




作者 阿里云数据库专家 ,爱好广泛,机车爱好者 ,摄影高手
概述
数据同步分为多个同步阶段:结构对象同步、全量数据同步和增量数据同步。对于异构数据库之间的同步,需要从源库读取结构定义语法,根据目标数据库的语法定义,将语法重新组装成目标数据库的语法格式,并导入到目标实例中。
全量数据同步过程持续较久,在这过程中,源数据库不断有业务写入,为保证数据同步的一致性,在全量数据同步之前会启动增量数据拉取模块,增量数据拉取模块会拉取源数据库的增量更新数据,并解析、封装、存储在本地存储中。
当全量数据同步完成后,会启动增量数据回放模块,增量数据回放模块会从增量拉取模块中获取增量数据,经过反解析、过滤、封装后同步到目标实例,从而实现增量数据同步。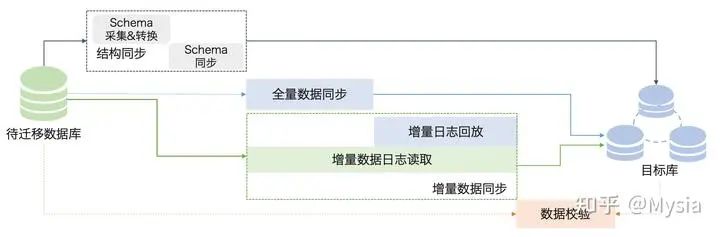
数据同步过程中,最重要的点是保证数据的一致性,保证同步的数据不多、不少、不错。那么,有哪些需要注意的呢?
同步流程需要保证增量同步的起始点在全量开始之前,确保无漏掉的数据。 由于增量回放位点在全量开始之前,必然会有部分重复数据,需要保证多次写入幂等。 每条数据必须具备唯一标识,增量写入遇到主键、唯一约束冲突,忽略掉。 增量阶段需要保证顺序回放。 需要保证中断恢复的场景不丢失变更。
关键点1:数据唯一标识和写入幂等
全量同步并不是某一个瞬间的一致性 snapshot,在全量同步的过程中,源端数据也是持续在变化的,因此这里是不需要任何锁的。但是会出现全量数据查询的数据,在增量阶段拉取到 insert 的情况,这样的话就要保证多次写入的幂等。这样的话,每条数据必须要有唯一标识,这里注意有些数据库上的唯一键并不具备唯一标识的作用,比如说 mysql 上唯一键的值可以为 null,而且多个 null 不是唯一键冲突,但是在数据同步的时候这样是有问题的,重复数据可以 insert 成功,不会报唯一性约束冲突,也就无法做幂等控制。
关键点2:主键/唯一键更新问题
这里举例说明。
假设:有一张表 student,有两列:id primary key,name unique key,初始状态有一条数据为 (1, student2)。事务执行的顺序为:
delete from student where id = 1;
insert into student (1, 'student1');
update student set name = 'student2' where id = 1;
insert into student (2, 'student1’);
实际执行完成之后,数据库里正常的状态是有 (1, student2) (2, student1) 两条数据。
假设此时回放执行:
删除操作成功,执行完数据里还剩 (2, student1)
插入操作由于 student1 唯一键冲突被忽略
更新操作未命中 id = 1 的数据
插入操作由于主键 id = 2 冲突被忽略
执行完,数据库中只有一条 (2, student1)
回放完成之后,实际上丢失了一条数据!
这个问题的解决方案:遇到 update 更新主键或者唯一键的场景转成 delete + insert。
按照这个思路,再次回放执行:
删除操作成功,执行完数据里还剩 (2, student1)
插入操作由于 student1 唯一键冲突被忽略
更新操作由于更新的是唯一键的值,因此转为 delete id = 1 和 insert into student (1, 'student2'),delete 未命中,insert 成功
插入操作由于主键 id=2 冲突被忽略
执行完,数据库中有两条 (1, student2)(2, student1),结果正常。
关键点3:无主键表的同步
如果像Oracle一样,有类似 rowid 的隐藏标识。可以针对源端隐藏的唯一标识,在目标端建一列与之对应,作为唯一键,做幂等控制。
那么,反向同步怎么做?
增量同步阶段也会有重复拉取增量数据的问题
不能用隐藏唯一标识来做,因为源端已有的数据并不带有目标端的唯一标识,无法使用
反向和正向的不同:正向包含全量和增量,全增量有重合,重合部分无法区分 反向只包含增量,只需要保证增量事务只被复制一次即可
如何保证增量事务只被复制一次?标记已写入的事务。
需要源端的每个事务都有都有唯一的事务标识,一般数据库日志都有增量同步时在目标建一张事务表
在增量复制某个事务时,首先检查事务表中是否有该事务的记录
如果没有,说明事务没复制过。复制事务时,同时将事务写入事务表,和复制事务一起提交
如果有,则说明事务之前被复制过,忽略该事务
无主键表、无隐藏的唯一标识是否可以做?答案是可以的,但是有一些限制。
需要保证全增量不重叠
全量期间开启事务,锁表,并记录日志点位 使用 RR 隔离级别 select 全表数据,并释放锁 待全量同步完成后,从之前记录的日志位点精准回放
这么做,有限制条件:
需要短暂锁表 需要保证增量事务有唯一 ID 防止增量阶段的事务回放导致数据不一致 全量如果中断,整个同步流程需要从头开始 全量阶段只能单连接获取数据,效率低 需要精准定位增量位点,部分数据库不支持
关键点4:并行回放增量数据,提高吞吐
源数据库串行产生增量的日志,如果在目标库做串行的回放,会收到单链路吞吐的限制,容易出现同步延迟,需要并行做增量回放来提高吞吐。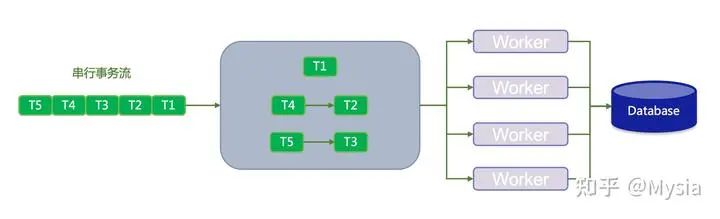
并行回放增量数据,冲突检查是关键。这里有个基本规则:
如果两个事务不会对同一条数据做变更,则可以并行执行,也能保证数据最终一致 否则两个事务需要按照 commit 顺序执行
假设有如下事务:
T1:Student, id=2 Teacher, id=2
T2:Teacher, id=1
T3:Teacher, id=2
T4:Student, id=2
T5:Student, id=1
T6:Student, id=1 Teacher, id=1
可知:T3、T4 依赖 T1;T6 依赖 T2,T5;
所以:
T1、T2、T5 可以并行执行;
T1 执行完成后,T3、T4 可以并行执行;
T6 需要等 T2、T5 完成之后才能执行;
还有一点要注意,由于并行化执行,已复制的事务不能作为 checkpoint。所以:
在事务冲突检查之前先入双向队列 事务提交不能将事务作为 Checkpoint,而是在双向队列中移除该事务 获取当前双向队列的 head 作为 Checkpoint 确保不丢失任何数据 断点续传可能会拉取到已经同步的事务,需要确保幂等
关键点5:外键约束
同步链路中,要注意表之间是否存在外键约束,如果有,要一起同步。
假设有两张表:
CREATE TABLE dept(
id INT PRIMARY KEY,
deptName VARCHAR(20)
);
CREATE TABLE employee(
id INT PRIMARY KEY,
empName VARCHAR(20),
deptId INT,
CONSTRAINT emlyee_dept_fk FOREIGN KEY(deptId) REFERENCES dept(id)
);
可以在全量同步阶段先迁移 dept,后同步 employee。可能会出现复制 employee 表里数据不满足外键约束的情况,可以忽略这些数据。原因是在复制过程中如果出现外键约束不满足的情况,在增量阶段必然能补齐。增量阶段的冲突检测考虑外键约束。例如当出现 dept id=1 和 employeedeptId=1 的情况,当做冲突,串行执行。
关键点6:循环复制
在数据库双活的场景中,存在双向复制的情况。比如下图 A->B 和 B->A 都有增量链路。
双向同步会有一些问题:比如业务一条 Update 语句在 A 上做了更新,增量复制链路从 A 写入 B,在 B 上也会生成日志。从 B 到 A 的同步链路会继续同步这条 Update,会导致数据 time travel,也会增加写入压力。
解决这个问题的方案,就是防循环复制。
防循环复制需要在增量数据中标记数据为同步链路写入,在做增量复制的时候,忽略这部分数据。
防循环复制主要有两个方案:
目标端数据库支持将 session 上的属性落到日志中,可以通过该属性区分数据写入来源。
在目标端建一张表,在同步链路写入事务时增加一个对该表数据的更新,可以通过事务中是否有该表的数据变更确认该事务是否是同步链路写入(可以和之前的防事务回放复用事务表)。
