排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
如何优雅地“甩锅”?10年研发老兵总结分享
如何优雅地“甩锅”?10年研发老兵总结分享
OceanBase数据库星球
2023-04-19
410
余璜
作者介绍
OceanBase 高级技术专家
3月25日,我们在北京举办了首届
「OceanBase 开发者大会」
,与开发者共同探讨单机分布式、云原生、HTAP 等数据库前沿趋势,分享全新的产品 Roadmap,交流场景探索和最佳实践。在
「产品技术专场」
,OceanBase 高级技术专家余璜,为大家带来
《从可诊断性到全链路追踪》
分享,以下内容根据演讲实录整理而成。
直播回放+PPT
,
请关注本公众号,回复"
开发者
"
自 OceanBase 4.0 发布以来,我们在系统的可观测性方面做了很多的努力。今天给大家带来两个我最喜欢的 Feature,
全链路诊断
和
SQL Plan Monitor
。
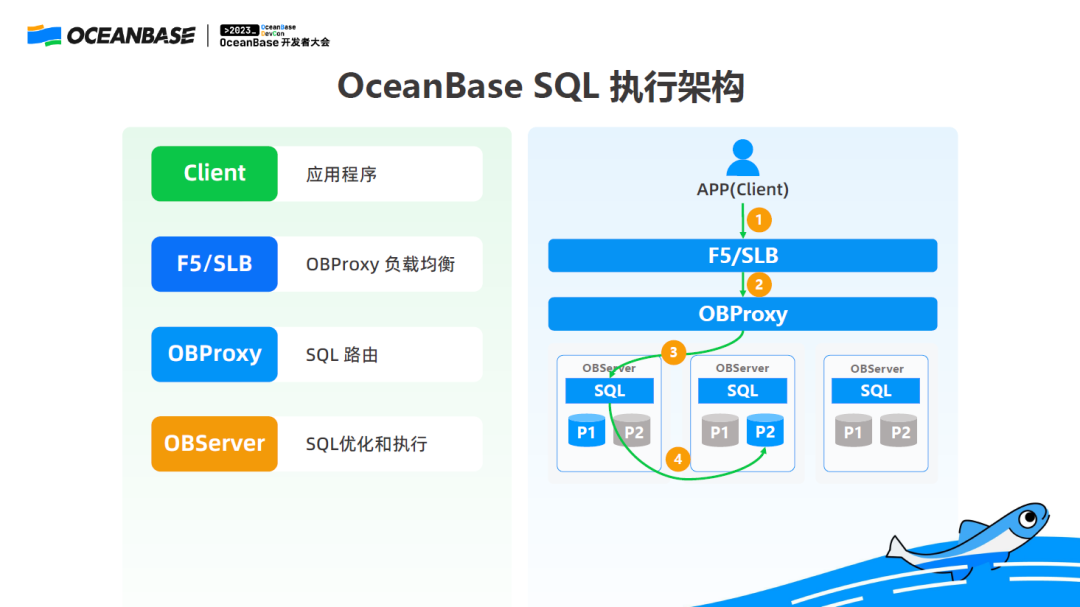
稍微介绍一下背景,这是用户的一条 SQL 进入 OceanBase 内核之前所走的整个链路。
首先会经过一个负载均衡器,负载均衡器帮我们选一个 Proxy,Proxy 再根据这条 SQL 要访问的数据在哪个 OBServer 上,把这条 SQL 路由到正确的 OBServer上,万一 Proxy 路由错了,OBServer 会给它做一个再次的路由,路由到正确的数据上去。
这里面有好几个步骤,需要多个组件配合,万一系统出现了一些延迟变大的情况会怎样?
一条简单 SQL,却需要多人合作来找问题,找来找去,锅就甩给网络了。
实际上,任何一个运维过分布式系统的人,都有类似的经历,当出现 RT 抖动时,需要在整个链路上去找原因。
在 OceanBase 4.0 里,我们推出了一个新功能,叫全链路追踪,可以帮助解决这个甩锅难题。
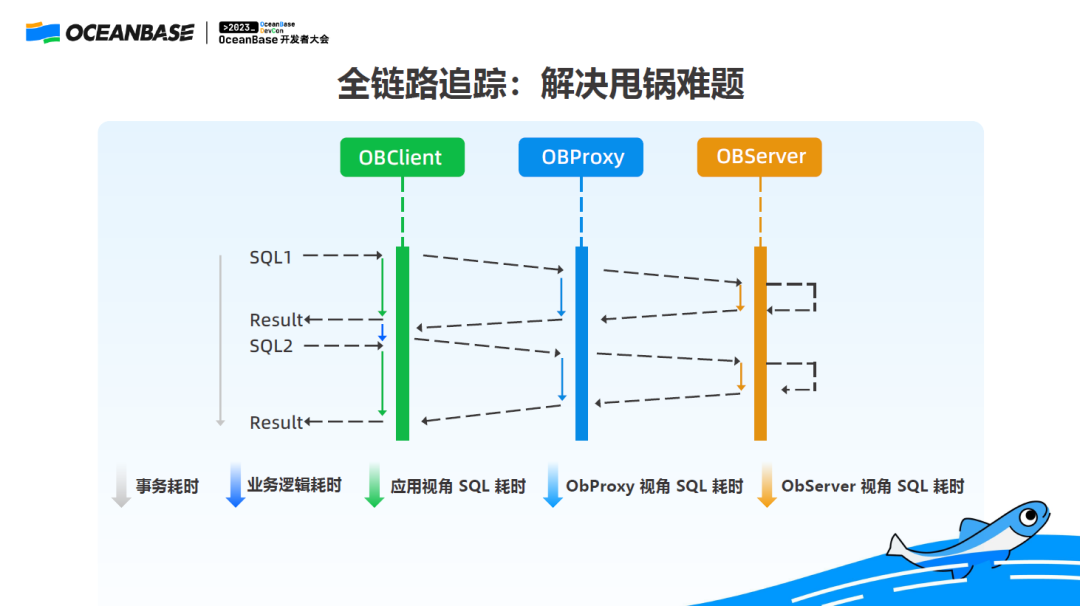
01.
全链路追踪:解决甩锅难题
全链路追踪,可以帮我们从用户角度,在事务层面上,把整个链路的执行全部记录下来,包括事务中每条 SQL 什么时候开始的,消耗了多长时间,以及内部的执行细节。一旦出现 RT 抖动,通过全链路追踪工具,可以非常直观地看到问题出现在哪一步。
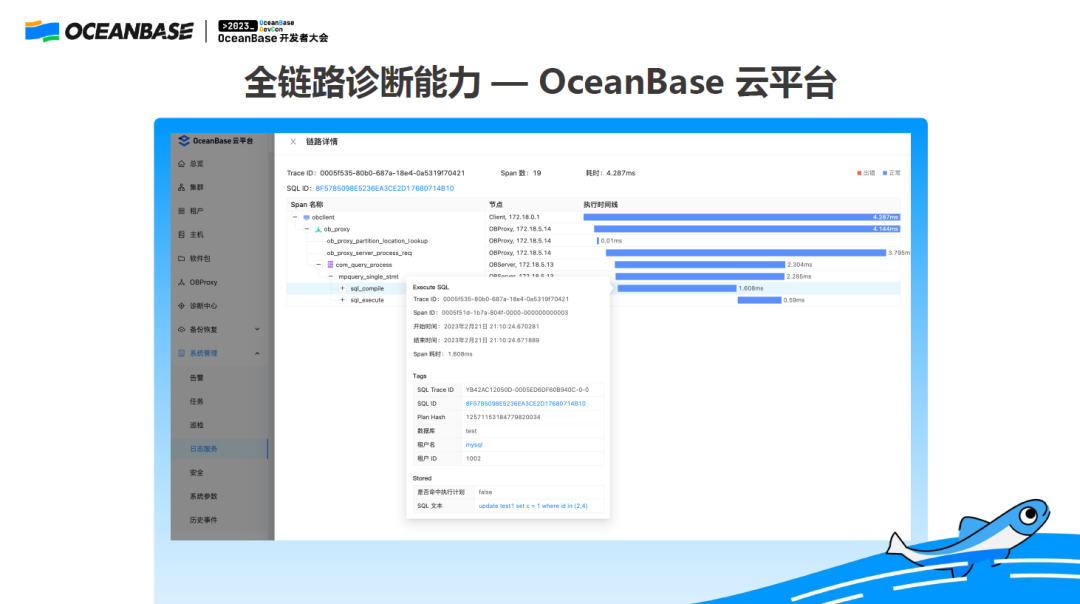
1. 全链路诊断能力—OCP 云平台
在 OCP 云平台上,对一个有问题的 SQL,我们会直接拿到一个报告,在右侧是一个类似于瀑布一样的时间轴,从上至下,时间是一步步分解下来的,通过比较长短,就可以清晰地看到问题在哪一步。
OCP(OceanBase Control Platform),是一款为 OceanBase 数据库集群量身打造的企业级管理平台,兼容 OceanBase 所有主流版本。OCP 提供对 OceanBase 集群的图形化管理能力,包括数据库组件及相关资源的全生命周期管理、监控告警、性能诊断、故障恢复、备份恢复等,旨在协助客户更加高效地管理 OceanBase 数据库,降低企业的IT运维成本和用户的学习成本。
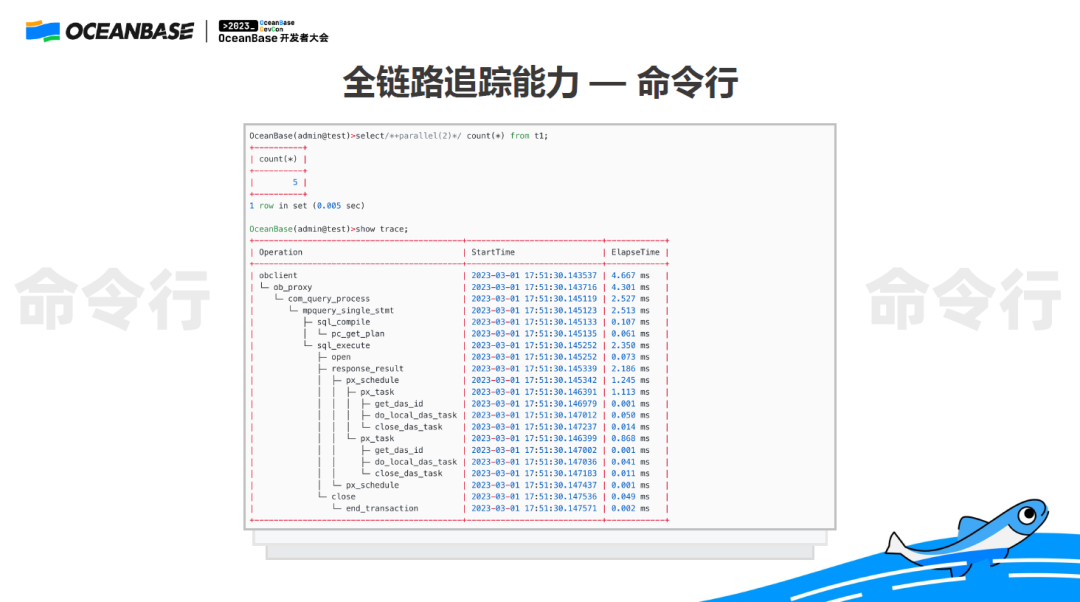
2. 全链路追踪能力—命令行
在命令行上也有类似的追踪功能,执行一条 SQL 后,我们只需要执行一条简单的 show trace命令,它就可以告诉我们在客户端、Proxy,以及在 OBServer 内部,到底哪一步耗时最多。
举个例子,我们指定主键在 OceanBase 内部查一行数据,一般只需要 1 到 2 毫秒,但这个 SQL 花了 62 毫秒,怎么回事?
打开全链路诊断功能,再执行一次这个 SQL,用户侧体感的时间是34毫秒,但在 OBServer 内部耗的时间只有 1.7 毫秒,1.7 毫秒是符合我们日常经验的,那说明这个锅是谁的?从图上看,还真是网络的锅,Proxy 到 OBServer 之间延迟非常大。
3. 如何了解一条 SQL 在 OBServer 内部慢在哪里?
在实际工作中,Proxy 是无状态的,一般不会出现问题,相比较而言,OBServer 发生抖动的概率大得多。
如果一条 SQL 在 OBServer 内部慢的话,怎么诊断?
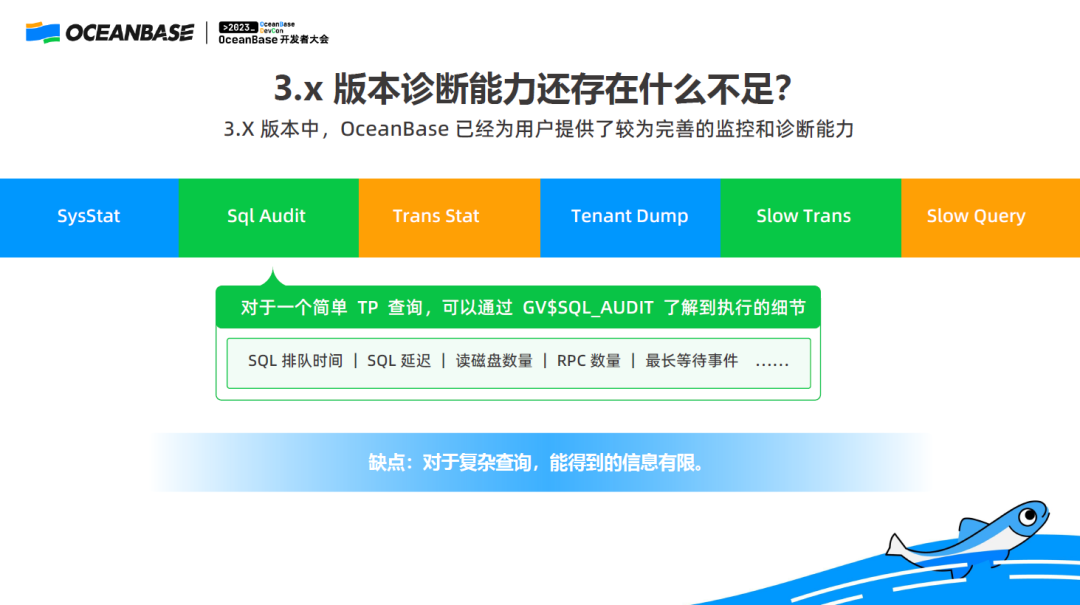
在 4.0 之前的版本,已经提供了很多诊断功能,来帮助我们快速定位一条 SQL 慢在哪里,比如 SQL Audit,可以看到 SQL 的排队时间,读磁盘次数,网络访问次数等细节。但它有个缺陷,就是当 SQL 变得很复杂时,得到的信息就不够了。SQL Audit 可以从宏观上拿到一些信息,但是再深入到算子层面就不行。
为了解决这个问题,就引出我今天要讲的第二个特性:SQL Plan Monitor,它是复杂查询性能诊断利器。
02.
SQL Plan Monitor:复杂查询性能诊断利器
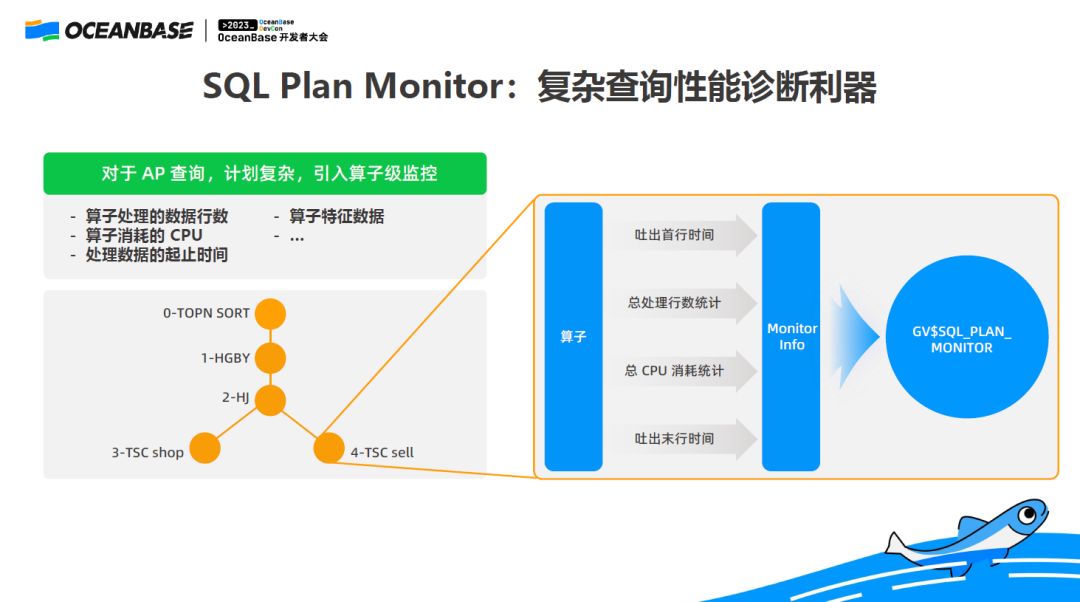
为了 PPT 放得下,举个简单的例子(如上图):这样的一个计划,SQL Plan Monitor 会把它处理了多少行,消耗了多少 CPU,什么时候开始和结束对外输出数据,以及每个算子自身的特征,都记录下来。记录下来之后,把数据放到 GV$SQL_PLAN_MONITOR 视图里,暴露给用户,让用户去查询。
再举个例子,看看 SQL Plan Monitor 是怎么查询的。
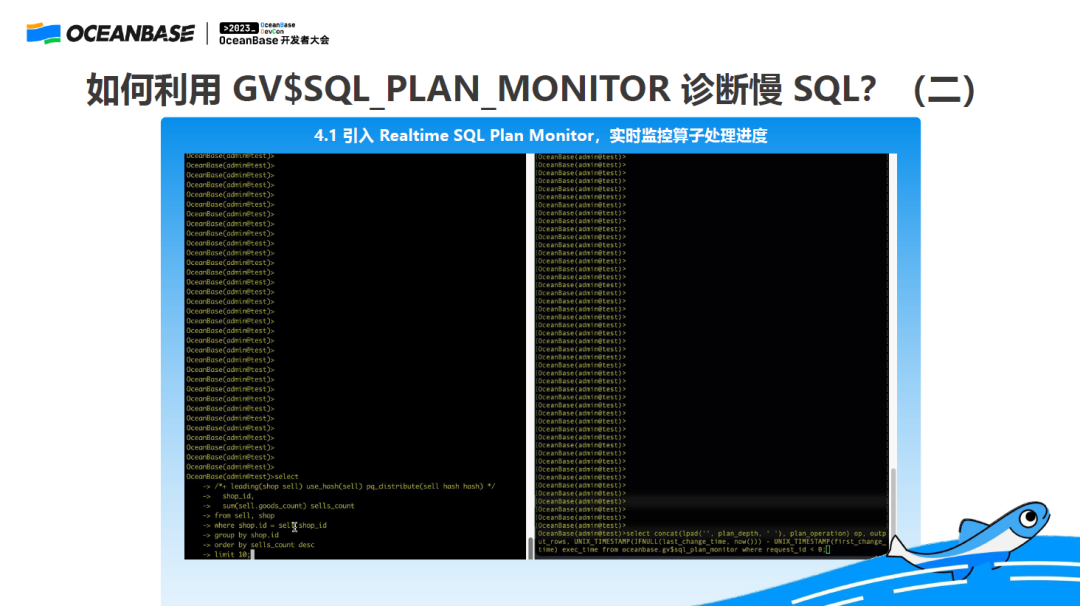
1. SQL Plan Monitor 诊断慢 SQL
如上图,一个电商平台,查询销量 TOP10 的商家,执行时间比较长,左边开始执行,右边就能通过查视图,看到它在不断往外吐行,并且每个算子的状态是不断变化的,可以实时查看。比如,一个 DDL 最长执行,可能几个小时甚至几天,我在执行过程中就想知道执行到哪一步了,虽然 DDL 本身也提供了一些诊断功能,但也是比较宏观的,如果想知道更多具体细节,就可以通过这个去查看。
2. SQL Plan Monitor 可视化
执行完之后,我们还有一些工具可以把 GV$SQL_PLAN_MONITOR 里的数据做可视化。通过可视化,更直观地看到整个 SQL 的内部结构。这里特别值得说的,有三部分:
DB TIME
如上图,绿色部分是这个算子消耗了多少 CPU,红色部分是它的 IO 等待、锁等待等消耗的时间,如果一个 query 的红色部分特别长,一般来说就可能有点问题了,需要关注一下。
执行吐行时间线
起点是吐第一行的时间,终点是吐最后一行的时间,通过时间线的关系可以看到算子吐行先后,以及它们之间的逻辑关系,直观地看到瓶颈是这个 group_by 算子。
并行查询
如果想做进一步优化,通过已有的知识,我们知道它是一个串行的 SQL,只需要用并行查询功能来加速就好。
并行执行之后,我们也拉了一个图(如上),延迟 从 11s 直接降到了 4.6s,执行性能得到显著提升。
值得一提的是,从图中可以看到,数据划分也很均匀。比如 hash join 这两行(绿色部分),吐行开始时间和结束时间几乎是同时的,不存在有人闲着有人很忙,说明比较均匀。我们在处理一些复杂查询的时候,通过拉出这样一个图,可以看出数据内部是不是有倾斜,如果有,会指导我们做对应的优化。
最后,再演
示一下加并行的实际效果,这就是刚才执行的 11s 的 SQL,通过分析,给它加了一个并行 HINT,让 SQL 开启并行执行,极大地加快 SQL 的执行性能,4.62s 就执行完了。
03.
总结
我的分享主要就是这些,希望给大家留下两个印象:
第一,OceanBase 4.0 里有一个“甩锅”的好东西,全链路追踪。
第二,如果大家在处理复杂查询,觉得性能不符合预期时,可以使用 SQL Plan Monitor 来帮助分析 SQL 内部到底发生了什么事情,并且指导我们做优化。
开发者大会演讲实录合集
左右滑动图片查看更多
点击👆查看
左右滑动图片查看更多
点击👆查看
左右滑动图片查看更多
点击👆查看
左右滑动图片查看更多
点击👆查看
下期,山楂丸将会为大家带来
「
产品技术专场
」
,OceanBase 技术部高级专家朱涛的分享:
《从 TP 到 AP : OceanBase SQL 引擎的探索和实践》
欢迎感兴趣的朋友,持续关注~
oceanbase
sql优化
文章转载自
OceanBase数据库星球
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨