







01
背景
PingCAP原厂并没有提供回退集群版本的明确方式,正常在TIDB集群进行升级操作前,会停机将集群里面的数据进行一次全备,防止集群在升级过程中出现未知的错误,并且无法解决。灾难发生时,会重新建一套升级前版本的集群,然后将升级前全备的数据重新导入来实现集群的回退效果。
在集群数据量特别大的情况下,全备数据和重新导入数据的时间会特别长,导致停机时间窗口可能会无法满足停机时间预算,在咨询原厂工程师集群升级的原理后,经过测试,特整理了集群小版本升级和大版本升级强行回退的方案。
02
小版本升级回退
一、说明
本次升级将v5.1.4版本的集群离线升级到v5.1.5集群,离线升级参考:使用 TiUP 升级 TiDB | PingCAP 文档中心(https://docs.pingcap.com/zh/tidb/stable/upgrade-tidb-using-tiup),并模拟故障,导致升级过程中升级失败,然后再成功回退至v.5.1.4版本集群
二、升级前准备
备份.tiup文件夹
cp -r .tiup .tiup-bak
三、升级故障模拟
在升级后,重启集群前,去其中一个节点下把tikv目录删掉 。
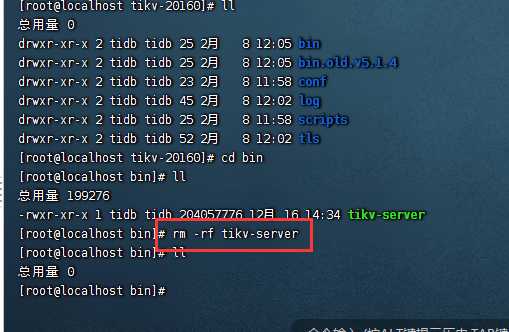
重启集群失败,达到超时时间2min后报错。
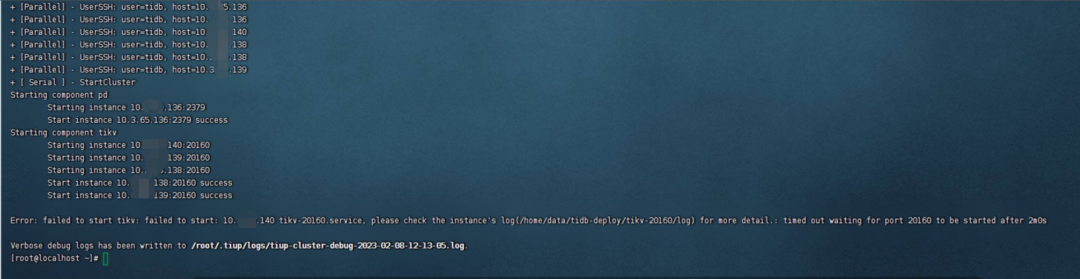
四、回退集群
//依次回退各节点组件
(1)对照display结果
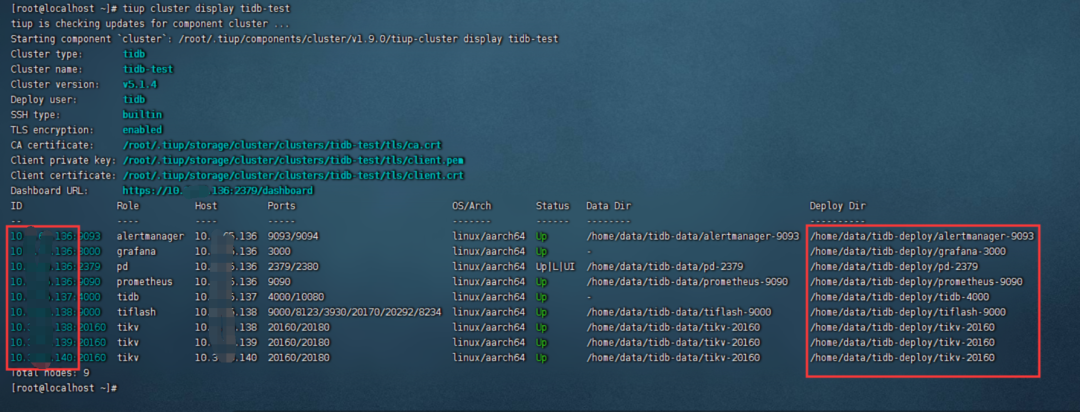
去每个节点上面去回退已安装的组件,需要做出的操作示例:
#登录10.*.*.136节点
cd /home/data/tidb-deploy/alertmanager-9093 //就是deploy dir
ll
(2)确认是否有如下两个文件夹
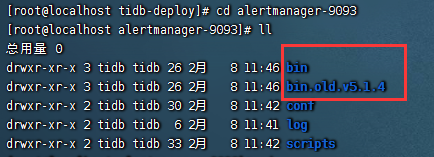
#如果有如图所示的两个文件夹,执行:
mv bin bin-err
mv bin.old.v5.1.4 bin
#如果只有bin文件夹,说明升级是在分发文件过程中报错,该文件未被替换升级,无需进行任何操作
#检查回退后组件版本和5.1.4版本镜像源里面版本是否一致
#这里查看不同组件命令做出对应改变
cd ./bin/alertmanager
./alertmanager --version
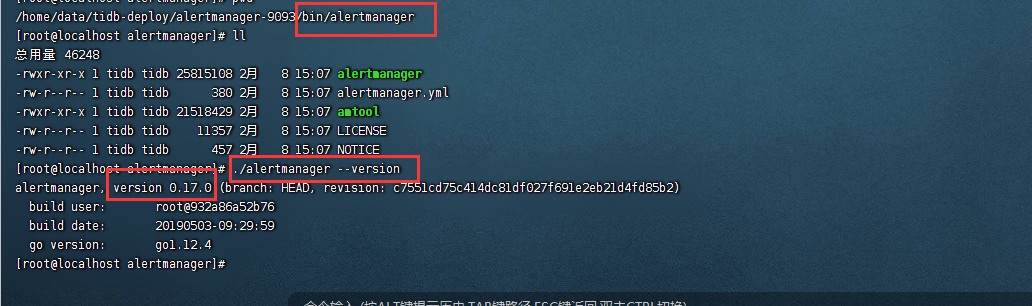
(3)按照display的结果,逐行进行操作,循环重复步骤(1)和(2)
//回退tiup和tiup-cluster
cp -r .tiup .tiup-err
mv .tiup-bak .tiup
#检查下tiup和tiup-cluster版本
tiup -v
tiup cluster -v
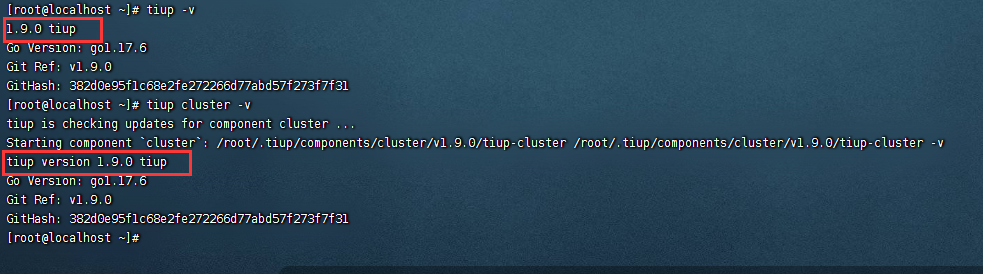
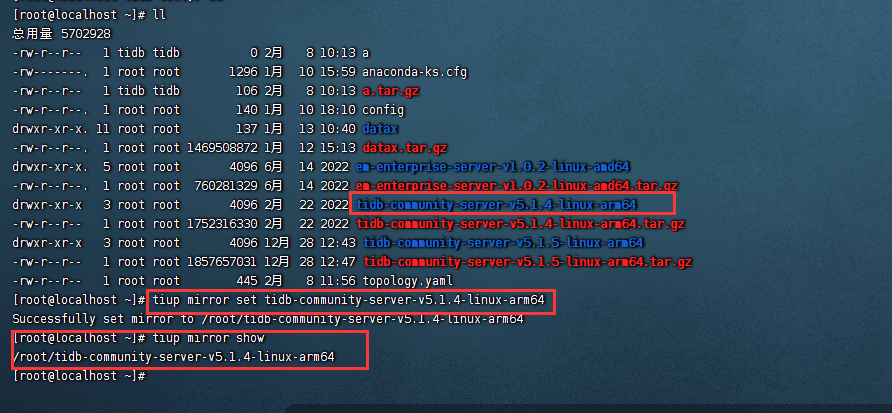
//回退镜像源
#设置镜像源
tiup mirror set tidb-community-server-v5.1.4-linux-amd64
#检查
tiup mirror show
//重启集群
tiup cluster restart tidb-test
//检查回退是否成功
display结果:
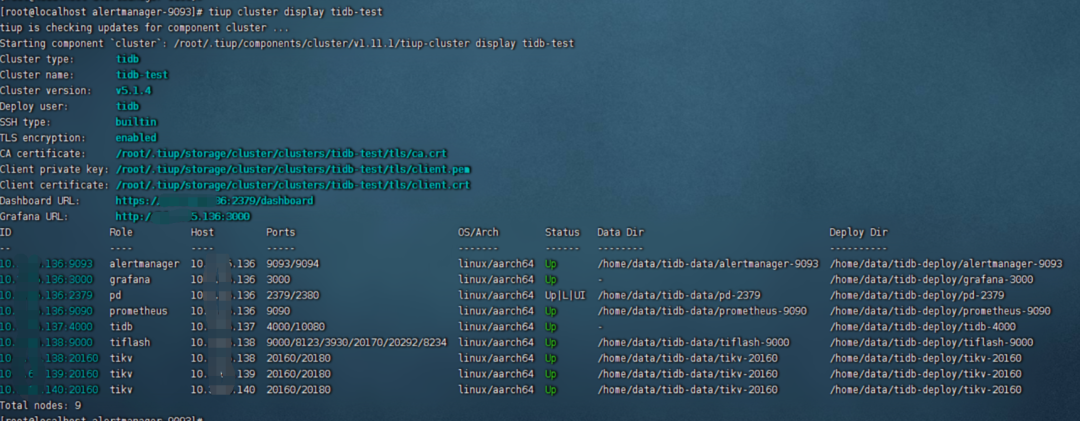
连上数据库去查询tidb版本
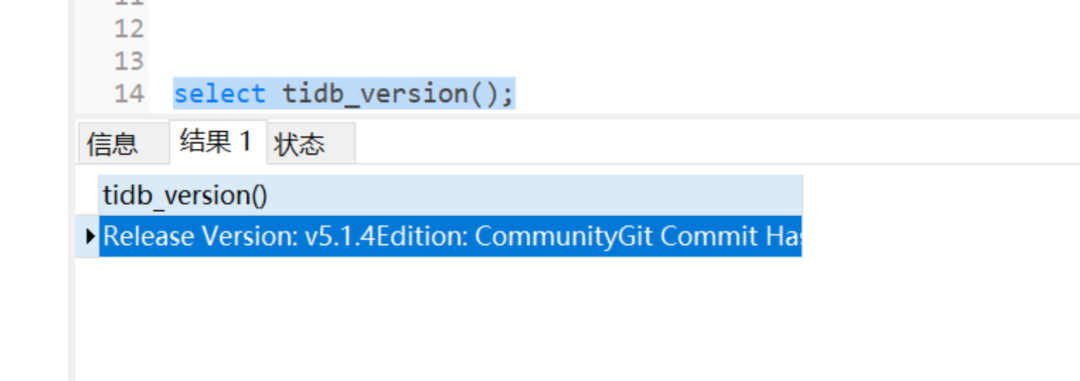
已回退成功!
03
大版本升级回退
一、说明
主要通过将v5.1.4版本的集群正常升级到v6.1.0之后,再按小版本回退的经验去做大版本回退,观察是否能正常回退到v5.1.4版本。
主要验证大版本更新回退是否会有操作范围不一致操作的地方(监控),以及验证大版本回退后集群依旧正常可用
二、监控不会升级,也不回退
在小版本回退的步骤中,v5.1.4和v5.1.5版本所用的监控节点的node_exporter和blackbox_exporter版本并没有更新,所以并没有进行回退。
经过验证在v5.1.4升级到v6.1.0的过程后,详细检查发现监控节点依旧没有进行更新,还是v0.17版本,直接部署v6.1.0集群会是V1.3版本的node_exporter,这里暂且也不用回退
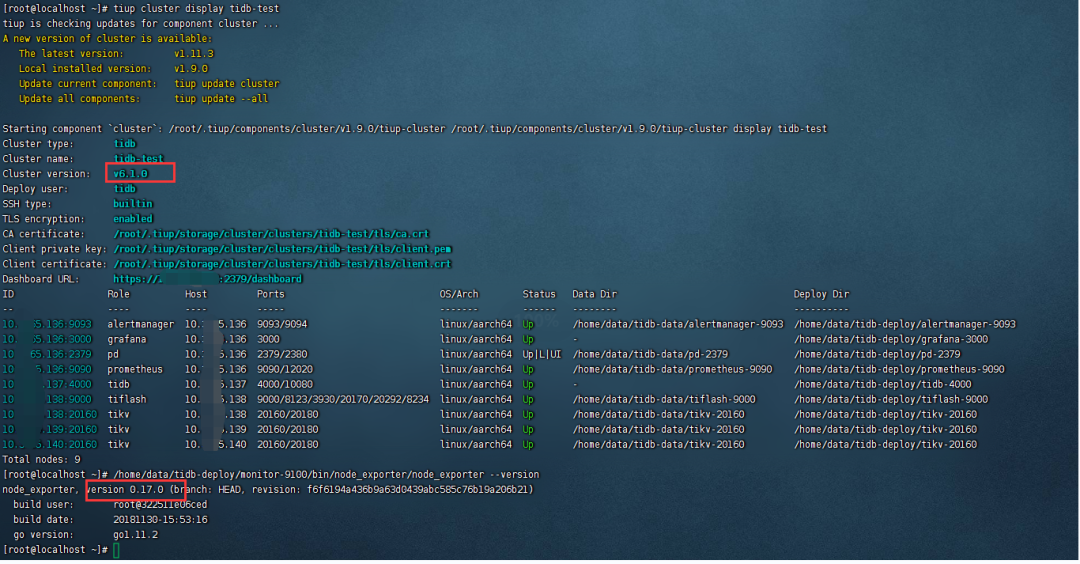
三、回退时重启集群失败
查看具体报错的日志
[2023/03/03 10:55:48.533 +08:00] [INFO] [mod.rs:118] ["encryption: none of key dictionary and file dictionary are found."]
[2023/03/03 10:55:48.533 +08:00] [INFO] [mod.rs:479] ["encryption is disabled."]
[2023/03/03 10:55:48.533 +08:00] [ERROR] [server.rs:992] ["failed to init io snooper"] [err_code=KV:Unknown] [err="\"IO snooper is not started due to not compiling with BCC\""]
[2023/03/03 10:55:48.561 +08:00] [INFO] [engine.rs:479] ["Recover raft log takes 130ns"]
这里对照日志信息去社区查找了一些帖子观察了一下,没有发现特别明显清晰的解决方案。
怀疑是在两个v6.1.0和v5.1.4两个版本中底层数据组织结构产生了一些变化,或者是数据结构的管理方式不太兼容,导致无法通过这种暴力方式去做升级回退。
04
总结
1、生产环境在进行集群升级操作前可以提前在测试环境上测试两个版本是否可以快速强行回退,以具体测试结果为准。
2、升级前还是要做一次全库备份,防止故障发生以及快速回退失败。
(该方案仅供参考,根据实际情况调整)
“
Hello~
这里是神州数码云基地
编程大法,技术前沿,尽在其中
Odoo、数据库、云原生、DevOps等
超多原创技术干货持续输出ing~
想要第一时间获取
超硬技术干货
快快点击关注+设为星标★
拜托拜托啦
这对“我们”都很重要哦~
- END -

往期精选


了解云基地,就现在!

