




一、概述
排序归并连接是嵌套循环连接的变体。
如果参与连接的两个数据集尚未排序,则数据库会对它们进行排序。这些是SORT JOIN操作。对于第一个数据集中的每一行,基于前一次迭代产生匹配的位置开始,数据库会探测第二个数据集以寻找匹配的行并连接它们。这是MERGE JOIN操作。
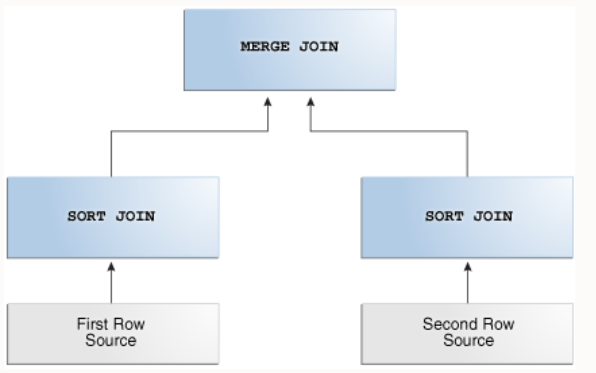
二、优化器在什么场景下会考虑使用排序归并连接?
hash连接需要一个hash表和对这个表的一次探测,而排序合并连接需要两次排序。
当满足以下任何条件时,优化器可能会选择排序合并连接而不是hash连接来连接大量数据:
-
两个表之间的连接条件不是等值连接,也就是说,使用诸如<、<=、>或>=之类的不等式条件。
与排序合并相比,hash连接需要一个等式条件。 -
由于其他操作需要排序,优化器发现使用排序归并更便宜。
如果存在索引,则数据库可以避免对第一个数据集进行排序。但是,无论索引存在与否,数据库总是会对第二个数据集进行排序。
与嵌套循环连接相比,排序归并具有与hash连接相同的优势:数据库在PGA中访问行,而不是在SGA中,通过避免在数据库缓冲缓存中重复的上锁和读取块的必要性来减少逻辑I/O。一般来说,hash连接比排序合并连接执行得更好,因为排序是昂贵的。然而,与hash连接相比,排序合并连接提供了以下优点:
- 在初始排序之后,将优化归并阶段,从而更快地生成输出行。
- 当哈希表不能完全装入内存时,排序归并可能比哈希连接性价比更高。
内存不足的哈希连接需要将哈希表和其他数据集都复制到磁盘。在这种情况下,数据库可能需要多次从磁盘中读取数据。在排序合并中,如果内存不能容纳这两个数据集,那么数据库将它们都写入磁盘,但每个数据集的读取次数不超过一次。
三、排序归并连接如何运作?
与嵌套循环连接一样,排序归并连接读取两个数据集,但在它们尚未排序时对它们进行排序。
对于第一个数据集中的每一行,数据库会在第二个数据集中找到一个起始行,然后读取第二个数据集,直到找到一个不匹配的行。在伪代码中,排序归并的高级算法可能如下所示:
READ data_set_1 SORT BY JOIN KEY TO temp_ds1
READ data_set_2 SORT BY JOIN KEY TO temp_ds2
READ ds1_row FROM temp_ds1
READ ds2_row FROM temp_ds2
WHILE NOT eof ON temp_ds1,temp_ds2
LOOP
IF ( temp_ds1.key = temp_ds2.key ) {
OUTPUT JOIN ds1_row,ds2_row
READ ds2_row FROM temp_ds2
}
ELSIF ( temp_ds1.key <= temp_ds2.key ) READ ds1_row FROM temp_ds1
ELSIF ( temp_ds1.key >= temp_ds2.key ) READ ds2_row FROM temp_ds2
END LOOP
例如,下表显示了两个数据集中的排序值:temp_ds1和temp_ds2。
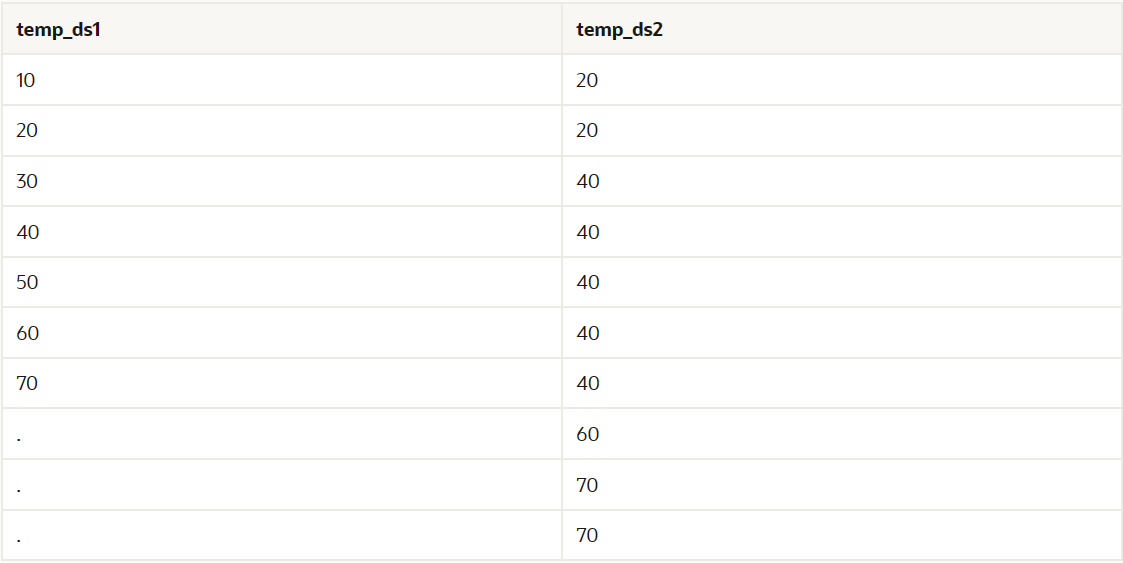
如下表所示,数据库首先从temp_ds1中读取10,然后从temp_ds2中读取第一个值。因为temp_ds2中的20大于temp_ds1中的10,所以数据库停止读取temp_ds2。
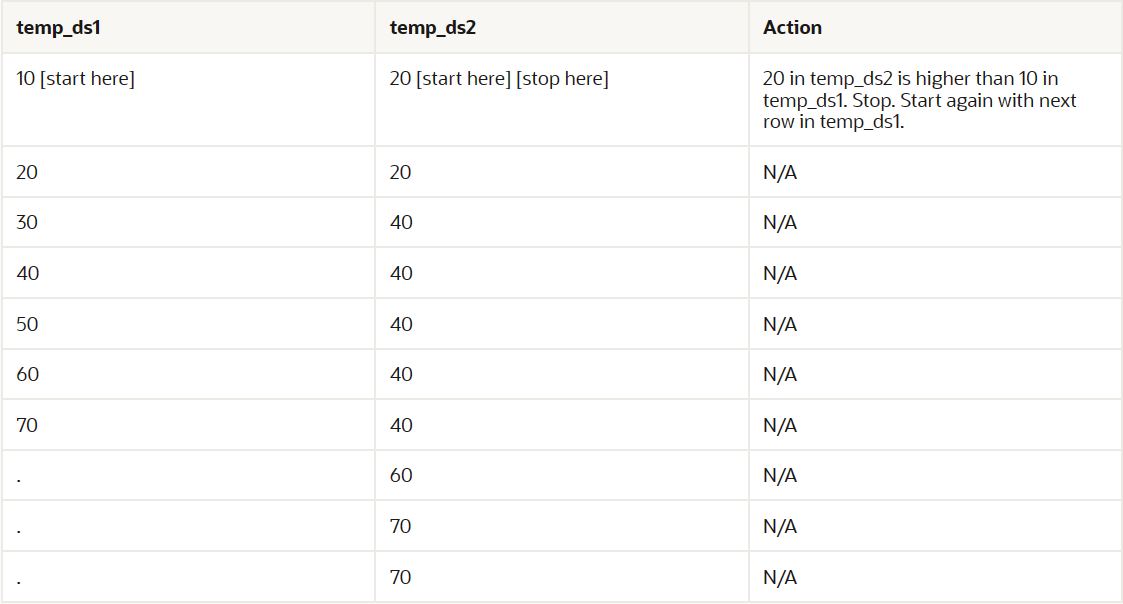
数据库继续读取temp_ds1中的下一个值(20)。数据库继续处理temp_ds2,如下表所示。
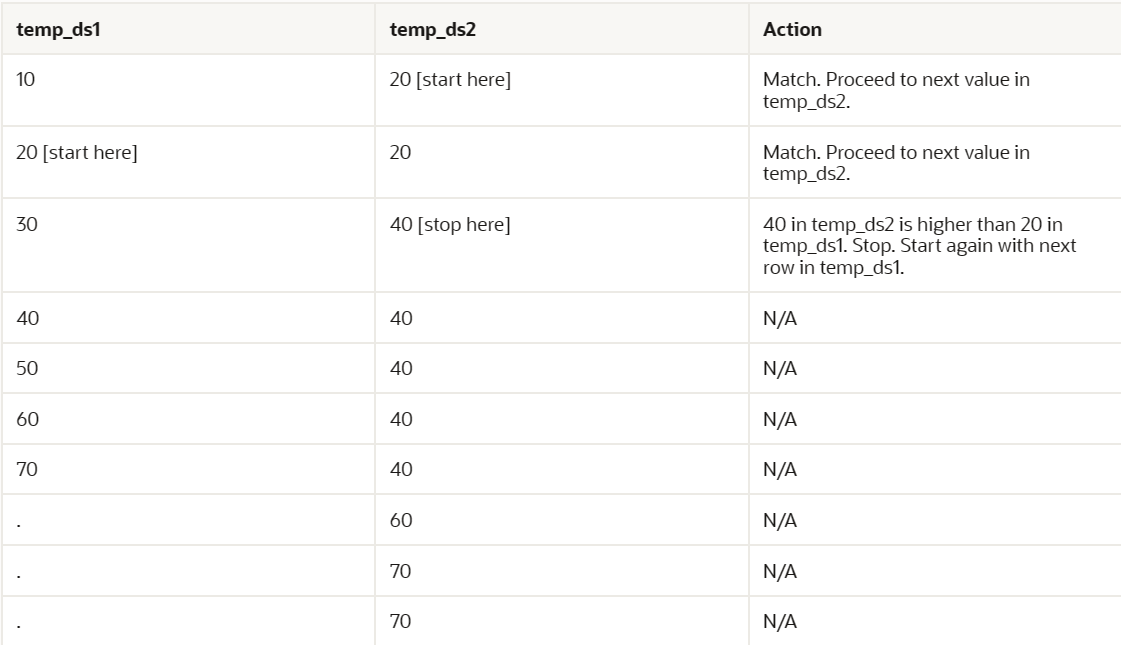
数据库继续读取temp_ds1中的下一个值(30)。数据库从上一次匹配的数字(20)开始,然后通过temp_ds2查找匹配,如下表所示。
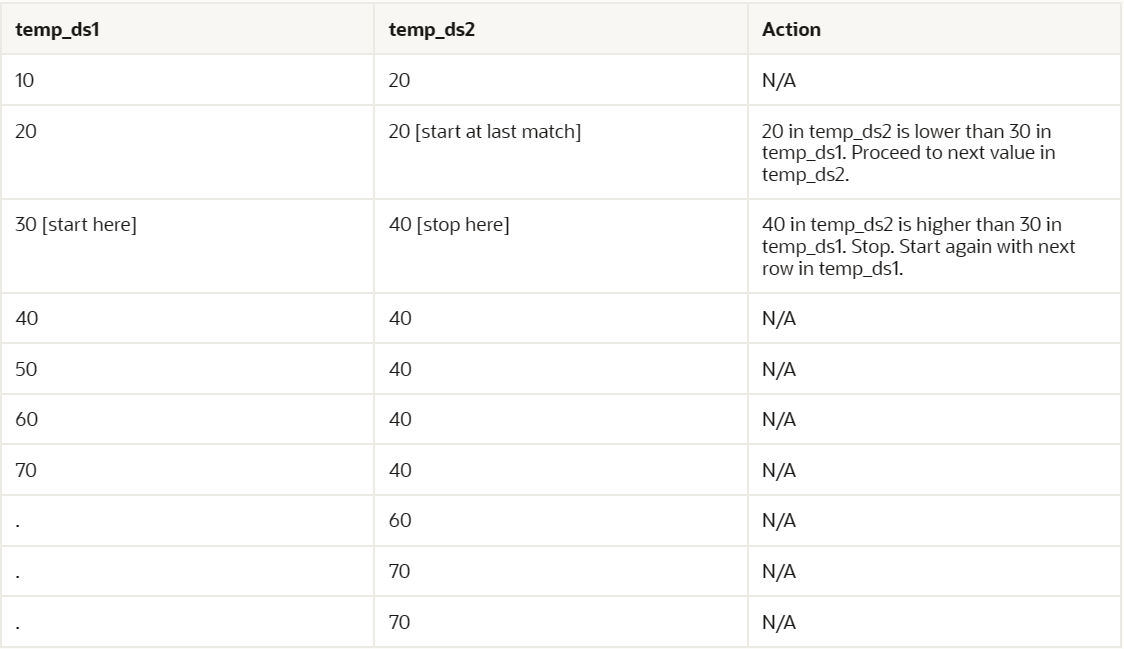
数据库继续读取temp_ds1中的下一个值(即40)。如下表所示,数据库从temp_ds2中最后一次匹配的数字(即20)开始,然后在temp_ds2中继续查找匹配。

数据库以这种方式继续,直到temp_ds2中的最后一个值(70)被匹配。这个场景演示了数据库在读取temp_ds1时,不需要读取temp_ds2中的每一行。与嵌套循环连接相比,这是一个优点。
1、使用索引的排序归并连接
下面的查询在department_id列上连接employees和departments表,在列department_id上对行进行排序:
SELECT e.employee_id, e.last_name, e.first_name, e.department_id,
d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
查询DBMS_XPLAN.DISPLAY_CURSOR显示计划使用了排序归并连接:
---------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost (%CPU)|Time|
---------------------------------------------------------------------------
| 0| SELECT STATEMENT | | | |5(100)| |
| 1| MERGE JOIN | |106 |4028 |5 (20)|00:00:01|
| 2| TABLE ACCESS BY INDEX ROWID|DEPARTMENTS | 27 | 432 |2 (0)|00:00:01|
| 3| INDEX FULL SCAN |DEPT_ID_PK | 27 | |1 (0)|00:00:01|
|*4| SORT JOIN | |107 |2354 |3 (34)|00:00:01|
| 5| TABLE ACCESS FULL |EMPLOYEES |107 |2354 |2 (0)|00:00:01|
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
这两个数据集是departments表和employees表。因为索引按department_id对departments表排序,所以数据库可以读取该索引并避免排序(步骤3)。数据库只需要对employees表进行排序(步骤4),这是cpu最密集的操作。
2、没有索引的归并排序连接
在department_id列上连接employees和departments表,在列department_id上对行进行排序。在这个例子中,你可以指定NO_INDEX和USE_MERGE来强制优化器选择排序归并:
SELECT /*+ USE_MERGE(d e) NO_INDEX(d) */ e.employee_id, e.last_name, e.first_name,
e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id
ORDER BY department_id;
查询DBMS_XPLAN.DISPLAY_CURSOR显示计划使用了排序归并连接:
---------------------------------------------------------------------------
| Id| Operation | Name | Rows| Bytes|Cost (%CPU)|Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
| 1 | MERGE JOIN | | 106 | 9540 | 6 (34)| 00:00:01|
| 2 | SORT JOIN | | 27 | 567 | 3 (34)| 00:00:01|
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 567 | 2 (0)| 00:00:01|
|*4 | SORT JOIN | | 107 | 7383 | 3 (34)| 00:00:01|
| 5 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7383 | 2 (0)| 00:00:01|
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
因为departments.department_id索引被忽略,优化器执行排序,这将使步骤2和步骤3的总成本增加67%(从3到5:(5-3)/3)。
更多详细信息请参考:https://docs.oracle.com/en/database/oracle/oracle-database/19/tgsql/joins.html
