




大家好,我是小寒。
今天,我们来聊一下集成学习。
「简而言之,它结合了模型中的不同的决策以提高性能。」
一、平均
导入数据包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score,accuracy_score
from sklearn.preprocessing import StandardScaler
# machine learning
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression, SGDClassifier
#seed
seed = 40
简单平均
我们通过将所有模型的「输出相加并除以模型总数来取一个简单的平均值。」
使用 pandas 加载数据集文件。 目标是 "output" 特征。 删除 "output" 特征,以创建训练特征。 使用 StandardScaler () 进行特征缩放。 将数据拆分为训练集和测试集。 构建所有三个模型对象。我们使用的是 RandomForestClassifier、LogisticRegression 和 SGDClassifier。 在训练集上训练模型并使用测试集预测输出。 使用平均公式并将输出四舍五入以仅显示 1 和 0。 显示准确性和 AUC 指标。
df = pd.read_csv("heart.csv")
#target
target = df["output"]
# getting scaled train data
train = df.drop("output", axis=1)
scaled_train = StandardScaler().fit_transform(train)
# Splitting the data into training and validation
X_train, X_test, y_train, y_test = train_test_split(
train, target, test_size=0.20, random_state=seed
)
# building the all models
model_1 = RandomForestClassifier(random_state=seed)
model_2 = LogisticRegression(random_state=seed, max_iter=1000)
model_3 = SGDClassifier(random_state=seed)
# training
model_1.fit(X_train, y_train)
model_2.fit(X_train, y_train)
model_3.fit(X_train, y_train)
# predicting
pred_1 = model_1.predict(X_test)
pred_2 = model_2.predict(X_test)
pred_3 = model_3.predict(X_test)
# averaging
pred_final = np.round((pred_1 + pred_2 + pred_3) / 3)
# evalution
accuracy = round(accuracy_score(y_test, pred_final) * 100, 3)
auc = round(roc_auc_score(y_test, pred_final), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 85.246%
AUC score: 0.847
加权平均
| 「model_1」 | 「model_2」 | 「model_3」 | |
|---|---|---|---|
| 「权重」 | 30% | 60% | 10% |
「Tips: 需要保证权重相加等于1」
pred_final = np.round(0.3*pred_1 + 0.6*pred_2 + 0.1*pred_3)
# evalution
accuracy = round(accuracy_score(y_test, pred_final) * 100, 3)
auc = round(roc_auc_score(y_test, pred_final), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 90.164%
AUC score: 0.89
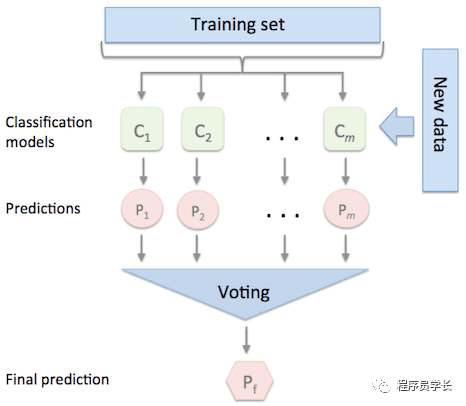
二、投票
「投票法通常用于分类问题。」
在这种方法中,「每个模型对每个样本进行预测和投票。」
最终选择投票最高的类作为最终的预测类。
from sklearn.ensemble import VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
# building the model
model_4 = KNeighborsClassifier()
# voting classifier
final_model = VotingClassifier(
estimators=[("rf", model_1), ("lr", model_2), ("knn", model_4)],
voting="hard",
)
# training
final_model.fit(X_train, y_train)
# prediction
prediction = final_model.predict(X_test)
# evaluation
accuracy = round(accuracy_score(y_test, prediction) * 100, 3)
auc = round(roc_auc_score(y_test, prediction), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 90.164%
AUC score: 0.89
正如我们所看到的,我们得到了比简单平均更好的结果。
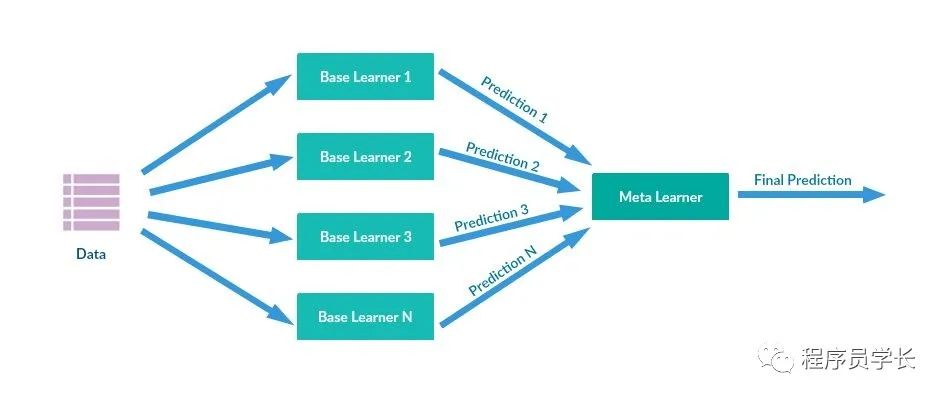
三、堆叠
堆叠 「通过元模型(元分类器或元回归)组合多个基本模型。」
基础模型和元模型通常是不同的。
简而言之,元模型帮助基础模型找到有用的特征以实现高性能。
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
# building the model
model_5 = AdaBoostClassifier(random_state=seed)
estimators = [("rf", model_1), ("lr", model_2), ("ada", model_5)]
# building the model
final_estimator = GradientBoostingClassifier(random_state=seed)
# Stacking Classifier
clf = StackingClassifier(estimators=estimators, final_estimator=final_estimator)
# training
clf.fit(X_train, y_train)
# prediction
prediction = clf.predict(X_test)
# evaluation
accuracy = round(accuracy_score(y_test, prediction) * 100, 3)
auc = round(roc_auc_score(y_test, prediction), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 83.607%
AUC score: 0.837
四、Bagging
「Bagging 是一种提高机器学习模型稳定性和准确性的集成方法。」
它用于最小化方差和过拟合。一般应用于决策树方法。
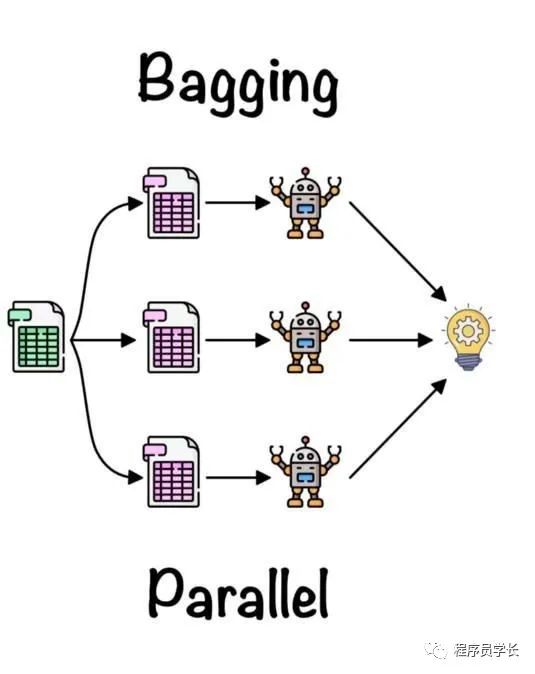
通过组合来自基本模型的所有输出来创建最终输出。
from sklearn.ensemble import BaggingClassifier
# bagging
clf = BaggingClassifier(
LogisticRegression(random_state=seed, max_iter=2000),
n_estimators=20,
random_state=seed,
)
# training
clf.fit(X_train, y_train)
# prediction
prediction = clf.predict(X_test)
# evaluation
accuracy = round(accuracy_score(y_test, prediction) * 100, 3)
auc = round(roc_auc_score(y_test, prediction), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 90.164%
AUC score: 0.89
五、Boosting
你可以通过连续训练弱分类器来获得高性能。
它是一种迭代算法,根据之前的模型调整权重。
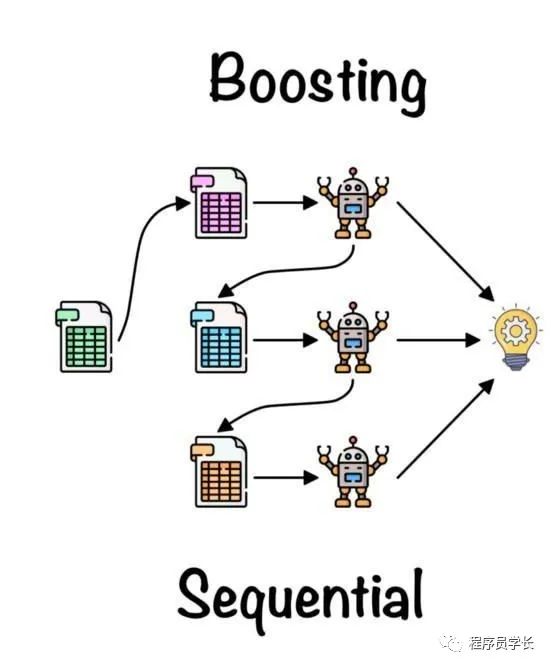
在示例中,我们将使用 AdaBoost 分类器。
# boosting
clf = AdaBoostClassifier(random_state=seed)
# training
clf.fit(X_train, y_train)
# prediction
prediction = clf.predict(X_test)
# evaluation
accuracy = round(accuracy_score(y_test, prediction) * 100, 3)
auc = round(roc_auc_score(y_test, prediction), 3)
print(f" Accuracy: {accuracy}%")
print(f" AUC score: {auc}")
Accuracy: 80.328%
AUC score: 0.804
最后
今天我们介绍了集成学习的相关知识。
「如果需要完整代码,可以加我微信: algo_code」
「进群方式:加我微信,备注 “python”」

往期回顾

如果对本文有疑问可以加作者微信直接交流。进技术交流群的可以拉你进群。

文章转载自程序员学长,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
