch | ( kube_deployment_spec_replicas{job="kube-state-metrics"} != kube_deployment_status_replicas_available{job="kube-state-metrics"} ) and ( changes(kube_deployment_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) | 15 | 出现部署副本不匹配。 |
|
KubeStatefulSetReplicasMismatch | ( kube_statefulset_status_replicas_ready{job="kube-state-metrics"} != kube_statefulset_status_replicas{job="kube-state-metrics"} ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) | 15 | 状态集副本不匹配。 |
|
KubeStatefulSetGenerationMismatch | kube_statefulset_status_observed_generation{job="kube-state-metrics"} != kube_statefulset_metadata_generation{job="kube-state-metrics"} | 15 | 状态集版本不匹配。 |
|
KubeStatefulSetUpdateNotRolledOut | max without (revision) ( kube_statefulset_status_current_revision{job="kube-state-metrics"} unless kube_statefulset_status_update_revision{job="kube-state-metrics"} ) * ( kube_statefulset_replicas{job="kube-state-metrics"} != kube_statefulset_status_replicas_updated{job="kube-state-metrics"} ) | 15 | 状态集更新未退出。 |
|
KubeDaemonSetRolloutStuck | kube_daemonset_status_number_ready{job="kube-state-metrics"} kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} < 1.00 | 15 | DaemonSet退出回退。 |
|
KubeContainerWaiting | sum by (namespace, pod, container) (kube_pod_container_status_waiting_reason{job="kube-state-metrics"}) > 0 | 60 | 容器等待。 |
|
KubeDaemonSetNotScheduled | kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} - kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} > 0 | 10 | DaemonSet无计划。 |
|
KubeDaemonSetMisScheduled | kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} > 0 | 15 | Daemon缺失计划。 |
|
KubeCronJobRunning | time() - kube_cronjob_next_schedule_time{job="kube-state-metrics"} > 3600 | 60 | 若Cron任务完成时间大于1小。 |
|
KubeJobCompletion | kube_job_spec_completions{job="kube-state-metrics"} - kube_job_status_succeeded{job="kube-state-metrics"} > 0 | 60 | 任务完成。 |
|
KubeJobFailed | kube_job_failed{job="kube-state-metrics"} > 0 | 15 | 任务失败。 |
|
KubeHpaReplicasMismatch | (kube_hpa_status_desired_replicas{job="kube-state-metrics"} != kube_hpa_status_current_replicas{job="kube-state-metrics"}) and changes(kube_hpa_status_current_replicas[15m]) == 0 | 15 | HPA副本不匹配。 |
|
KubeHpaMaxedOut | kube_hpa_status_current_replicas{job="kube-state-metrics"} == kube_hpa_spec_max_replicas{job="kube-state-metrics"} | 15 | HPA副本超过最大值。 |
|
KubeCPUOvercommit | sum(namespace:kube_pod_container_resource_requests_cpu_cores:sum{}) sum(kube_node_status_allocatable_cpu_cores) > (count(kube_node_status_allocatable_cpu_cores)-1) count(kube_node_status_allocatable_cpu_cores) | 5 | CPU过载。 |
|
KubeMemoryOvercommit | sum(namespace:kube_pod_container_resource_requests_memory_bytes:sum{}) sum(kube_node_status_allocatable_memory_bytes) > (count(kube_node_status_allocatable_memory_bytes)-1) count(kube_node_status_allocatable_memory_bytes) | 5 | 存储过载。 |
|
KubeCPUQuotaOvercommit | sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="cpu"}) sum(kube_node_status_allocatable_cpu_cores) > 1.5 | 5 | CPU额度过载。 | 无该指标 |
KubeMemoryQuotaOvercommit | sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="memory"}) sum(kube_node_status_allocatable_memory_bytes{job="node-exporter"}) > 1.5 | 5 | 存储额度过载。 |
|
KubeQuotaExceeded | kube_resourcequota{job="kube-state-metrics", type="used"} ignoring(instance, job, type) (kube_resourcequota{job="kube-state-metrics", type="hard"} > 0) > 0.90 | 15 | 若配额超过限制。 |
|
CPUThrottlingHigh | sum(increase(container_cpu_cfs_throttled_periods_total{container!="", }[5m])) by (container, pod, namespace) sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace) > ( 25 / 100 ) | 15 | CPU过热。 |
|
KubePersistentVolumeFillingUp | kubelet_volume_stats_available_bytes{job="kubelet", metrics_path="/metrics"} / kubelet_volume_stats_capacity_bytes{job="kubelet", metrics_path="/metrics"} < 0.03 | 1 | 存储卷容量即将不足。 |
|
KubePersistentVolumeErrors | kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"} > 0 | 5 | 存储卷容量出错。 |
|
KubeVersionMismatch | count(count by (gitVersion) (label_replace(kubernetes_build_info{job!~"kube-dns|coredns"},"gitVersion","$1","gitVersion","(v[0-9]*.[0-9]*.[0-9]*).*"))) > 1 | 15 | 版本不匹配。 |
|
KubeClientErrors | (sum(rate(rest_client_requests_total{code=~"5.."}[5m])) by (instance, job) / sum(rate(rest_client_requests_total[5m])) by (instance, job)) > 0.01 | 15 | 客户端出错。 |
|
KubeAPIErrorBudgetBurn | sum(apiserver_request:burnrate1h) > (14.40 * 0.01000) and sum(apiserver_request:burnrate5m) > (14.40 * 0.01000) | 2 | API错误过多。 |
|
KubeAPILatencyHigh | ( cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} > on (verb) group_left() ( avg by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0) + 2*stddev by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0) ) ) > on (verb) group_left() 1.2 * avg by (verb) (cluster:apiserver_request_duration_seconds:mean5m{job="apiserver"} >= 0) and on (verb,resource) cluster_quantile:apiserver_request_duration_seconds:histogram_quantile{job="apiserver",quantile="0.99"} > 1 | 5 | API延迟过高。 |
|
KubeAPIErrorsHigh | sum(rate(apiserver_request_total{job="apiserver",code=~"5.."}[5m])) by (resource,subresource,verb) / sum(rate(apiserver_request_total{job="apiserver"}[5m])) by (resource,subresource,verb) > 0.05 | 10 | API错误过多。 |
|
KubeClientCertificateExpiration | apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(job) histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 604800 | 无 | 客户端认证过期。 |
|
AggregatedAPIErrors | sum by(name, namespace)(increase(aggregator_unavailable_apiservice_count[5m])) > 2 | 无 | 聚合API出错。 |
|
AggregatedAPIDown | sum by(name, namespace)(sum_over_time(aggregator_unavailable_apiservice[5m])) > 0 | 5 | 聚合API下线。 |
|
KubeAPIDown | absent(up{job="apiserver"} == 1) | 15 | API下线。 |
|
KubeNodeNotReady | kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"} == 0 | 15 | Node未准备好。 |
|
KubeNodeUnreachable | kube_node_spec_taint{job="kube-state-metrics",key="node.kubernetes.io/unreachable",effect="NoSchedule"} == 1 | 2 | Node无法获取。 |
|
KubeletTooManyPods | max(max(kubelet_running_pod_count{job="kubelet", metrics_path="/metrics"}) by(instance) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"}) by(node) / max(kube_node_status_capacity_pods{job="kube-state-metrics"} != 1) by(node) > 0.95 | 15 | Pod过多。 |
|
KubeNodeReadinessFlapping | sum(changes(kube_node_status_condition{status="true",condition="Ready"}[15m])) by (node) > 2 | 15 | 准备状态变更次数过多。 |
|
KubeletPlegDurationHigh | node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile{quantile="0.99"} >= 10 | 5 | PLEG持续时间过长。 |
|
KubeletPodStartUpLatencyHigh | histogram_quantile(0.99, sum(rate(kubelet_pod_worker_duration_seconds_bucket{job="kubelet", metrics_path="/metrics"}[5m])) by (instance, le)) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"} > 60 | 15 | Pod启动延迟过高。 |
|
KubeletDown | absent(up{job="kubelet", metrics_path="/metrics"} == 1) | 15 | Kubelet下线。 |
|
KubeSchedulerDown | absent(up{job="kube-scheduler"} == 1) | 15 | Kube-scheduler日程下线。 |
|
KubeControllerManagerDown | absent(up{job="kube-controller-manager"} == 1) | 15 | Controller Manager下线。 |
|
TargetDown | 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 | 10 | 目标下线。 |
|
NodeNetworkInterfaceFlapping | changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) > 2 | 2 | 网络接口状态变更过频繁。 |
|