




旁路导入初体验
一:旁路导入概念
首先我们先引用OB官方文档的一段话,“OceanBase 数据库支持旁路导入的方式向数据库插入数据,即 OceanBase 数据库支持向 data 文件中直接写入数据的功能。旁路导入可以绕过 SQL 层的接口,直接在 data 文件中直接分配空间并插入数据,从而提高数据导入的效率”。
通过这段描述,让我有种眼前一亮的感觉,因为在OB的运维过程中,我们经常面临的一个问题就是数据的导入导出,针对小表可能大家用一些图形化工具或者obloader感觉还是很不错的,但是如果数据量大的话,性能可能就无法满足要求,同时也担心出现memstore被打爆的风险。
根据OB官方文档介绍,OB支持两种方式的旁路导入,一种是我们以前经常在mysql中使用的load data方式,另外一种是在oracle中经常使用的insert /*+append parallel*/方式。
二:旁路导入测试
测试环境:本次测试采用的是三台虚拟机搭建的OB 4.1社区版。
2.1: LOAD DATA方式
2.1.1:修改变量secure_file_priv
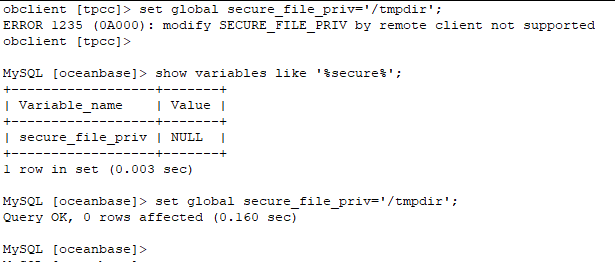
这个与mysql是类似的,要想使用load data方式,必须先要修改secure_file_priv变量,默认为空。
使用限制:此变量必须在observer上修改,不允许从客户端远程修改。

2.1.2:测试数据准备
--新建测试表
create table test(id integer,name varchar(20),primary key(id));
create table t(id integer,name varchar(20),primary key(id));
--准备测试文件,将如下SQL放到ab.csv文件里
select ROW_NUMBER()over(),ROW_NUMBER()over() from `gv$plan_cache_plan_stat` limit 10000;
2.1.3:导入测试
使用限制:
1:文件必须放在observer上
2:文件放的位置必须与secure_file_priv变量对应的值一样
--数据文件放到/tmp目录下导入,报错
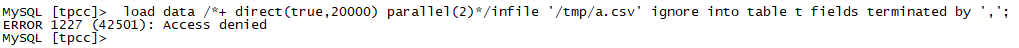
--文件放到/tmpdir目录下导入,成功

通过上面简单的测试,我们发现成功了,测试还是比较简单的。突然想到,如果我把文件的全路径去掉,它应该会去哪里找文件哪?
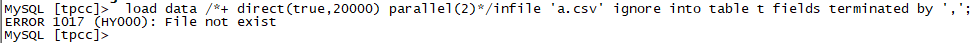
通过报错可以看出与前面不一样,说明他在默认路径没找到文件。将a.csv文件拷贝到ob的主目录(/data/myob4/oceanbase),然后再导入,就报错提示没权限。
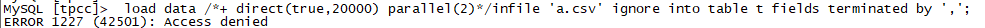
将环境变量改为/data/myob4/oceanbase,再导入。成功导入。

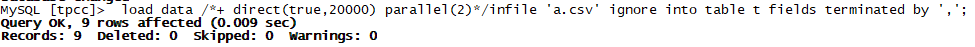
上面我们成功导入少数据量,现在我们导入10000条看下效率如何。
--导入10000条数据,速度还是非常可观的。
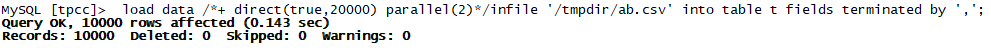
以上的场景都是数据导入成功的验证,如果数据有问题会有什么情况哪?
--重复数据导入,直接报错
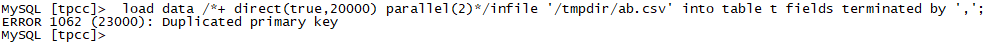
出错后,会在oceanbase的日志目录生成一个obloaddata.log.*的文件,内容大致如下:
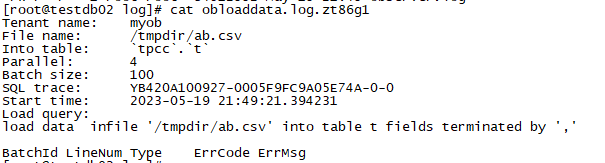
从日志中可以看到batch size是100,说明他是按照批次来“提交”数据的,本次测试我删除1230条,然后执行导入,发现它只导入进去了1200条,有30条是在一个批次内的第31条出现了重复数据,全部就“回滚”了。
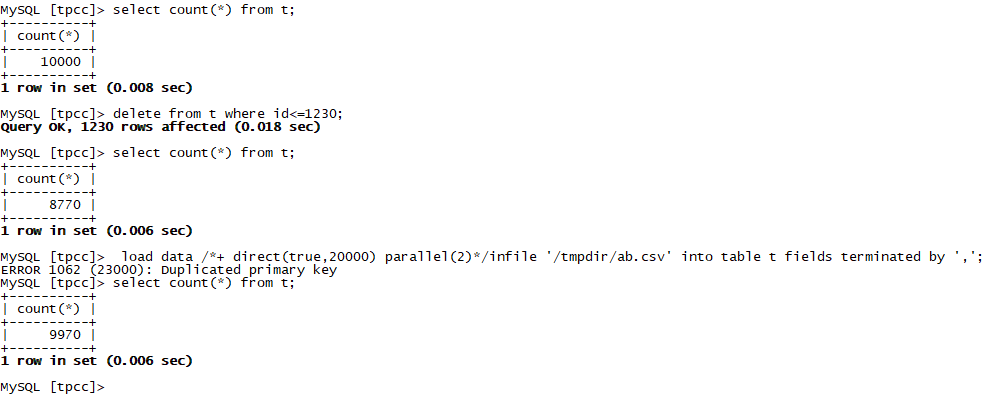
有的时候,我们在导入数据的时候经常要忽略掉前多少条那种,这个时候就是ignore number rows的用武之地了。
--忽略1000条导入

--我们查看数据,是文件的前1000条没有导入哦。
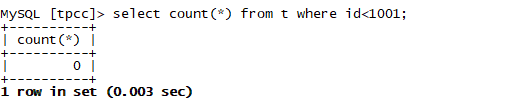
如果我们在导入的时候,表里有数据怎么办哪?我们想清空表在导入可以吗?答案是可以的。
--清空导入:

2.2: INSERT /*+append */方式
INSERT INTO SELECT 语句通过 Hint 使用 append 加上 enable_parallel_dml 来走旁路导入。
使用限制:
1:只支持 PDML,非 PDML 不能用旁路导入。
2:导入的过程中会先加表锁
2.2.1:默认的insert into
通过执行计划,我们可以看出默认insert into select方式是没有使用旁路导入的。主要是看最后一行(是否包含:Direct-mode)
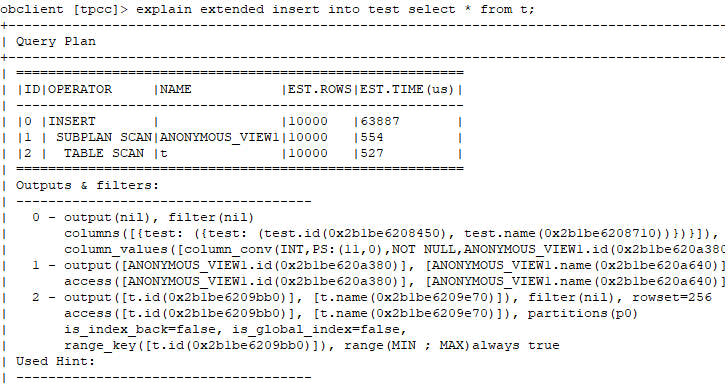
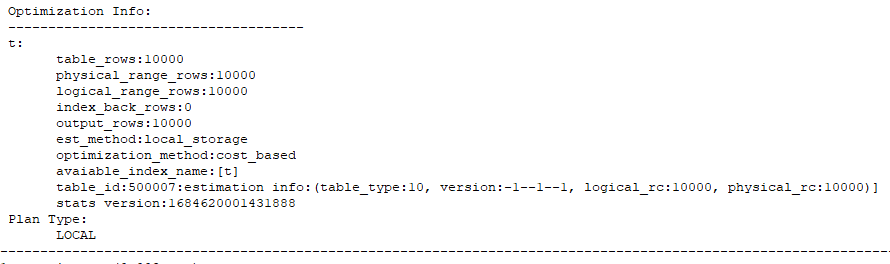
2.2.2:旁路导入
通过查看执行计划,可以看出使用了DIRECT方式。
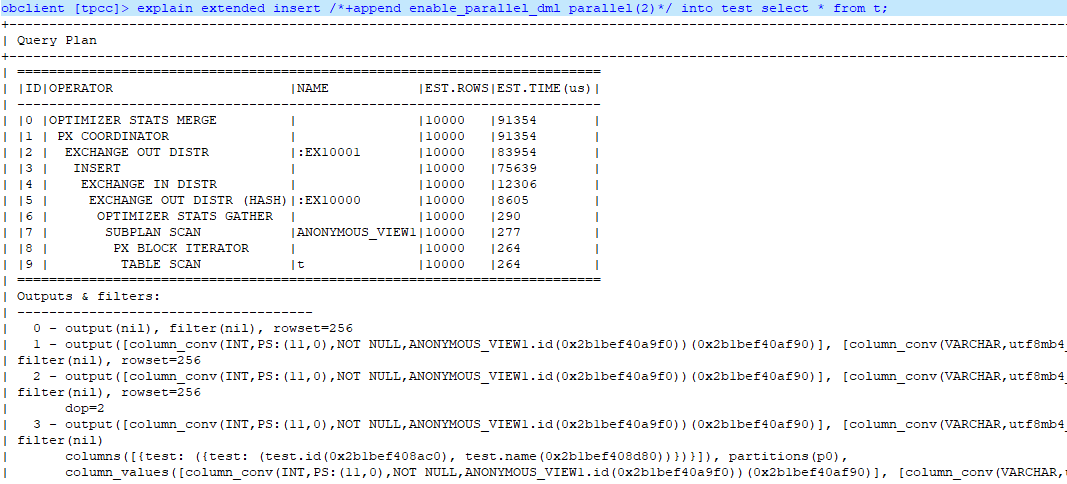
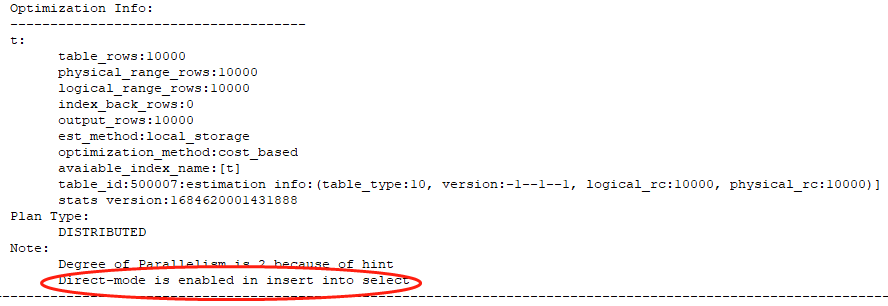
--如果去掉parallel会怎么样?
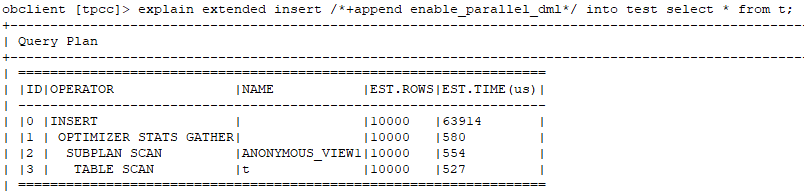
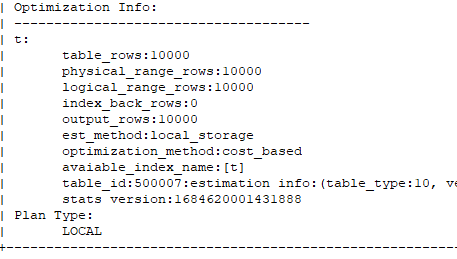
--如果去掉enable parallel dml会怎么样?
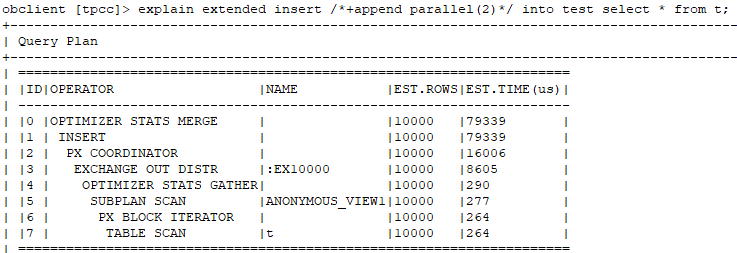
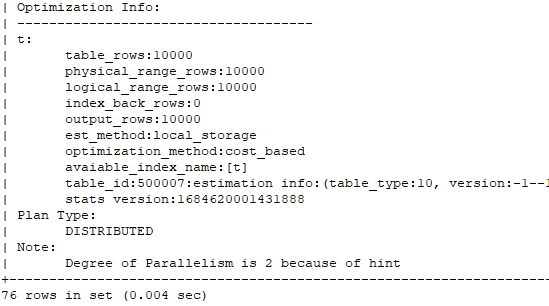
通过上述测试,可以发现append,enable_parallel_dml,parallel缺一不可啊。
三:总结
旁路导入这个工具还是非常不错的,也为OceanBase的导入导出增加了一个利器。整体使用方法比较简单
旁路导入可能会在大的数据量情况下性能会比较显著吧(当前没有测试数据量过大的场景),在数据量小的情况,有时可能还不如传统方法快。比如此次测试的时候,在insert /*+append*/ into场景下导入数据,导入10000条需要花3秒多的时间,而传统的insert into方式只需要0.03秒。可能insert /*+append*/into结合分区表会有更好的效果。
