上一次我们详细讲解了ChatGPT的全流程注册方法(想体验ChatGPT?请看注册攻略)有不少朋友来咨询最近登录经常报错,具体原因一般都是Cloudflare识别限制区域的问题。可以扫文章底部我的微信。
这篇文章我们来聊聊ChatGPT为何如此强大?它的前世今生是什么?它采取了什么方式达到了如此惊艳世人的效果呢?为何苹果的Siri至今无法生成一篇学术论文,亚马逊的Alexa无法吟出一首莎士比亚十四行诗呢?
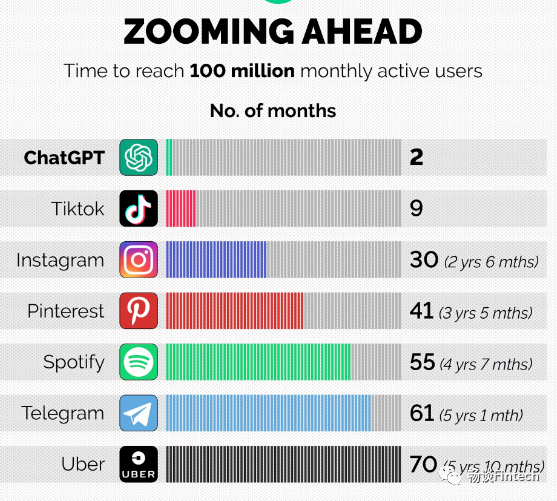
自去年年底12月上线以来,硅谷的初创公司OpenAI推出的ChatGPT,受到热烈的讨论。除了广大用户千奇百怪的问题,引发了社交媒体的大量传播。根据 Similarweb 的数据,今年1 月,平均每天约有 1300 万独立访客使用 ChatGPT,累计用户超1亿!创下了互联网最快破亿应用的记录,超过了之前TikTok 9个月破亿的速度!下图是各互联网产品在全球范围内达到一亿用户数的时间。 ChatGPT既能完成包括写代码,修bug(代码改错),翻译文献,写小说、写商业文案,创作菜谱,做作业,评价作业等一系列常见文字输出型任务,而且在和用户对话时,能记住对话的上下文,反应非常逼真。让人们真实地看到了它为传统互联网带来的改变,ChatGPT自己的回答,已展现出其发展的一种典型路径,即作为人类的陪伴机器人。
自然让人想到一个疑问:ChatGPT是怎么变得这么强的?1、2017年Google大脑Transformer模型- 2017年谷歌大脑团队(Google Brain)在神经信息处理系统大会发表了一篇名为“Attention is all you need”(自我注意力是你所需要的全部)的论文。文中首次提出了基于自我注意力机制(self-attention)的变换器(transformer)模型,并首次将其用于理解人类的语言,即自然语言处理。
- 最初的Transformer模型,一共有6500万个可调参数。谷歌大脑团队使用了多种公开的语言数据集来训练这个最初的Transformer模型。模型在包括翻译准确度、英语成分句法分析等各项评分上都达到了业内第一,成为当时最先进的大型语言模型(Large Language Model, LLM)。
2018年在Transformer模型诞生还不到一年的时候,OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”(用创造型预训练提高模型的语言理解力)推出了具有1.17亿个参数的GPT-1(Generative Pre-training Transformers, 创造型预训练变换器)模型。这是一个用大量数据训练好的基于Transformer结构的模型。最终训练所得的模型在问答、文本相似性评估、语义蕴含判定、以及文本分类这四种语言场景,都取得了比基础Transformer模型更优的结果,成为了新的业内第一。2015年12月,OpenAI公司美国旧金山成立。特斯拉的创始人马斯克也是该公司创始人之一,为公司早期提供了资金支持(后来他从该公司退出,但保留了金主身份,并未撤资)。成立早期,OpenAI是家非营利组织,以研发对人类社会有益、友好的人工智能技术为使命。
2019年,OpenAI改变了其性质,宣布成为营利机构,这个改变与Transformer模型不无相关。
GPT-2具有15亿个参数的模型,该模型架构与GPT-1原理相同。主要区别是:GPT-2的规模更大(10倍)。同时,他们发表了介绍这个模型的论文“Language Models are Unsupervised Multitask Learners” (语言模型是无监督的多任务学习者)。使用了自己收集的以网页文字信息为主的新的数据集。GPT-2模型刷新了大型语言模型在多项语言场景的评分记录。2020年9月,微软公司投资了OpenAI公司,获得了GPT-3模型的独占许可。对GPT-3模型进行了商业化:付费用户可以通过应用程序接口API,使用该模型完成所需语言任务。
5、2022年3月OpenAI InstructGPT模型
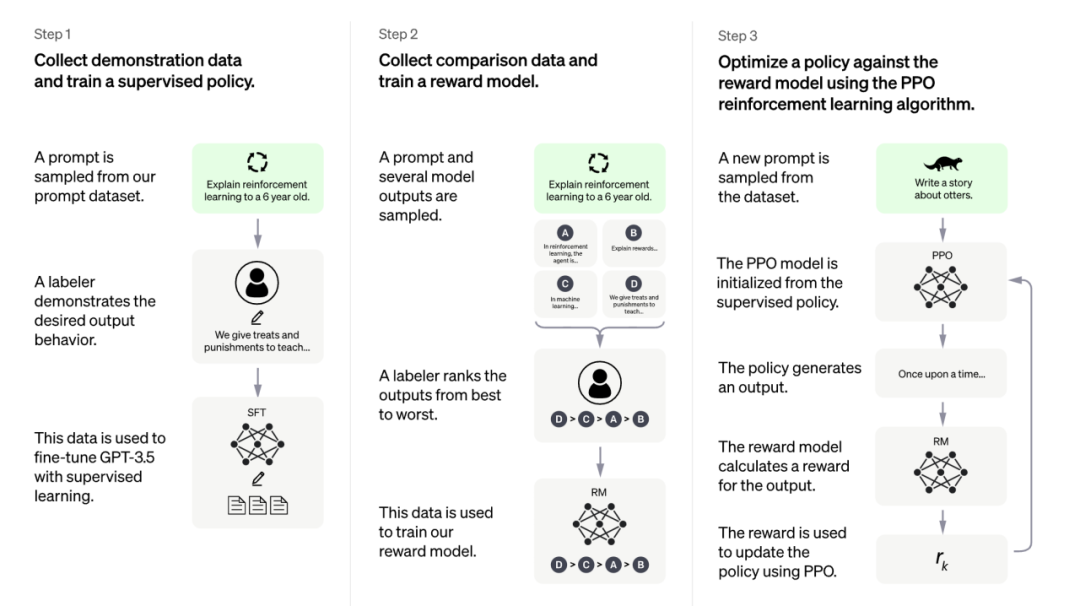
2022年3月OpenAI发表论文“Training language models to follow instructions with human feedback”(结合人类反馈信息来训练语言模型使其能理解指令),并推出了他们基于GPT-3模型并进行了进一步的微调的InstructGPT模型。模型的参数数目为1750亿(与GPT-3模型相同)模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集。
先用这些数据对GPT-3用监督式训练(supervised learning)进行了微调。
收集了微调过的模型生成的答案样本。一般来说,对于每一条提示语,模型可以给出无数个答案,而用户一般只想看到一个答案(这也是符合人类交流的习惯),模型需要对这些答案排序,选出最优。所以,数据标记团队在这一步对所有可能的答案进行人工打分排序,选出最符合人类思考交流习惯的答案。这些人工打分的结果可以进一步建立奖励模型——奖励模型可以自动给语言模型奖励反馈,达到鼓励语言模型给出好的答案、抑制不好的答案的目的,帮助模型自动寻出最优答案。
使用奖励模型和更多的标注过的数据继续优化微调过的语言模型,并且进行迭代。
6、2022年12月OpenAI ChatGPT模型
2022年12月神经信息处理系统大会会议期间,OpenAI公司推出ChatGPT。与InstructGPT模型类似,ChatGPT是OpenAI对GPT-3模型(又称为GPT-3.5)微调后开发出来的对话机器人。由于最大的InstructGPT模型的参数数目为1750亿(与GPT-3模型相同),所以相信ChatGPT参数量也是在这个数量级。但是,根据文献,在对话任务上表现最优的InstructGPT模型的参数数目为15亿,所以ChatGPT的参数量也有可能相当。ChatGPT比GPT-3的更优秀的一点在于,前者在回答时更像是在与你对话,而后者更善于产出长文章,欠缺口语化的表达等。
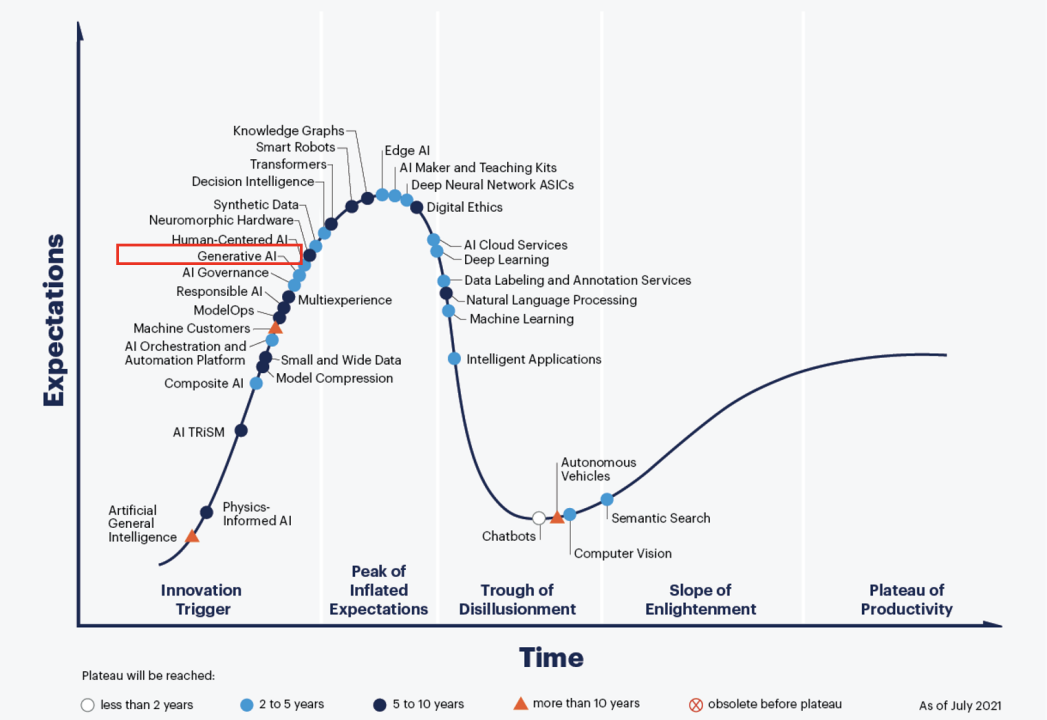
ChatGPT背后的支撑是人工智能大模型技术。ChatGPT是生成式AI的一种形式,Gartner将其作为《2022年度重要战略技术趋势》的第一位。Gartner预测,到2025年,生成式AI将占到所有生成数据的10%,但目前这个比例还不足1%。
当前的人工智能大多是针对特定的场景应用进行训练, 生成的模型难以迁移到其他应用, 属于“ 小模型”的范畴。整个过程不仅需要大量的手工调参, 还需要给机器喂养海量的标注数据,这拉低了人工智能的研发效率, 且成本较高。大模型通常是在无标注的大数据集上, 采用自监督学习的方法进行训练。之后,在其他场景的应用中,开发者只需要对模型进行微调, 或采用少量数据进行二次训练, 就可以满足新应用场景的需要。这意味着,对大模型的改进可以让所有的下游小模型受益, 大幅提升人工智能的适用场景和研发效率, 因此大模型成为业界重点投入的方向,Open AI、谷歌、脸书、微软, 国内的百度、阿里、腾讯、华为和智源研究院等纷纷推出超大模型。特别是OpenAI GPT 3 大模型在翻译、问答、内容生成等领域的不俗表现, 让业界看到了达成通用人工智能的希望。2、不断探索技术创新
Open AI团队在持续研究中,不断探索引入新的技术路线。这次引入的强化学习方法,很好地提升了模型的效果。在研究中,Open AI在模型训练中,引入了人类专家。专家一方面帮助ChatGPT撰写更符合人类习惯的回答,另一方面,也对生成的结果进行排名,通过这样的奖励机制,实现模型的微调优化。
过去十年间,谷歌、Facebook、亚马逊、苹果和微软等硅谷科技巨头纷纷开启AI军备竞赛,先后成立专门的AI实验室,而最终业界公认的做纯AI研究的顶级实验室只有三家:背靠谷歌的DeepMind、背靠微软的OpenAI和背靠Facebook的FAIR。其中,被谷歌收购DeepMind因拥有AlphaGo最为家喻户晓。 截至目前,人工智能还没有找到征服语言领域的暗门,即使是谷歌、苹果这样的顶级科技公司,都面临着相关AI研究成果派不上用场的苦恼。 ChatGPT的问答和多轮对话形式,很好地激发了大众的热情和创造力,大家基于各自感兴趣的话题自由发挥,或幽默搞笑、或严肃认真,在朋友圈和媒体上屡屡刷屏。包括之前GPT3的推出,他写新闻、作诗、翻译、编代码等能力,也是在社会上产生了热议和讨论。这种很好地与公众互动的项目设计策略,也很值得我们学习。包括之前AlphaGo的围棋大战、Deepmind破解蛋白质折叠结构难题,都是很好的议题任务设置。 如果用一句话来说明ChatGPT是什么,可以将它理解为由AI驱动的聊天机器人。外界往往认为语言学领域是人工智能派上用场的绝佳地带,而事实并非如此。关注度短短几天扩大到燎原之势,正是因为人们从中看到了人工智能和语言本体之间的真正接口,ChatGPT会成为未来人机交互的一个新入口!这种方式很可能改变现有APP的交互方式,以更为自然的对话方式,让用户来使用软件和调用技能。例如,未来在文档编辑软件中,人们可以通过描述需求,让软件直接生成文字内容,或者生成一个图形,甚至直接进行修图等工作。在编程方面,ChatGPT这种即时编程的方式,将改变传统的工作方式和应用交互规则,推动产业进入软件3.0的新阶段。
ChatGPT是典型的AIGC大模型,目前国内外在文本、代码、图像、视频、3D等领域都涌现出相应的生成模型。 当前,ChatGPT一个有力的竞争者是Claude,他是Anthropic近期推出的生成式Al模型。Anthropic由几位前 OpenAl的研究员在2021年创立,包括OpenAl前研究副总裁Dario Amodei、GPT-3论文一作Tom Brown等人。据《金融时报》报道,2022 年底,Google向这家初创公司投资了约 3 亿美元。相比ChatGPT,Anthropic 在其网站上更强调其构建“可靠、可解释和可操纵的人工智能系统”的工作。 腾讯的混元大模型,集CV(计算机视觉)、NLP(自然语言理解)、多模态理解能力于一体,先后在MSR-VTT,MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯。2022年5月,腾讯“混元”AI大模型在CLUE(中文语言理解评测集合)总排行榜、阅读理解、大规模知识图谱三个榜单同时登顶,一举打破三项纪录。12月,混元推出国内首个低成本、可落地的NLP万亿大模型,并再次登顶自然语言理解任务榜单CLUE。混元用千亿模型热启动,最快仅用256卡在一天内即可完成万亿参数大模型HunYuan-NLP 1T的训练,整体训练成本仅为直接冷启动训练万亿模型的1/8。当前的人工智能大多是针对特定的场景应用
1、https://platform.openai.com/docs/introduction2、https://chat.openai.com/chat3、https://franxyao.github.io/blog.html4、https://arxiv.org/abs/1706.03762