前言:Kafka 作为性能第一梯队的消息中间件被广泛使用,单个节点的处理能力可以达到千万级,吞吐量可以达到数百万级,那 Kafka 是如何做到这么高性能的呢?
在 Kafka 内部,消息都是以批为单位进行处理。
在生产端时,我们调用 send 方法发送消息时,消息不会立刻发到 Broker ,而是先暂存到发送端的本地缓存中;发送端有一个 Sender 线程会定时(配置项:linger.ms)清理缓存批量发送到 Broker,或是本地缓存达到阈值(配置项:batch.size,按照分区维度)也会触发发送。在服务端,Kafka 不会把这批消息进行拆分,再一条条处理,而是将每批消息当作一条消息处理;在 Broker 里,不管是写磁盘,读磁盘,还是同步到其他副本的流程,批消息都不会被解开,一直被当作一条消息处理。在消费端,消息同样是被批量的消费,在客户端才把消息解析成多条(配置项:max.poll.records 控制消费条数)。Kafka 构建批消息和解开批消息分别在发送端和消费端的客户端完成,不仅减轻了 Broker 的压力,还减少了网络请求的消耗,提升整体吞吐量。
我们都知道,Kafka 消息的生产与消费都必须指定 Topic,但 Topic 只是一个逻辑概念;实际在物理层面,消息的存储是基于分区(Partition),一个 Topic 下可以设置多个分区,而多个分区就可以达到并行消费的效果,提高整体吞吐量;另一方面,不同的分区可以位于不同的机器节点(Broker),形成了数据分片,因此可以充分利用集群的资源达到更高的并发度。
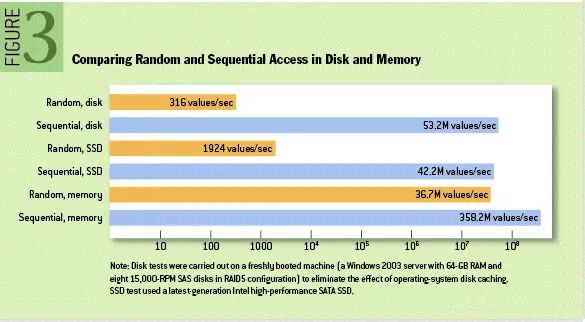
ACM 官网期刊 09 年发布了一篇关于「随机读写与顺序读写性能对比」的论文:https://queue.acm.org/detail.cfm?id=1563874,性能对比图(现在硬盘的性能肯定比当时有提升):固态硬盘:固态硬盘读写数据时,需要先寻址(在磁盘上找到物理地址,固态硬盘寻址速度很快,几乎为 0),再进行数据读写;由于固态硬盘读写操作的基本单元是“块”,顺序读写一块的性能的肯定比随机读写多块的性能更好。机械硬盘:机械硬盘读写数据时,需要以 寻道(平均3~15ms)+ 旋转(平均2ms)的方式寻找位置,再进行读写;由于机械磁盘读写的大部分时间在寻址上,顺序读写只需要顺序移动“磁头”就可以完成,所以机械硬盘的顺序读写性能比随机读写强更多。Kafka 正是利用了顺序读写的特性:Kafka 消息是以分区的维度进行存储,每个分区就是一个文件夹;每次新产生消息,都会顺序写到 log 文件后,一个文件写满了,就另启一个新文件顺序写下去;消费时,也是从某个位置开始顺序读出来;从而避免随机读写磁盘的过程。
PageCache 其实不是专属于 MQ 的,而是现代操作系统都具有的一项特性。当我们的调用文件系统的写入 API:write 时,并不会直接写到磁盘中,而是先写到 PageCache 中,后续异步批量写到磁盘(定时写入或手动调用 fsync 函数),提升写 IO 的性能;(1)如果 PageCache 中有数据,则直接命中返回,省去磁盘 IO 时间;(2)如果 PageCache 中没有数据,操作系统则会发起一个缺页中断,应用线程阻塞,操作系统把数据从磁盘上复制到 PageCache 上,应用线程取消阻塞从 pageCache 上把数据读出来返回。由于 PageCache 的大小有限,PageCache 采用 LRU 或 LRU 变种算法来实现内存淘汰,也就是当空间不足时淘汰最久未被访问的缓存。一般来说,MQ 的消息刚写入到服务端就会被消费,所以读取速度会非常快,间接提高了性能。
Kafka 的服务端在消费过程中,还用了「零拷贝」的技术来提升消费性能。零拷贝是一种减少拷贝次数的技术,并不是一次都不拷贝。// 从磁盘读消息
buffer = File.read(offset)
// 发送消息到客户端
Socket.send(buffer)
(1)用户进程调用 read 方法,DMA(直接内存访问技术) 将磁盘数据「拷贝」到内核缓冲区(PageCache)并通知 CPU,如果命中缓存,这一步拷贝可以省去;(2)CPU 接到通知后将内核缓冲区的数据「拷贝」到用户空间,然后返回数据;(3)用户进程调用 send 发送消息,CPU 将数据从用户空间「拷贝」到内核的 Socket 缓冲区 并通知 DMA;(4)DMA 将 Socket 缓冲区的数据「拷贝」到网卡缓冲区(网卡进行网络传输),完成发送。DMA(Direct Memory Access):直接内存访问技术,将原来 CPU 在 「IO 设备」和「内存」之间的搬运工作交给 DMA,降低 CPU 负荷。
CPU 上下文切换 主要发生在任务切换(例如线程切换)和寄存器切换(例如系统方法调用)的场景上;在系统调用时,CPU 寄存器需要将用户态的指令位置保存起来,然后切换到内核态,以便于执行内核指令,在返回系统调用结果后,CPU 需要再次进行上下文切换,回到应用程序的执行状态继续执行。
所以如果不考虑缓存命中,正常一次消息拉取要经历四次拷贝和四次 CPU 上下文切换(两次系统调用,一次调用会切换两次)。数据拷贝和上下文切换的单次耗时虽然低,但是在高并发场景下,耗时就会被累计和放大,影响系统性能。由于 Kafka 从磁盘读出的消息数据没有做任何处理,直接发到网卡,所以数据实际上没有必要搬运到用户空间。Linux 系统通过 sendfile 系统调用提供了零拷贝技术:ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
sendfile 方法可以直接将内核缓冲区的数据直接拷贝到 Socket 缓冲区(CPU 进行拷贝);相比传统的方式,只需要一次系统调用,所以上下文切换减少到两次,数据拷贝次数降低到三次。如果网卡支持 SG-DMA(THE Scatter-Gather Direct Memory Access)技术,内核缓冲区的数据就可以直接被 DMA 拷贝到网卡缓冲区,再减少一次 CPU 的数据拷贝。在 SG-DMA 技术的加持下,使用 sendfile 只需要两次拷贝和两次上下文切换,并且拷贝的过程都是交由 DMA 控制器去做的。ethtool -k eth0 | grep scatter-gather
如果返回的 “scatter-gather: on”代表网卡支持 SG-DMA 技术。java 的 NIO 包中也提供了零拷贝的支持:java.nio.channels.FileChannel#transferTo/transferFrom,底层就是通过 sendfile 实现的。Kafka 就使用该方法来实现零拷贝,最终达到减少数据拷贝次数和上下文切换次数的效果。
如果觉得文章不错可以点个赞和关注 !
!

参考:
Kafka零拷贝:https://zhuanlan.zhihu.com/p/78335525什么是零拷贝:https://xiaolincoding.com/os/8_network_system/zero_copy.htmlKafka高性能架构之道:http://www.jasongj.com/kafka/high_throughput磁盘I/O那些事:https://tech.meituan.com/2017/05/19/about-desk-io.html固态硬盘跟机械硬盘有什么区别:https://www.zhihu.com/question/267340678ACM 期刊:https://queue.acm.org/detail.cfm?id=1563874