




在线AB实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的应用来做一次AB实验作为数据驱动的试金石。在连载的上中,我们介绍了AB实验与数据驱动的背景以及AB实验的基本架构,本篇重点介绍实验指标的选取与数据分析。

文 | 松宝 来自 字节跳动数据平台团队增长平台
本系列连载会从数据驱动、AB实验基本架构、指标选取与数据分析等角度切入,在连载的上中,我们介绍了AB实验与数据驱动的背景以及AB实验的基本架构,本篇重点介绍实验指标的选取与数据分析。
A/B Test
AB实验的指标选取
01 - 指标特性
核心指标:需要优化的目标指标,决定这个实验的最终发展方向。这种指标在一个实验是非常少的,在运行之后是不做改变的。
非核心指标指标:与核心指标有因果关系的+基础数据的指标,基础数据的指标是应用运行的底线。
指标敏感性:指标对所关心的事物是否足够敏感 指标鲁棒性:指标对不关心的事物是否足够不敏感
02 - 自顶向下设计指标
定义一:登陆后总点击次数 登陆后的去重后的访问总数
定义二:被点击的页面数 总页面数 定义三:总的页面点击次数 总页面数
A/B Test
数据分析
01 - 实验结果显著
这是第一类错误:实际没有区别,但实验结果表示有区别,我们得到显著结果因此否定原假设,认为实验组更优,发生的概率用 𝛂 表示。
这是第二类错误:实际有区别,但是实际结果表示没有区别,我们得到不显著的结果因此无法拒绝原假设,认为实验组和对照组没有区别,发生的概率用 𝜷 表示。
简单来说:p值判断不同版本的实验结果之间不存在显著差异的概率。 p-value越小越可信,有显著差异的指标,P-value=0.01的比P-value=0.05的可信度更高。 p值基本上还有另一个相对应的叫作t值,这个p值其实就是在t分布下≥t值的概率密度值(P(x≥t))。
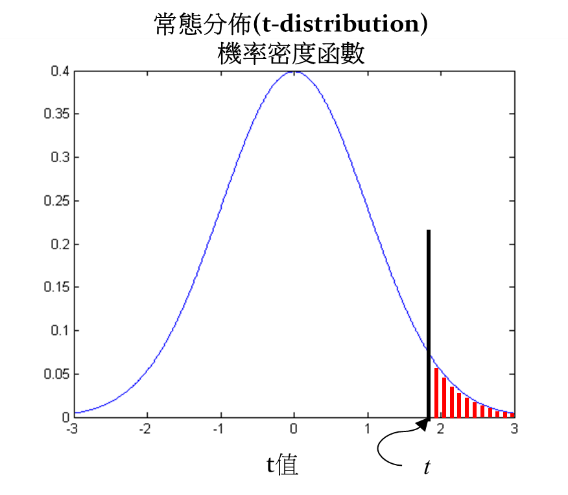
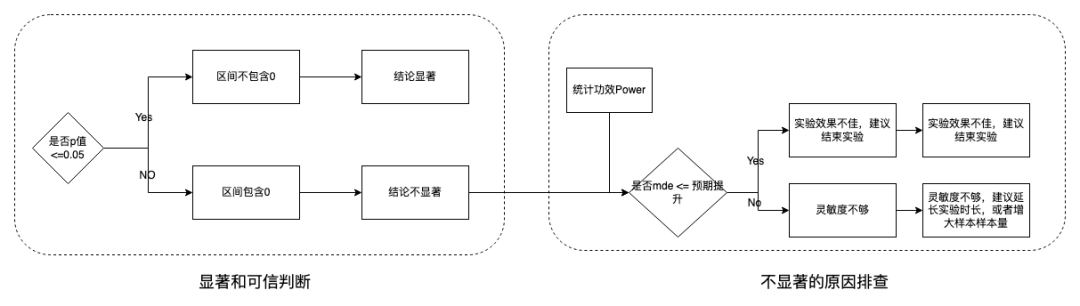
p值 > α(显著水平α,α 值一般5%) ,说明A版本和B版本没有太大差别,不存在显著性差异。 p值 < α(显著水平,α 值一般5%),说明A版本和B版本有很大的差别,存在显著性差异。 我们根据判断 p 值和第一类错误概率 α 比较,已经做了决策。是不是觉得大功告成,不,我们可以继续考虑power统计功效来衡量实验的可信。也就是我们要同时考虑第二类错误概率,这时候引入power统计功效。
可以理解为有多少的把握认为版本之间有差别。 该值越大则表示概率越大、功效越充分。 一般来说,我们一般并设置的最低的统计功效值为80%以上。认为这样的可信度是可以接受的。
实验开启前,通过流量计算器中计算流量和实验运行时长。 实验开启后,通过power=80%,然后计算MDE。
当前条件:指当前样本量,指标值和指标分布情况,并假设样本方差与总体指标方差足够接近。 有效检测:指检出概率大于等于80%(也就是犯第二类错误概率 𝜷 <=20%) 主要影响因素:样本量大小
如果此时MDE=0.5%,MDE < 预期提升值,说明指标变化真的不显著,请结合业务ROI和其他维度里例如用户体验、长期战略价值等来综合判断是否值得上线; 如果那此时MDE=2%,MDE > 预期提升值,说明当前能检验出显著性的最小差异值是2%,由于灵敏度不足未能检测出。这种情况下建议增大样本量,例如扩大流量、再观察一段时间积累更多进组用户,指标还有置信的可能。
如果置信区间上下限的值同为正或负,认为存在有显著差异的可能性; 如果同时正负值,那么则认为不存在有显著差异的可能性。
可以这样简单但不严谨地解读置信区间:假设策略全量上线,你有95%的把握会看到真实的指标收益在置信区间这个范围内。
02 - 多次测试
03 - 方差的计算
t检测中我们需要对数据的方法进行计算。有时候我们的“方差”计算是有问题的,之前有说到的「随机单元」和「分析单元」不一致的情况下,计算比率型的指标,比如点击率。
04 - 样本比率偏差
在理想的状态下,对照组和实验组的流量是一半一半的,也就是50%的进入到对照组,50%的进入到实验组。但是现实是残酷的,比如会出现50.27%的用户进入到对照组,另外49.73%的用户进入到实验组。
05 - AA实验
06 - 对照组和实验组之间干涉
07 - 指标的长期效果
 点击阅读原文了解火山引擎A/B测试
点击阅读原文了解火山引擎A/B测试
产品介绍
火山引擎A/B测试
A/B测试,摆脱猜测,用科学的实验衡量决策收益,打造更好的产品,让业务的每一步都通往增长。后台回复数字“8”了解产品
- End -
文章转载自字节跳动数据平台,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
