




大家好,我是小寒。
这样的数据集很常见,被称为「不平衡数据集。」
不平衡数据集是分类问题的一种特殊情况,其中类之间分布不均匀。通常,它们由两个类组成:多数(负)类和少数(正)类。
在不同的领域都会有这样的数据集,例如:
「金融」:欺诈检测数据集的欺诈率通常约为 1%-2% 「广告服务」:点击预测数据集的点击率也不高。 「运输」/「航空公司」:飞机发生故障的概率也非常低。 「医疗」:患者是否患有癌症的概率很低。
那么我们如何解决这些问题呢?
1、随机欠采样和过采样
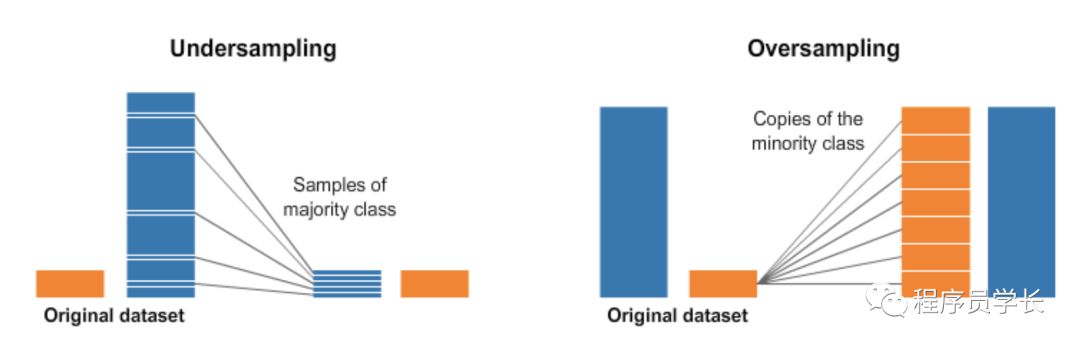
让我们首先创建一个不平衡的数据集。
from sklearn.datasets import make_classification
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10
)
X = pd.DataFrame(X)
X['target'] = y
我们现在可以使用以下方法进行随机过采样和欠采样:
num_0 = len(X[X['target']==0])
num_1 = len(X[X['target']==1])
print(num_0,num_1)
#random undersample
undersampled_data = pd.concat([X[X['target']==0].sample(num_1),X[X['target']==1]])
print(len(undersampled_data))
# random oversample
oversampled_data = pd.concat([X[X['target']==0],X[X['target']==1].sample(num_0,replace=True)])
print(len(oversampled_data))
2、使用 imblearn 进行欠采样和过采样
imblearn 是 python 的一个包,用于解决不平衡的数据集。它提供了多种欠采样和过采样的方法。
a、使用 Tomek Links 进行欠采样
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)
b. 使用 SMOTE 进行过采样。
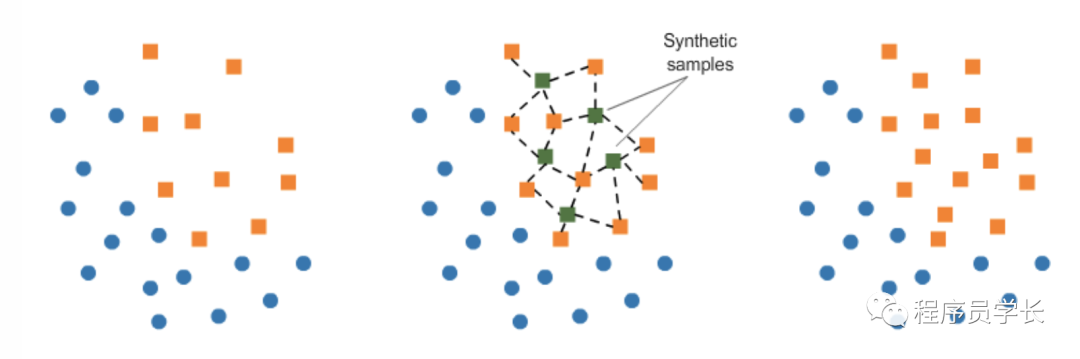
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(return_indices=True, ratio='majority')
X_tl, y_tl, id_tl = tl.fit_sample(X, y)
3、模型中的 class_weights

from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(class_weight={0:1,1:10})
Loss = −ylog(p) − (1−y)log(1−p)
「在这种特殊形式中,我们对正类和负类赋予相同的权重。」
class_weight = {0:1,1:20}时,后台的分类器会尝试最小化:
NewLoss = −20*ylog(p) − 1*(1−y)log(1−p)
「那么这里到底发生了什么?」
如果我们的模型给出的概率为 0.3,并且我们对正样本进行了错误分类,则 NewLoss 的值为 -20 log(0.3) = 10.45 如果我们的模型给出的概率为 0.7,并且我们错误分类了一个负例,则 NewLoss 的值是 -log(0.3) = 0.52
「我们如何计算 class_weights?」
from sklearn.utils.class_weight import compute_class_weight
class_weights = compute_class_weight('balanced', np.unique(y), y)
4、改变你的评估指标
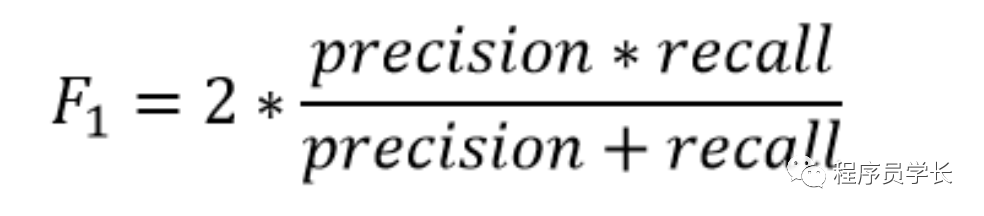
「那么它有什么帮助呢?」
让我们从一个二元预测问题开始。 「我们正在预测小行星是否会撞击地球。」
因此,我们创建了一个模型,「将整个数据集都预测为 “否”。」
「准确度是多少(通常是最常用的评估指标)?」
超过 99%,所以从准确率上看,这个模型还不错,但一文不值。
「现在,F1 score 是多少?」
正类的召回率是多少?它为零。因此 F1 分数也是 0。
简单来说, 「F1 score 在分类器的精度和召回率之间保持平衡」。
你可以使用以下方法计算二元预测问题的 F1 score:
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 1]
y_pred = [0, 0, 1, 0, 0, 1]
f1_score(y_true, y_pred)
5、其它
根据你的用例和你要解决的问题,其他各种方法可能会起作用:
a、收集更多数据
b、将问题视为异常检测
你可能希望将分类问题视为异常检测问题。
c、基于模型
有些模型特别适合不平衡的数据集。
最后
接下来我们会分享更多的 「深度学习案例以及python相关的技术」,欢迎大家关注。
「进群方式:加我微信,备注 “python”」
最后
—
这期文章就分享到这里,如果觉得不错,转发、在看、点赞安排起来吧。
你知道的越多,你的思维越开阔。我们下期再见。

往期回顾

如果对本文有疑问可以加作者微信直接交流。进技术交流群的可以拉你进群。

文章转载自程序员学长,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
