





作者:匡澄,中国移动云能力中心助理软件开发工程师,专注于云原生、微服务等领域。
01
背景
karmada项目于2021年4月25日在华为开发者大会2021(HDC.Cloud)上正式宣布开源。同年9月,karmada项目正式捐赠给云原生计算基金会CNCF,成为CNCF首个多云容器编排项目。karmada项目的加入,也将CNCF的云原生版图进一步扩展至分布式云领域。
karmada旨在为多云和混合云场景中的多集群应用程序管理提供自动化功能,具有集中式多云管理,高可用性,故障恢复和流量调度等关键功能。简而言之,karmada的出现能够让开发者像使用单个k8s集群一样使用多个k8s集群。
l官方网站:https://karmada.io/
l代码地址:https://github.com/karmada-io/karmada
02
Karmada 总体框架
使用karmada管理的多云环境包含两类集群:
1.host集群:即由karmada控制面构成的集群,接受用户提交的应用部署需求,将之同步到member集群,并从member集群同步应用后续的运行状况;
2.member集群:由一个或多个k8s集群构成,负责运行用户提交的应用。
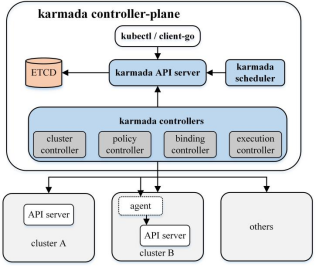
图1 karmada总体架构
karmada control-plane 由以下部件组成:
lkarmada API server
lkarmada controller manager
ncluster controller:成员集群的生命周期管理与对象管理。
npolicy controller:监听propagation policy对象,创建resource binding。
nbinding controller:监听resource binding对象,并创建work对象。
nexecution controller:监听work对象,并将资源分发到成员集群中。
lkarmada scheduler
其中ETCD存储karmada API 对象,API server是所有其他组件都与之通信的REST节点,karmada controller manger 根据通过API server创建的API对象执行操作。同时,karmada controller manger运行各种controllers,这些controllers监视karmada对象,然后与member集群的API server通信,以创建常规的k8s资源对象或者CRD资源。
03
Karmada 资源对象部署设计

图2 资源对象、部署策略、差异化配置策略yaml
在karmada中,用户需要分别创建资源模板(resource template)、部署策略(propagation policy)和差异化配置策略(override policy)3个对象。
l资源模板(resource template)
定义一个标准的k8s中原生API对象deployment
1.在member集群中实际部署的deployment会以此为模板进行创建;
2.在差异化配置策略(override policy)下,每个member集群部署的deployment又不尽相同。
l部署策略(propagation policy)
说明deployment对象需要被部署到member1和member2集群中
1.spec.placement.clusterAffinity.clusterNames决定了对象需要被部署到哪些集 群;
2.spec.resourceSelectors绑定需要部署的资源对象;
3.spec.replicaScheduling定义了deployment在集群中分发的方式,”divided“表示将nginx的deployment的replica数量切分到成员集群上,"weighted"表示切分的时候按照权重设定切分比列,也就是说1:1的权重将原本的deployment的replica分配到member1和member2两个成员集群上。
l差异化配置策略(override policy)
定义在特定member集群中具体修改deployment对象
1.spec.targetCluster定义了需要在member集群中进行修改deployment对象;
2.spec.overriders表示具体如何修改部署在member1的deployment对象。
04
Karmada 资源对象部署具体实现
karmada中的karmada controller manager组件基于sigs.k8s.io/controller-runtime实现,在单独的goroutine中运行了一系列controller。这些controller配合karmada scheduler,处理由用户提交的k8s原生API资源(比如前面例子中的deployment)或CRD资源、以及propagation policy、overrides policy等karmada自定义API资源对象,实现资源部署。其中与资源下发部署相关的controller及其发挥的作用如下:
lresource detector
监听propagation policy和k8s原生API资源对象(包含CRD对象)的变化,绑定两者输出resource binding;
lbinding controller
将resource binding转换为work;
lexecution controller
将生成的work对象(其中包含k8s原生的API资源或者CRD资源)同步到成员集群中。
如图3所示,描述了karmada中API资源的转化处理流程,以及上述组件的作用。下面根据源码依次描述其流程逻辑。
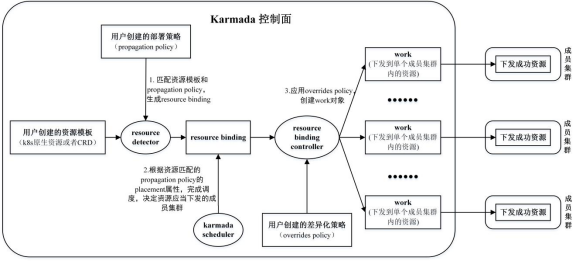
图3 karmada资源对象部署流程
4.1 resource detector 处理流程
resource detector由karmada controller manager负责启动(调用其Start方法)。主要作用在于绑定用户创建的k8s原生API资源对象(包括CRD对象)和propagation policy。该模块的输入是使用list/watch机制监控到的这两类资源的变更事件,而输出是绑定完成的resource binding对象。
// pkg/detector/detector.gofunc (d *ResourceDetector) Start(ctx context.Context) error {klog.Infof("Starting resource detector.")// 用户创建的资源对象查找是否有匹配的 propagation policy// 如果匹配不到,如果无法找到,则暂时将该对象放入 resource detector的 waitingObjects map 成员中d.waitingObjects = make(map[keys.ClusterWideKey]struct{})d.stopCh = ctx.Done()// 运行一个名为"propagationPolicy reconciler"的 AsyncWorkerpolicyWorkerOptions := util.Options{Name: "propagationPolicy reconciler",KeyFunc: ClusterWideKeyFunc, // 生成一个 cluster keyReconcileFunc: d.ReconcilePropagationPolicy, // 解决 propagation policy 发生变化时}......// 运行一个名为"resource detector"的 AsyncWorkerdetectorWorkerOptions := util.Options{Name: "resource detector",KeyFunc: ClusterWideKeyFunc,ReconcileFunc: d.Reconcile, // 主要作用: 资源对象和 propagation policy 匹配,生成 resource bindingRateLimiterOptions: d.RateLimiterOptions, // 队列限速设置}......}// pkg/detector/detector.go// propagation policy 去匹配资源对象 objectfunc (d *ResourceDetector) ReconcilePropagationPolicy(key util.QueueKey) error {ckey, ok := key.(keys.ClusterWideKey)......// 根据 namespace 去获取 propagation policyunstructuredObj, err := d.propagationPolicyLister.Get(ckey.NamespaceKey())// 如果不存在, 解决 propagation policy 被删除的情况if err != nil {if apierrors.IsNotFound(err) {klog.Infof("PropagationPolicy(%s) has been removed.", ckey.NamespaceKey())return d.HandlePropagationPolicyDeletion(ckey.Namespace, ckey.Name)}......}......// 当 propagation policy 被创建,会去 d.waitingObjects 中寻找是否有合适的资源对象 object 与之匹配return d.HandlePropagationPolicyCreation(propagationObject)}// pkg/detector/detector.go// 资源对象 object 去匹配 propagation policyfunc (d *ResourceDetector) Reconcile(key util.QueueKey) error {// 获取在一个集群下资源的所有信息,包括 group version kind name namespace// 通过这些信息可以在一个集群下唯一定位一个资源clusterWideKey, ok := key.(keys.ClusterWideKey)......// 获取具体资源对象 objectobject, err := d.GetUnstructuredObject(clusterWideKey)if err != nil {if apierrors.IsNotFound(err) {// 如果找不到,就将资源对象 object 从 d.waitingObjects 删除d.RemoveWaiting(clusterWideKey)......}return err}// 资源对象 object 尝试去匹配propagationPolicy, err := d.LookForMatchedPolicy(object, clusterWideKey)if propagationPolicy != nil {// 判断 propagation policy.Spec.DependentOverrides 是否存在if present, err := helper.IsDependentOverridesPresent(d.Client, propagationPolicy); err != nil || !present {return fmt.Errorf("waiting for dependent overrides")}// 将资源对象 object 从 d.waitingObjects 删除d.RemoveWaiting(clusterWideKey)// ApplyPolicy - 将资源对象 object 和 propagation policy 绑定,生成 resource bindingreturn d.ApplyPolicy(object, clusterWideKey, propagationPolicy)}if d.isWaiting(clusterWideKey) {// 程序到这里,就说明资源对象 object 找不到对应的 propagation policyd.EventRecorder.Event(object, corev1.EventTypeWarning, workv1alpha2.EventReasonApplyPolicyFailed, "No policy match for resource")return nil}// 如果找不到,就继续放入 d.waitingObjects 中,知道找到合适的 propagation policyd.AddWaiting(clusterWideKey)......}
resource detector在一个单独的goroutine中运行名为"propagationPolicy reconciler"的 AsyncWorker,让它处理propagation policy的变更事件,具体表现为当新建一个propagation policy时,就会通过propagation policy yaml文件中的spec.resourceSelector,去d.waitingObjects寻找是否有能够匹配上的k8s的API原生资源(包括CRD资源),如果能够匹配上,就加入AsyncWorker队列中生成resource binding对象。但删除一个propagation policy时,则相关联的resource binding对象也会被删除,同时其匹配的k8s的API原生资源(包括CRD资源)会继续放入d.waitingObjects中,去等待下一个合适的propagation policy。
resource detector在一个单独的goroutine中运行名为"resource detector"的 AsyncWorker,让它负责处理用户创建的k8s原生API资源对象(包括CRD资源)的变更事件。当用户创建了一个deployment对象,resource detector会在list/watch的本地缓存中查找是否有匹配的propagation policy(由propagation policy yaml文件中的spec.resourceSelector决定),如果能够找到,则表示绑定成功,后续开始生成resource binding对象的流程。如果无法找到,则将对象放入d.waitingObjects中。
当资源对象和propagation policy匹配完成以后,通过resource detector的ApplyPolicy函数中d.BuildResourceBinding方法生成reosurce binding对象,通过d.ClaimPolicyForObject方法在资源对象的labels打上标签,如图4所示。
4.2 karmada scheduler 处理流程
karmada scheduler根据上一步resource detector的输出结果resource binding,通过调度算法决定k8s原生API资源对象(包括CRD资源)的调度结果,即应该调度到哪些member集群中。karmada scheduler的输入是使用list/watch机制监控的resource binding的变更事件,而输出是为resource binding加上调度结果.spec.clusters。
// pkg/scheduler/scheduler.gofunc (s *Scheduler) doScheduleBinding(namespace, name string) (err error) {rb, err := s.bindingLister.ResourceBindings(namespace).Get(name)......policyPlacement, policyPlacementStr, err := s.getPlacement(rb)// 1. 调和调度(ReconcileSchedule)if appliedPlacement := util.GetLabelValue(rb.Annotations, util.PolicyPlacementAnnotation); policyPlacementStr != appliedPlacement {.......}// 2. 扩缩容调度(ScaleSchedule)if policyPlacement.ReplicaScheduling != nil && util.IsBindingReplicasChanged(&rb.Spec, policyPlacement.ReplicaScheduling) {......// 3. 首次调度(FirstSchedule)if rb.Spec.Replicas == 0 ||policyPlacement.ReplicaScheduling == nil ||policyPlacement.ReplicaScheduling.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDuplicated {klog.V(3).Infof("Start to schedule ResourceBinding(%s/%s) as scheduling type is duplicated", namespace, name)err = s.scheduleResourceBinding(rb)metrics.BindingSchedule(string(ReconcileSchedule), utilmetrics.DurationInSeconds(start), err)return err}// 4. 无需调度(AvoidSchedule)klog.V(3).Infof("Don't need to schedule ResourceBinding(%s/%s)", namespace, name)return nil}// pkg/scheduler/scheduler.gofunc (s *Scheduler) scheduleResourceBinding(resourceBinding *workv1alpha2.ResourceBinding) (err error) {klog.V(4).InfoS("Begin scheduling resource binding", "resourceBinding", klog.KObj(resourceBinding))defer klog.V(4).InfoS("End scheduling resource binding", "resourceBinding", klog.KObj(resourceBinding))// 1. 获取 resource binding 相关 policy.placementplacement, placementStr, err := s.getPlacement(resourceBinding)......// 2. 根据算法进行调度scheduleResult, err := s.Algorithm.Schedule(context.TODO(), &placement, &resourceBinding.Spec, &core.ScheduleAlgorithmOption{EnableEmptyWorkloadPropagation: s.enableEmptyWorkloadPropagation})......// 3. 更新 rb.spec.clusters 以及 rb.annotationsklog.V(4).Infof("ResourceBinding %s/%s scheduled to clusters %v", resourceBinding.Namespace, resourceBinding.Name, scheduleResult.SuggestedClusters)return s.patchScheduleResultForResourceBinding(resourceBinding, placementStr, scheduleResult.SuggestedClusters)}
当karmada scheduler的worker方法逐一处理内部队列中的resouce binding的更新事件时,这些resource binding对象可能处于以下几种状态,这些不同的状态决定了scheduler下一步处理流程:
l调和调度(ReconcileSchedule)
用户更新了propagation policy的placement,系统的实际运行状态与用户的期望不一致;
l扩缩容调度(ScaleSchedule)
当propagation policy包含的replica scheduling strategy与集群联邦中实际运行的replica数量不一致;
l首次调度(FirstSchedule)
resource binding从未经过karmada scheduler的调度处理,其.spec.clusters为空,或者在集群中分发的方式为"duplicated",即复制;
l无需调度(AvoidSchedule)
上次调度结果中的成员集群状态均为就绪(ready),也就是resource binding的.spec.clusters包含的成员集群状态全都是就绪(ready)。
这里重点分析首次调度(FirstSchedule)的处理流程,该流程由scheduler的scheduleResourceBinding函数定义:
1.获取resource binding涉及的propagation policy的placement,如前面nginx例子中的placement指定将nginx调度到member1和member2集群中;
2.根据placement和调度算法完成调度,得到调度结果(scheduleResult. SuggestedClusters);
3.将调度结果(scheduleResult.SuggestedClusters)写到resource binding的.spec.cluster中;
4.将序列化后的placement写到resource binding的annotation中,annotation的key为policy.karmada.io/applied-placement
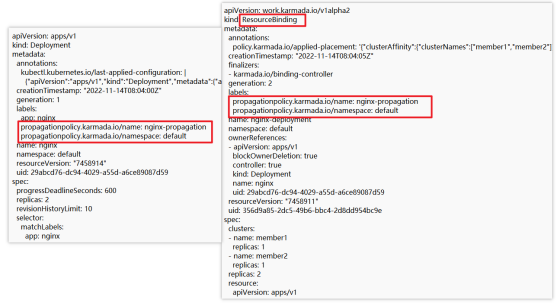
图4 deployment、经过karmada scheduler 的resource binding yaml文件
4.3 binding controller 处理流程
在上述的例子中,在经过karmada scheduler后,binding controller主要就是处理resource binding资源对象的增删改逻辑,会将这个resource binding转换成两个work,对应于member1集群和member2集群。
// pkg/controllers/binding/binding_controller.gofunc (c *ResourceBindingController) syncBinding(binding *workv1alpha2.ResourceBinding) (controllerruntime.Result, error) {.......// 获取 workloads - 位于 resource binding.Spec.Resourceworkload, err := helper.FetchWorkload(c.DynamicClient, c.InformerManager, c.RESTMapper, binding.Spec.Resource)......// 生成 work(具体流程见下面函数)err = ensureWork(c.Client, c.ResourceInterpreter, workload, c.OverrideManager, binding, apiextensionsv1.NamespaceScoped)......// 聚合资源绑定工作状态将收集当前资源绑定对象的所有工作状态,然后将状态信息聚合到 resource binding 状态err = helper.AggregateResourceBindingWorkStatus(c.Client, binding, workload).......// 更新 resource binding.statuserr = c.updateResourceStatus(binding).......}// pkg/controllers/binding/common.gofunc ensureWork(c client.Client, resourceInterpreter resourceinterpreter.ResourceInterpreter, workload *unstructured.Unstructured,overrideManager overridemanager.OverrideManager, binding metav1.Object, scope apiextensionsv1.ResourceScope,) error {......// 遍历经过 schedule 调度后的结果 targetClustersfor i := range targetClusters {targetCluster := targetClusters[i]clonedWorkload := workload.DeepCopy()// 根据集群名字 targetCluster.Name 生成 work namespace 的名字 - 例如:karmada-es-member1workNamespace, err := names.GenerateExecutionSpaceName(targetCluster.Name)......if hasScheduledReplica {// HookEnabled 查看资源类型对象是否存在需要修改副本数的工作,如果有就执行if resourceInterpreter.HookEnabled(clonedWorkload.GroupVersionKind(), configv1alpha1.InterpreterOperationReviseReplica) {// ReviseReplica 在目标集群中修改资源对象副本数量clonedWorkload, err = resourceInterpreter.ReviseReplica(clonedWorkload, desireReplicaInfos[targetCluster.Name])......}......// ApplyOverridePolicies 在特定目标集群上去执行 overrides policy// 如果有多个 overrides policy 存在,则按照以下的规则:// 对于 cluster scoped 资源,按策略名称升序去执行 cluster override policy// 对于 namespaced scoped 资源,先执行 cluster override policy,然后再执行 override policycops, ops, err := overrideManager.ApplyOverridePolicies(clonedWorkload, targetCluster.Name)......// 更新 work 对象的 labels 和 annotationsworkLabel := mergeLabel(clonedWorkload, workNamespace, binding, scope)annotations := mergeAnnotations(clonedWorkload, binding, scope)annotations, err = RecordAppliedOverrides(cops, ops, annotations)......// 更新 workif err = helper.CreateOrUpdateWork(c, workMeta, clonedWorkload); err != nil {return err}}return nil}
1.通过resource binding生成work的流程由syncBinding函数定义:helper.FetchWorkload通过resource binding.spec.resource获取需要下发的资源对象workload;
2.通过ensureWork方法生成work对象,一个work只能属于一个集群,代表一个集群的资源对象的模型封装,work对象的名字"karmada-es-[目标集群的名字]",如执行kubectl --kubeconfig=karmada-config get work -A,可以看到信息:

同时,overrideManager.ApplyOverridePolicies方法实现了overrides policy和work对象的绑定,具体变现为将override policy信息写的work.Annotations中,后续下发到成员集群中,完成差异化配置部署。同时在work.Annotations和work.labels也完成了和相应resource binding的绑定,图5展示了karmada-es-member1 work的yaml(由于篇幅限制截取部分);
3.helper.AggregateResourceBindingWorkStatus方法更新了resource binding.status的信息
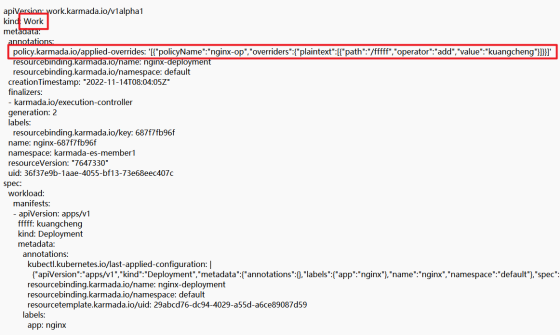
图5 karmada-es-member1 work yaml
4.4 execution controller 处理流程
execution controller主要就是处理work资源对象的增删改逻辑,用于处理work,将work负责的k8s资源对象在对应的集群上创建出来。
// pkg/controllers/execution/execution_congtoller.gofunc (c *Controller) syncToClusters(clusterName string, work *workv1alpha1.Work) error {var errs []errorsyncSucceedNum := 0for _, manifest := range work.Spec.Workload.Manifests {// 从 work 对象的 spec.workload.manifests 获取要在集群中部署的资源对象 workloadworkload := &unstructured.Unstructured{}err := workload.UnmarshalJSON(manifest.Raw)......// 判断是否已经在该成员集群中部署过了applied := helper.IsResourceApplied(&work.Status)if applied {// 如果部署过了就更新err = c.tryUpdateWorkload(clusterName, workload)......} else {// 没有部署过就重新创建err = c.tryCreateWorkload(clusterName, workload).......}// 生成相对应的事件:成功c.eventf(workload, corev1.EventTypeNormal, workv1alpha1.EventReasonSyncWorkSucceed, "Successfully applied resource(%v/%v) to cluster %s", workload.GetNamespace(), workload.GetName(), clusterName)syncSucceedNum++}......// 更新 work status conditionserr := c.updateAppliedCondition(work, metav1.ConditionTrue, "AppliedSuccessful", "Manifest has been successfully applied")......return nil}
正如上述代码所描述:
1.syncToClusters函数传入参数为成员集群名和work对象;
2.从work对象的 spec.workload.manifests 获取要在集群中部署的资源对象具体信息 workload;
3.通过work.status判断资源对象是否在该成员集群中已经被部署了;
4.如果已经创建,就更新c.tryUpdateWorkload,反之则新建c.tryCreateWorkload;
5.最后更新work.status。
05
Karmada 实践 - 部署一个简单应用
使用karmada在多集群环境下部署一个nginx应用:(yaml文件中的代码如图2所示,karmada-config表示karmada的配置文件)
1.切换到karmda控制面
kubectl --kubeconfig=karmada-config config use-context Karmada-apiserver
2.创建资源模板deployment
kubectl --kubeconfig=Karmada-config apply -f deployment.yaml
3.创建部署策略propagation policy
kubectl --kubeconfig=karmada-config apply -f propagationpolicy.yaml
4.创建差异化配置策略overrides policy
kubectl --kubeconfig=karmada-config apply -f overridespolicy.yaml
5.在karmada控制面查看部署结果
kubectl --kubeconfig=karmada-config get deploy nginx

6.在member1中查看部署结果 (member1表示member1集群的配置文件)
kubectl --kubeconfig=member1 get deploy nginx

参考文献
1.http://Karmada.io/
2.https://zhuanlan.zhihu.com/p/407990257
3.https://blog.csdn.net/aa2528877987/article/details/124312534
4.https://zhuanlan.zhihu.com/p/412589073
▲ 点击上方卡片关注K8s技术圈,掌握前沿云原生技术

