





上期分享👉《万字长文!看北大学霸如何破解难题,获得数据库大赛季军!》
本期邀请来自电子科技大学的亚军团队 0xc0 的队长高弘毅,为大家分享决赛多线程和
Major SSTable 生成实践,欢迎分享给感兴趣的朋友,共同学习成长。
以下正文共6078字,阅读大约需要15分钟,建议收藏

OceanBase 决赛之多线程

0xc0团队-凌健、张钦栋、高弘毅(从左至右)
01.

02.
1. 造轮子
class ThreadPool : noncopyable{public:typedef std::function<void()> Task;explicit ThreadPool(const std::string &nameArg = std::string("ThreadPool"));~ThreadPool();void set_max_queue_size(int maxSize) { max_queue_size_ = maxSize; }int start(int num_threads);void stop();int run(Task f);const std::string &name() const { return name_; }size_t queue_size() const;private:...};
使用一个队列来保存 Tasks,每个线程空闲之后从队列中取 Task,通过锁保证线程安全的问题。
OB_INVALID_TENANT_ID。
allocator_.set_tenant_id(MTL_ID());
这个就是设置当前的租户 id,而我们自己启动的线程在通过MTL_ID()
时由于没有租户上下文,导致获取到了OB_INVALID_TENANT_ID
,从而导致申请内存失败。
2. OB ThreadPool
// IRunWrapper 用于创建多租户线程时指定租户上下文// cgroup_ctrl 和IRunWrapper配合使用,实现多租户线程的CPU隔离void set_run_wrapper(IRunWrapper *run_wrapper, ThreadCGroup cgroup = ThreadCGroup::FRONT_CGROUP){run_wrapper_ = run_wrapper;cgroup_ = cgroup;}
class OxcoThreadPool : public share::ObThreadPool{static const int64_t QUEUE_WAIT_TIME = 100 * 1000;public:OxcoThreadPool();virtual ~OxcoThreadPool();int init(const int64_t thread_num, const int64_t task_num_limit, const char *name = "unknow"); 初始化void destroy(); 析构int push(void *task); 添加任务int64_t get_queue_num() const { return queue_.size(); }private:void handle(void *task); 处理任务void handle_drop(void *task) { handle(task); }protected:void run1() override; 启动线程池private:const char *name_;bool is_inited_;common::ObLightyQueue queue_;int64_t total_thread_num_;int64_t active_thread_num_;};
这里我们使用了 OceanBase 库中提供的ObLightyQueue
来维护线程队列,这是一个线程安全的队列,不用自己额外使用锁去维护。由于这个队列并不是模板类,因此它是使用 void 指针来存放队列元素,其定义为:
class ObLightyQueue{public:...int push(void* p);int pop(void*& p, int64_t timeout = 0);private:...void** data_;};
在使用时需要将任务转换为void*指针。
int OxcoThreadPool::init(const int64_t thread_num, const int64_t task_num_limit, const char *name){ int ret = OB_SUCCESS; ... is_inited_ = true; lib::ThreadPool::set_run_wrapper(MTL_CTX()); 设置租户上下文 ... return ret;}
初始化完成后,只需要将任务 task 添加进线程池就可以使用。
这个问题也是我们在比赛初期遇到的比较大的困难。后来官方也在第一次答疑中说明了这个问题,并直接给出了用法,但是我们能够在答疑前通过自己定位到问题所在,并通过浏览 OceanBase 源码自己解决问题,还是有很大的成就感。这个过程也锻炼了自己 Debug 的能力,拓展了 Debug 的方法,也锻炼了在大型项目中浏览代码并解决问题的能力。
03.
1. 整体有序的方法
ObExternalSort这个模块,其定义如下:
template <typename T, typename Compare>class ObExternalSort{public:typedef ObMemorySortRound<T, Compare> MemorySortRound;typedef ObExternalSortRound<T, Compare> ExternalSortRound;ObExternalSort();virtual ~ObExternalSort();int init(const int64_t mem_limit, const int64_t file_buf_size, const int64_t expire_timestamp,const uint64_t tenant_id, Compare *compare);int get_next_item(const T *&item);void clean_up();int add_fragment_iter(ObFragmentIterator<T> *iter);int transfer_final_sorted_fragment_iter(ObExternalSort<T, Compare> &merge_sorter);int get_current_round(ExternalSortRound *&round);TO_STRING_KV(K(is_inited_), K(file_buf_size_), K(buf_mem_limit_), K(expire_timestamp_), K(merge_count_per_round_),KP(tenant_id_), KP(compare_));private:static const int64_t EXTERNAL_SORT_ROUND_CNT = 2;bool is_inited_;int64_t file_buf_size_;int64_t buf_mem_limit_;int64_t expire_timestamp_;int64_t merge_count_per_round_;Compare *compare_;MemorySortRound memory_sort_round_;ExternalSortRound sort_rounds_[EXTERNAL_SORT_ROUND_CNT];ExternalSortRound *curr_round_;ExternalSortRound *next_round_;bool is_empty_;uint64_t tenant_id_;};
ObExternalSort
的实现逻辑是这样的,首先将数据读取到预先分配好的内存中,即memory_sort_round_
,当达到预分配的内存阈值后,会将内存中的数据排序,并写入临时文件中,由ExternalSortRound
进行维护,这样一个临时文件我们将其称为一个fragment
,将文件读完并排序后,我们就得到了多个各自有序的fragment
,并可以通过ExternalSortRound
进行访问。
fragment如何得到或者说访问到整体有序的文件呢?
ObExternalSort的实现,通过它的
get_next_item方法我们可以看到,它将多个
fragment中的第一个元素取出来,组成一个堆,每次从堆顶取元素,取完元素后,再从堆顶元素对应的
fragment中取出一个元素,再对堆进行调整,这样就可以不进行文件合并的同时又获得整体有序的文件。而且可以注意到这些
fragment,可以通过
ObFragmentIterator来进行索引和访问。
ObExternalSort排完序后,将这些
ObFragmentIterator收集到一起,最后通过堆访问就可以实现有序数据的获取。
2. 划分范围的有序文件
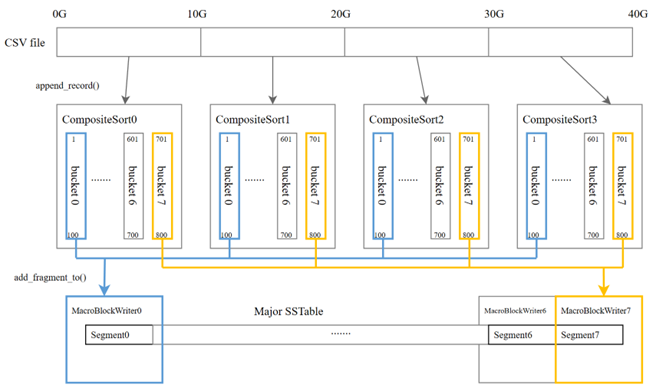
ObExternalSort,每个
ObExternalSort只负责各自范围内的数据,当文件读取完并排序完成后,我们再将每个线程中对应范围的
ObFragmentIterator各自集中到一起,例如将四个线程中负责0-100范围的集中到一起就能够获得0-100整体有序的数据,同样的再将其他三个范围的集中,那我们就能获得四个范围内有序,并且范围间有序的数据,然后四个线程各自取各自范围内的数据写 SSTable 就可以保证写的部分不重叠了。
04.
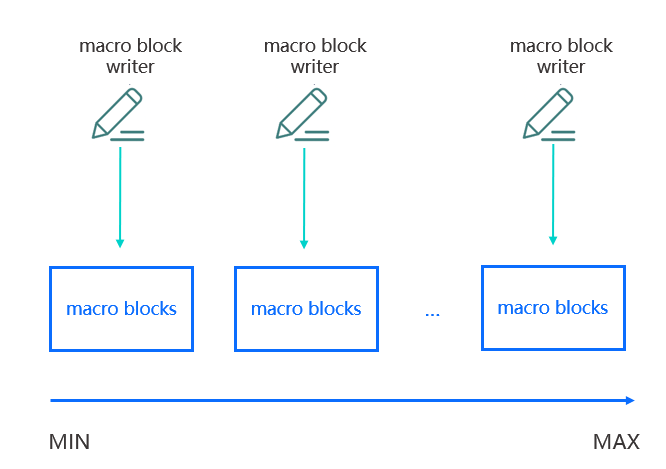
ObSSTableIndexBuilder sstable_index_builder;ObDataStoreDesc data_store_desc;data_store_desc.sstable_index_builder_ = &sstable_index_builder;ObMacroBlockWriter macro_block_writer;ObMacroDataSeq data_seq;// 设置顺序data_seq.set_parallel_degree(parallel_idx);macro_block_writer.open(data_store_desc, data_seq);
其中关键部分就是data_seq.set_parallel_degree(parallel_idx);
,这里给每个 macro_block_writer 设定一个标识,只需要保证当前范围的 parallel_idx 大于前面范围的 parallel_idx 即可。
05.
1. 多线程同步
wait,可以等待所有的线程执行完,但这个方法会有一定的问题,其实现为:
void Thread::wait(){if (pth_ != 0) {pthread_join(pth_, nullptr);destroy_stack();pth_ = 0;pid_ = 0;tid_ = 0;runnable_ = nullptr;}}
std::condition_variable中的wait方法,就能够实现一个简单的线程间同步机制。
2. 线程数的确定
OceanBase 存储引擎初探——
Major SSTable 生成实践
01.
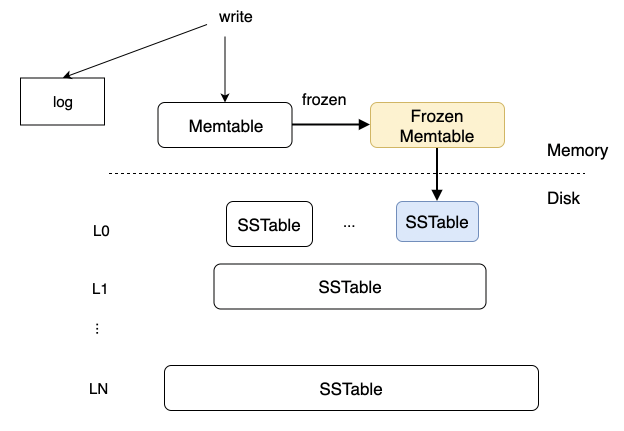
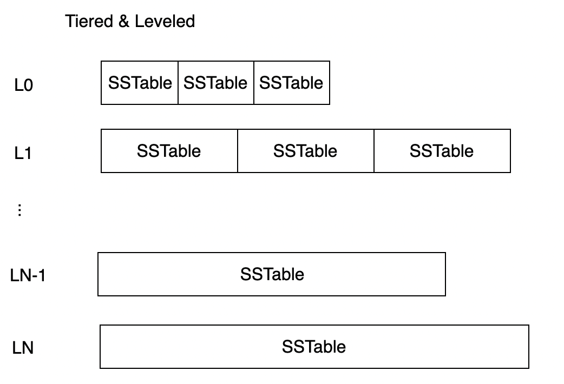
02.
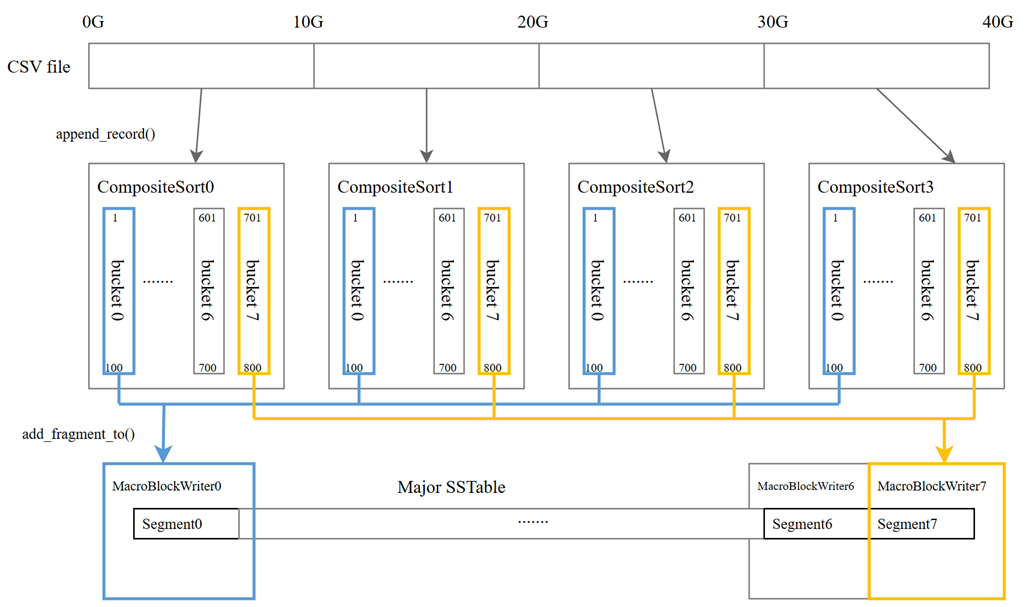
Major SSTable 的磁盘文件格式是什么样的,单文件?多文件? 有没有生成 SSTable 结构的接口,怎么用? 并行分段写入时,如何给每个线程设置初始偏移量?
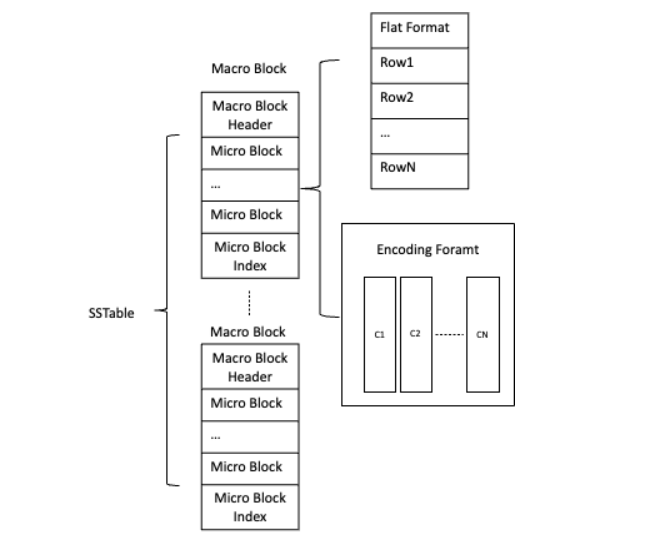
append_row(const ObDatumRow &row)函数将记录按主键顺序交给 MacroBlockWriter 处理、关闭 MacroBlockWriter 与创建 SSTable 的相关元数据。MacroBlockWriter 相关接口分析如下:
class ObMacroBlockWriter {public:// 根据data_store_desc中的table_id、partition_id等信息,打开一个宏块写入器int open(ObDataStoreDesc &data_store_desc, const ObMacroDataSeq &start_seq,ObIMacroBlockFlushCallback *callback = nullptr);// 追加一个宏块,主要会应用在这些场景:// 1. 在合并时,原来的SSTable的某个宏块没有修改,直接复用到当前SSTable中;// 2. 并行合并后,也可以用到这个接口,将多个没有重合数据的宏块进行追加。int append_macro_block(const ObMacroBlockDesc ¯o_desc);// 追加一个微块,和append_macro_block不同的是需要考虑是否存在数据重叠:// 1. 如果数据不重叠,则将micro_block追加到当前宏块中;// 2. 如果数据重叠,则需要构建micro_block的reader,将数据按row写到当前宏块中。int append_micro_block(const ObMicroBlock& micro_block);// 追加一行数据,会调用ObMicroBlockWriter::append_row// 主要逻辑为:// 1. 将行数据写入到微块中,并更新 bloomfilter 和 checksum// 2. 在当前微块写满的情况下:构建当前的微块,并切换微块写入器int append_row(const ObDatumRow &row);// 关闭ObMacroBlockWriter,在关闭之前,会尝试将最后两个宏块合并,节省空间,// 最后将当前最后的宏块flush到磁盘,并等待刷盘成功(wait_io_finish)int close();};
append_row(const ObDatumRow &row)的方式实现多线程写入 SSTable,每一个 MacroBlock 都有一个
int64_t cur_macro_seq_的字段来表示当前宏块在 SSTable 中的编号,它被定义为一个 union:
union{int64_t macro_data_seq_;struct{uint64_t data_seq_ : BIT_DATA_SEQ; // 32bituint64_t parallel_idx_ : BIT_PARALLEL_IDX; // 11bituint64_t block_type_ : BIT_BLOCK_TYPE; // 3bituint64_t merge_type_ : BIT_MERGE_TYPE; // 2bituint64_t reserved_ : BIT_RESERVED; // 15bituint64_t sign_ : BIT_SIGN; // 1bit};};
data_seq.set_parallel_degree(parallel_writer_id);macro_block_writer->open(data_store_desc_, data_seq);


关于本次参赛体验,大家有想什么交流的,欢迎留言,山楂丸去邀请作者,评论区见 ~
 评论区揪2位认真交流的朋友
评论区揪2位认真交流的朋友
(留言获赞最多)
各送大赛定制卫衣1件

PS:点赞截止 2023.4.19 (中午12点)
