




大家好,我是小寒。
scikit-learn 是用 Python 构建机器学习最常用的库之一。它的受欢迎程度可归因于其简单且一致的代码结构,这对初学者很友好。
该库包含多个用于分类、回归和聚类的机器学习模型。
安装 scikit-learn 库
pip install scikit-learn
加载数据集
使用 scikit-learn 自带的 “Wine” 数据集。该数据集共有 178 个样本和 3 个类别。
from sklearn.datasets import load_wine
from sklearn.datasets import load_wine
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score,classification_report
from sklearn.model_selection import train_test_split
切分训练和测试数据
X, y = load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42
)
训练模型
逻辑回归
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
y_pred_lr = model_lr.predict(X_test)
print("Accuracy Score: ", accuracy_score(y_pred_lr, y_test))
print(classification_report(y_pred_lr, y_test))
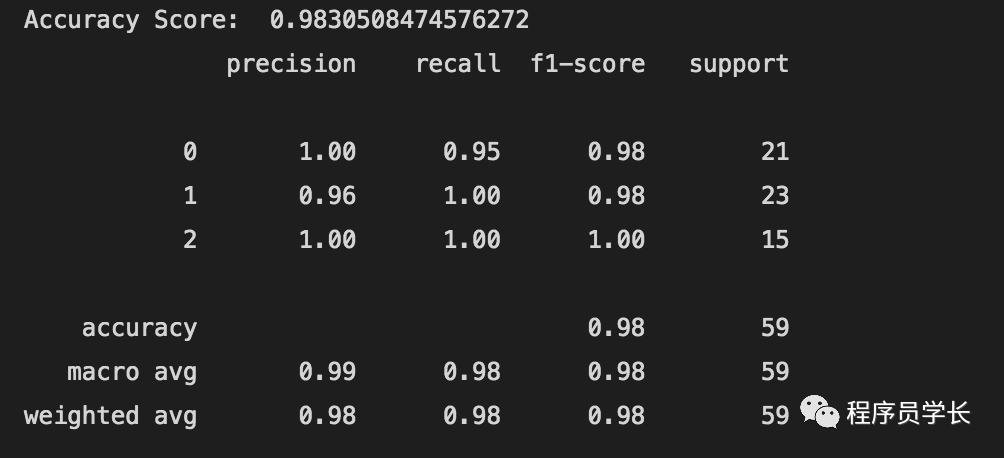
KNN
model_knn = KNeighborsClassifier(n_neighbors=1)
model_knn.fit(X_train, y_train)
y_pred_knn = model_knn.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_knn, y_test))
print(classification_report(y_pred_knn, y_test))
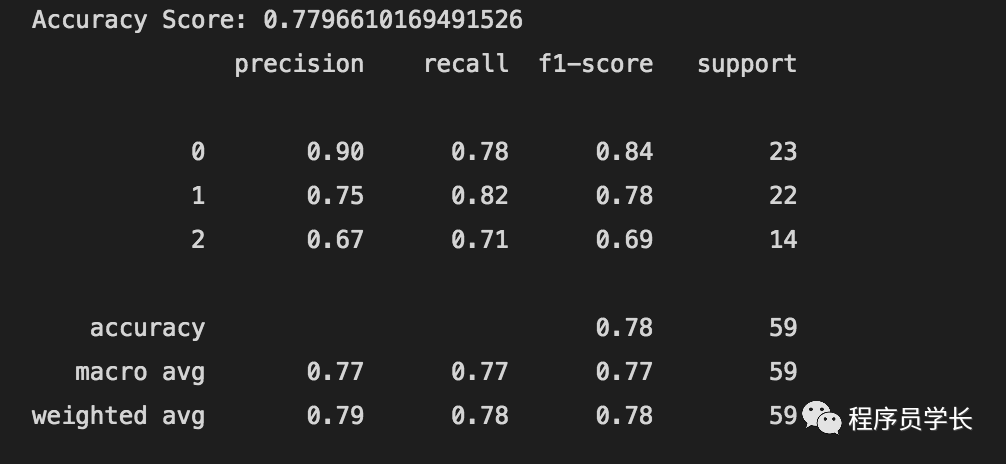
朴素贝叶斯
model_nb = GaussianNB()
model_nb.fit(X_train, y_train)
y_pred_nb = model_nb.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_nb, y_test))
print(classification_report(y_pred_nb, y_test))
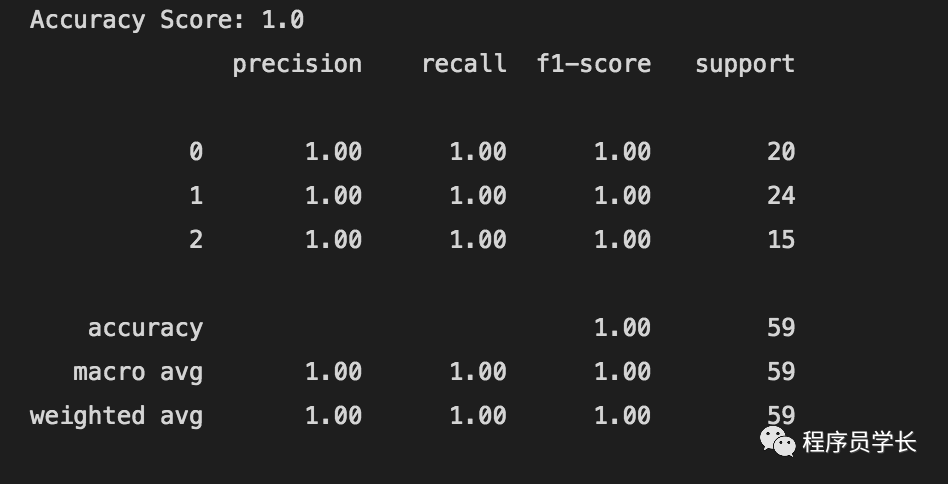
决策树
from sklearn.tree import DecisionTreeClassifier
model_dtclassifier = DecisionTreeClassifier()
model_dtclassifier.fit(X_train, y_train)
y_pred_dtclassifier = model_dtclassifier.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_dtclassifier, y_test))
print(classification_report(y_pred_dtclassifier, y_test))

随机森林
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
def get_best_parameters():
params = {
"n_estimators": [10, 50, 100],
"max_features": ["auto", "sqrt", "log2"],
"max_depth": [5, 10, 20, 50],
"min_samples_split": [2, 4, 6],
"min_samples_leaf": [2, 4, 6],
"bootstrap": [True, False],
}
model_rfclassifier = RandomForestClassifier(random_state=42)
rf_randomsearch = RandomizedSearchCV(
estimator=model_rfclassifier,
param_distributions=params,
n_iter=5,
cv=3,
verbose=2,
random_state=42,
)
rf_randomsearch.fit(X_train, y_train)
best_parameters = rf_randomsearch.best_params_
print("Best Parameters:", best_parameters)
return best_parameters
parameters_rfclassifier = get_best_parameters()
model_rfclassifier = RandomForestClassifier(
**parameters_rfclassifier, random_state=42
)
model_rfclassifier.fit(X_train, y_train)
y_pred_rfclassifier = model_rfclassifier.predict(X_test)
print("Accuracy Score:", accuracy_score(y_pred_rfclassifier, y_test))
print(classification_report(y_pred_rfclassifier, y_test))
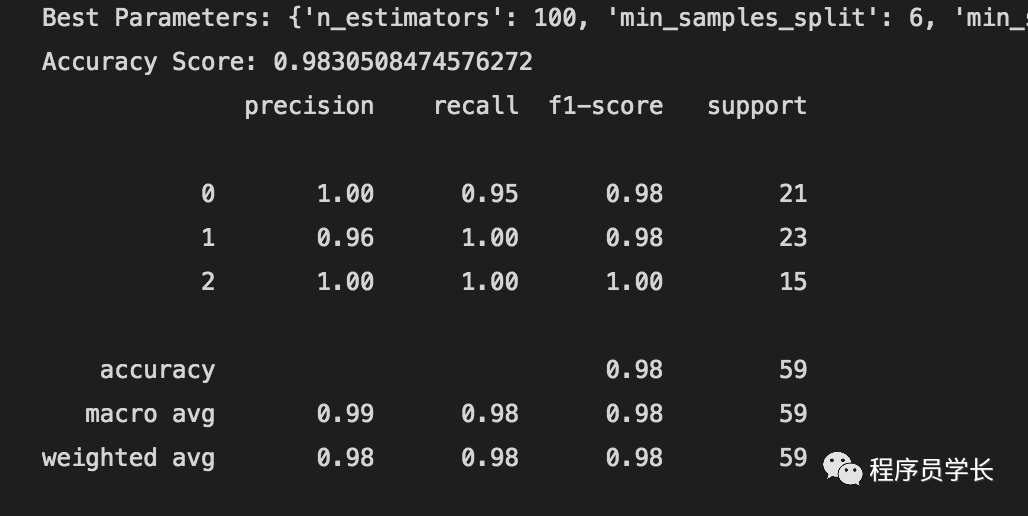
在这个算法中,我们进行了一些超参数调整以达到最佳精度。
我们定义了一个参数网格,其中包含多个值供每个参数选择。
此外,我们使用随机搜索算法来搜索模型的最佳参数空间。
最后,我们将获得的参数提供给分类器并训练模型。
最后
—
「进群方式:加我微信,备注 “python”」

往期回顾

如果对本文有疑问可以加作者微信直接交流。进技术交流群的可以拉你进群。

文章转载自程序员学长,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
