






接受范围|中度
VPA使用户无需为pod中的容器设置资源请求。配置后,它将根据资源(cpu 与内存)使用情况自动设置 requests。在对 pod 的调度过程中,使得每个 pod 都可以使用适当的资源量从而分配到适合的节点上。它既可以缩小资源请求过多的 pod,也可以根据一段时间内的使用情况扩大资源请求不足的 pod。
使用场景
自动资源配置提升管理效率
提高集群资源利用率
社区现状
目前,Kubernetes并不支持pod的in-place-update,因此vpa的auto等同recreate,目前版本的in-place-update还在review当中,并有望在未来的版本中提供,当前版本兼容如下所示。
版本 | K8s release |
0.12 | 1.25+ |
0.11 | 1.22-1.24 |
0.10 | 1.22+ |
0.9 | 1.16+ |

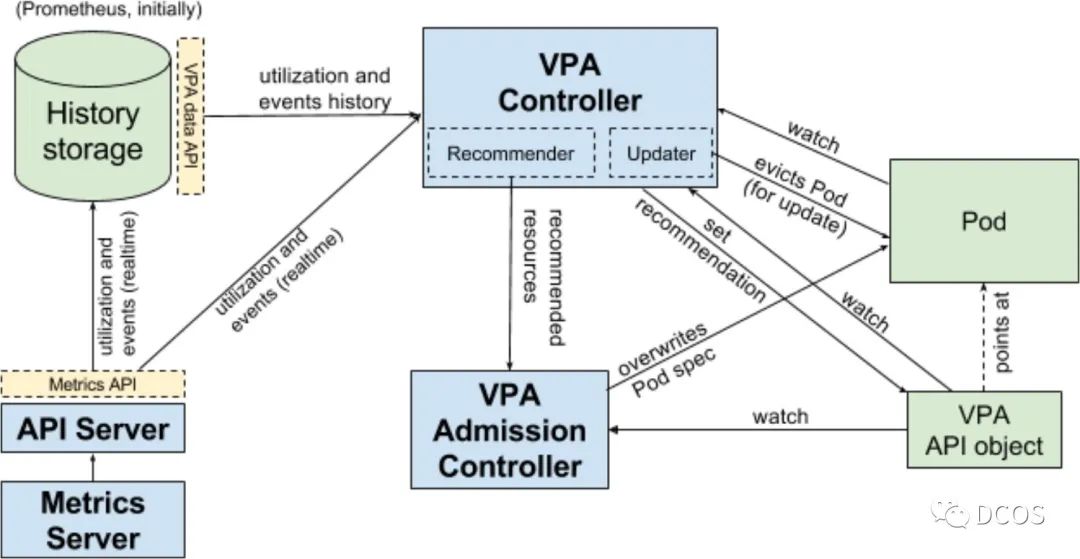
架构简介
VPA主要由三个组件组成,分别为recommender、updater、admission-controller
1)recommender:引入VerticalPodAutoscaler对象,其由 Pod 的标签选择器、资源策略(控制 VPA 如何计算资源)、更新策略(控制如何将更改应用于 Pod)和推荐的 Pod 资源组成,其根据metric-server获取到的容器指标并观测 OOM 事件,计算推荐指标,最终更新VerticalPodAutoscaler对象
2)updater:其是负责Pod更新的组件。如果 Pod 在 "Auto" 模式下使用 VPA,则 Updater 可以决定使用推荐器资源对其进行更新。这只是通过驱逐Pod以便使用新资源重新创建它来实现的。简单来说,其是根据pod的request中设置的指标和recommend计算的推荐指标,在一定条件下驱逐pod,
3)admission-controller:这是一个webhook组件,所有 Pod 创建请求都通过 VPA Admission Controller,如果Pod与VerticalPodAutoscaler 对象匹配,把recommend计算出的指标应用到pod的request和limit,如果 Recommender 不可用,它会回退到 VPA 对象中缓存的推荐。
VerticalPodAutoscaler
该资源由用户创建,用于设置纵向扩容的目标对象和存储recommend组件计算出的推荐指标。
VerticalPodAutoscalerCheckpoint
该资源由recommend组件创建和维护,用于存储指标相关信息。一个vpa对应的多个容器,每个容器创建一个该资源。

VPA实践
VPA部署
a.获取metrics-server manifest
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
b.执行部署
kubectl apply -f components.yaml
c.验证结果
[root@master ~]# kubectl get po -n kube-systemNAME READY STATUS RESTARTS AGEmetrics-server-3358ad021s-wqmc9 1/1 Running 0 5m[root@master ~]# kubectl top nodesNAME CPU(cores) CPU% MEMORY(bytes) MEMORY%master 528m 5% 4385Mi 13%
git clone https://github.com/kubernetes/autoscaler.git
[root@master vertical-pod-autoscaler]# cd autoscaler/vertical-pod-autoscaler[root@master vertical-pod-autoscaler]# ./hack/vpa-up.sh
[root@master ~]# kubectl get po -n kube-systemNAME READY STATUS RESTARTS AGEmetrics-server-3358ad021s-wqmc9 1/1 Running 0 15mvpa-admission-controller-78e7f86645-67897 1/1 Running 0 3mvpa-recommender-tq4f7fb9db-32776 1/1 Running 0 3mvpa-updater-53er87q7qt-5p889 1/1 Running 0 3m
apiVersion: apps/v1kind: Deploymentmetadata:labels:app: testname: nginxspec:replicas: 1selector:matchLabels:app: testtemplate:metadata:labels:app: testspec:containers:- image: nginxname: nginxresources:requests:cpu: 200mmemory: 250Mi
[root@master examples]# kubectl get poNAME READY STATUS RESTARTS AGEpod/nginx-5334b745w3-qwew3 1/1 Running 0 1m
[root@master ~]# cat nginx-test-svc.yamlapiVersion: v1kind: Servicemetadata:name: nginxspec:type: NodePortports:- port: 80targetPort: 80selector:app: test[root@master examples]# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEnginx NodePort 10.99.106.213 <none> 80:31496/TCP 55s[root@k8s-node001 examples]# curl -I 10.99.106.213:31496HTTP/1.1 200 OK
使用updateMode: "Off"模式,其仅计算资源的推荐而不应用Pod
[root@master ~]# cat nginx-vpa-test.yamlapiVersion: autoscaling.k8s.io/v1beta2kind: VerticalPodAutoscalermetadata:name: nginx-vpa-testspec:targetRef:apiVersion: "apps/v1"kind: Deploymentname: nginxupdatePolicy:updateMode: "Off"resourcePolicy:containerPolicies:- containerName: "nginx"minAllowed:cpu: "250m"memory: "100Mi"maxAllowed:cpu: "2000m"memory: "2048Mi"controlledResources: ["cpu", "memory"]
[root@master ~]# kubectl describe vpa nginx-vpa-testName: nginx-vpa-test...Update Policy:Update Mode: OffStatus:Conditions:Last Transition Time: 2022-11-28T03:21:14ZStatus: TrueType: RecommendationProvidedRecommendation:Container Recommendations:Container Name: nginxLower Bound:Cpu: 250mMemory: 262027kTarget:Cpu: 250mMemory: 262027kUncapped Target:Cpu: 50mMemory: 262027kUpper Bound:Cpu: 717mMemory: 650210341Events: <none>
for i in $(seq $(getconf _NPROCESSORS_ONLN)); do yes > /dev/null & done
[root@master ~]# ab -c 200 -n 10000000 http://10.99.106.213:31496/...Benchmarking 10.99.106.213 (be patient)Completed 1000000 requestsCompleted 2000000 requestsCompleted 3000000 requests
[root@master ~]# kubectl describe vpa nginx-vpa |tail -n 20Conditions:Last Transition Time: 2022-11-28T04:14:21ZStatus: TrueType: RecommendationProvidedRecommendation:Container Recommendations:Container Name: nginxLower Bound:Cpu: 250mMemory: 262027kTarget:Cpu: 673mMemory: 262027kUncapped Target:Cpu: 673mMemory: 262027kUpper Bound:Cpu: 2Memory: 650210341Events: <none>

小结
局限性
1.不要将VPA与HPA一起使用,后者基于相同的资源指标(例如CPU和MEMORY使用率)进行缩放。这是因为当指标(CPU/MEMORY)达到其定义的阈值时,VPA和HPA将同时发生缩放事件,这可能会产生未知的副作用并可能导致问题,该处可以进行优化
2. VPA 可能会推荐比集群中可用的资源更多的资源,从而导致 pod 未分配给节点(由于资源不足),因此永远不会运行。为了克服这个限制,最好将LimitRange 设置为最大可用资源。这将确保 pod 不会要求超过 LimitRange 定义的资源,这里会导致资源碎片或节点热点
3.VPA不会驱逐不在控制器下运行的pod,驱逐可以单独处理
优化方向
1.对于非原生workload的优化,针对非原生工作负载,VPA使用scale方式获取,效率较低
2.VPA跟其他controller一样,使用selector模式,可以进行适当优化
3.VPA的历史数据加载只在启动时才会进行,且效率跟性能较低
4.多种推荐算法的支持
5.VPA对象更新瓶颈等
由于笔者时间、视野、认知有限,本文难免出现错误、疏漏等问题,期待各位读者朋友、业界专家指正交流。
1.https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
2. https://github.com/containerd/containerd/pull/6965
 真诚推荐你关注
真诚推荐你关注
▲ 点击上方卡片关注K8s技术圈,掌握前沿云原生技术


