





背景
Cloud Native
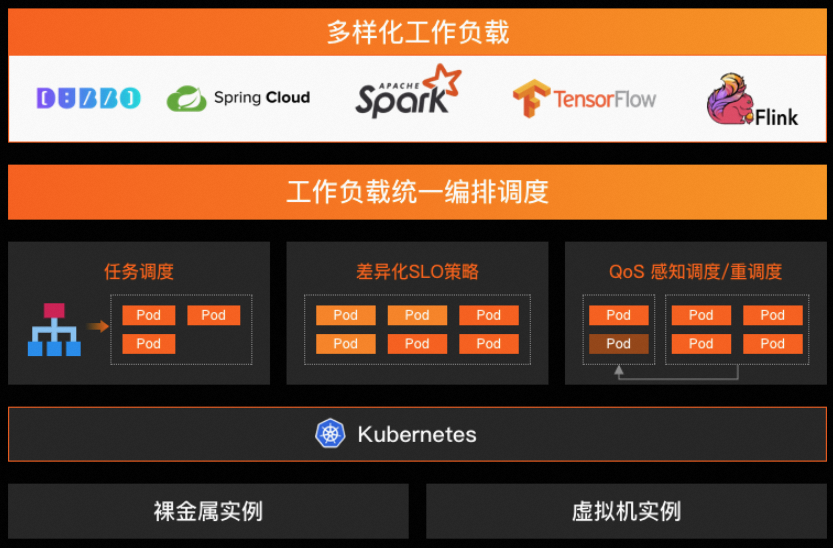
Koordinator 是一个开源项目,基于阿里巴巴在容器调度领域多年累积的经验孵化诞生,可以提升容器性能,降低集群资源成本。通过混部、资源画像、调度优化等技术能力,能够提高延迟敏感的工作负载和批处理作业的运行效率和可靠性,优化集群资源使用效率。
新特性早知道
Cloud Native
节点资源预留
节点资源预留声明
apiVersion: v1kind: Nodemetadata:name: fake-nodeannotations: # specific 5 cores will be calculated, e.g. 0, 1, 2, 3, 4, and then those core will be reserved.node.koordinator.sh/reservation: '{"resources":{"cpu":"5"}}'---apiVersion: v1kind: Nodemetadata:name: fake-nodeannotations: # the cores 0, 1, 2, 3 will be reserved.node.koordinator.sh/reservation: '{"reservedCPUs":"0-3"}'
单机组件 Koordlet 在上报节点资源拓扑信息时,会将具体预留的 CPU 编号更新到 NodeResourceTopology 对象的 Annotation 中。
调度及重调度场景适配
cpus(alloc) = cpus(total) - cpus(allocated) - cpus(kubeletReserved) - cpus(nodeAnnoReserved)
此外,对于 Batch 混部超卖资源的计算同样需要将这部分资源扣除,而考虑到节点中还包括一部分系统进程的资源消耗,Koord-Manager 在计算时会取节点预留和系统用量的最大值,具体为:
reserveRatio = (100-thresholdPercent) 100.0node.reserved = node.alloc * reserveRatiosystem.used = max(node.used - pod.used, node.anno.reserved)Node(BE).Alloc = Node.Alloc - Node.Reserved - System.Used - Pod(LS).Used
对于重调度,各插件策略需要在节点容量、利用率计算等场景感知节点预留资源量,此外,若已经有容器占用了节点的预留资源,重调度需要考虑将其进行驱逐,确保节点容量得到正确管理,避免资源竞争。这部分重调度相关的功能,我们将在后续版本进行支持,也欢迎广大爱好者们一起参与共建。
单机资源管理
suppress(BE) := node.Total * SLOPercent - pod(LS).Used - max(system.Used, node.anno.reserved)
兼容社区重调度策略
HighNodeUtilization LowNodeUtilization PodLifeTime RemoveFailedPods RemoveDuplicates RemovePodsHavingTooManyRestarts RemovePodsViolatingInterPodAntiAffinity RemovePodsViolatingNodeAffinity RemovePodsViolatingNodeTaints RemovePodsViolatingTopologySpreadConstraint DefaultEvictor
在使用时,可以参考如下的方式配置,以 RemovePodsHavingTooManyRestarts 为例:
apiVersion: descheduler/v1alpha2kind: DeschedulerConfigurationclientConnection:kubeconfig: "/Users/joseph/asi/koord-2/admin.kubeconfig"leaderElection:leaderElect: falseresourceName: test-deschedulerresourceNamespace: kube-systemdeschedulingInterval: 10sdryRun: trueprofiles:- name: koord-deschedulerplugins:evict:enabled:- name: MigrationControllerdeschedule:enabled:- name: RemovePodsHavingTooManyRestartspluginConfig:- name: RemovePodsHavingTooManyRestartsargs:apiVersion: descheduler/v1alpha2kind: RemovePodsHavingTooManyRestartsArgspodRestartThreshold: 10
资源预留调度能力增强
支持 AMD 环境下的 L3 Cache 和内存带宽隔离
# Intel Format# resctrl schemaL3:0=3ff;1=3ffMB:0=100;1=100# AMD Format# resctrl schemaL3:0=ffff;1=ffff;2=ffff;3=ffff;4=ffff;5=ffff;6=ffff;7=ffff;8=ffff;9=ffff;10=ffff;11=ffff;12=ffff;13=ffff;14=ffff;15=ffffMB:0=2048;1=2048;2=2048;3=2048;4=2048;5=2048;6=2048;7=2048;8=2048;9=2048;10=2048;11=2048;12=2048;13=2048;14=2048;15=2048
接口格式包含两部分,L3 表示对应的 socket 或 CCD 可用的“路数”(way),以 16 进制的数据格式表示,每个比特位表示一路;MB 表示对应的 socket 或 CCD 可以使用的内存带宽范围,Intel 可选范围为 0~100 的百分比格式,AMD 对应的为绝对值格式,单位为 Gb/s,2048 表示不限制。Koordiantor 统一提供了百分比格式的接口,并自动感知节点环境是否为 AMD,决定 resctrl 接口中填写的格式。
apiVersion: v1kind: ConfigMapmetadata:name: slo-controller-confignamespace: koordinator-systemdata:resource-qos-config: |-{"clusterStrategy": {"lsClass": {"resctrlQOS": {"enable": true,"catRangeStartPercent": 0,"catRangeEndPercent": 100,"MBAPercent": 100}},"beClass": {"resctrlQOS": {"enable": true,"catRangeStartPercent": 0,"catRangeEndPercent": 30,"MBAPercent": 100}}}}
其他功能
通过 v1.2 release[1] 页面,可以看到更多版本所包含的新增功能。
未来计划
Cloud Native
在接下来的版本中,Koordiantor 重点规划了以下功能,具体包括:
硬件拓扑感知调度,综合考虑节点 CPU、内存、GPU 等多个资源维度的拓扑关系,在集群范围内进行调度优化。 对重调度器的可观测性和可追溯性进行增强。 GPU 资源调度能力的增强。

https://github.com/koordinator-sh/koordinator/releases/tag/v1.2.0
