




最近有朋友和小y反馈:
他们的一台IBM的X86服务器(现在属于联想)出现硬件损坏,维护人员通过管理口收集诊断日志给厂商时,服务器上运行的好好的一套ORACLE 11.2的RAC数据库,
突然有一个节点重启了..这是是什么情况?
听到这里,小y基本上猜到了原因,类似的问题,以前分析和处理过几次,分析过程也不复杂,但是没想到,类似的故障现在居然还在发生.
因此有必要把这个风险提示出来!
这里,小y为大家分享一个过去处理的案例,文章最后会给出X86服务器与RAC结合的具体的风险提示,希望大家早了解,早预防,避免踩坑,伤人伤己。

问题来了!!
周五,晚上十一点,电话响了,是一位服务商的电话,看来出大事了,一下来了精神;
“小y,一套linux上的11.2.0.3 2节点的RAC, 节点2数据库今天下午自己重启了一次,后来自己起来了。 几个小时前,又挂了,到现在还没起来! 两个节点私网IP互相ping了一下,可以ping通! 你赶紧远程连上来处理下吧” |
BTW:
是的,大家没看错,是服务商而不是最终客户的电话。
小y所在的公司不仅直接面向客户提供数据库专家服务,也为其他服务商、软件开发商提供三线支持,不过小y最近业绩压力大的晚上睡不着觉,还请各位兄弟多多帮忙推荐和介绍啊。
分析与恢复故障
时间紧急,远程连入后,发现节点2确实挂掉了,那就直接startup启动数据库看看

照理来说,startup命令下去后,这里很快就可以看到SGA分配并启动到mount的信息,
但命令下去已经一分钟了,还没任何输出,确实不妙。
最终,startup命令在敲入后长时间依然无响应,大概10分钟后后报ORA-03113错误后退出。
如下图所示:

看来,数据库启动过程中遇到了异常,需要继续分析alert日志。
截取altert日志关键信息,如下图所示:
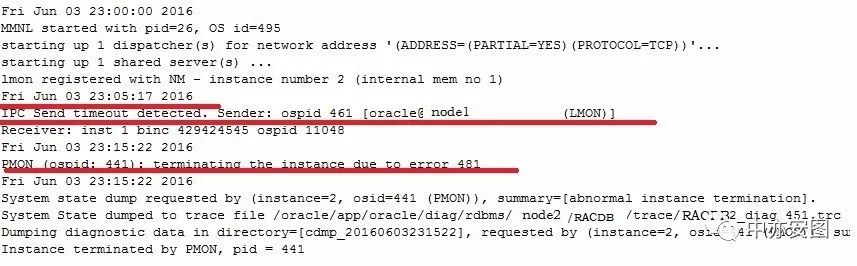
可以看到:
由于节点2的Lmon进程通过ipc与节点1的LMON进程通讯超时,简单来说,两个节点的RAC无法通讯,因此无法加入集群。因此需要进一步检查两个节点的私网通讯是否正常。
之前他们提到两个节点的私网IP是可以ping通的,我估计他们是ping错IP了。
因为,从11.2.0.2(含)开始,ORACLE私网通讯不再直接采用“我们在私网网卡上所配置的地址(例如192.168这样的地址)”,而是采用GRID启动后,ORACLE在私网网卡上绑定的169.254这个网段的地址。确认了一下,他们果然ping的是192.168这个IP,这个IP能PING通是不够的…
发出下列命令获得,两个节点私网通讯采用的IP地址如下所示:

也就是说,RAC两个节点用于私网通讯的真实地址是:
节点1采用的私网通讯地址是169.254.220.75,而不是192.168.x.x
节点2采用的私网通讯地址是169.254.106.133,而不是192.168.x.x
也就是说,GRID启动前后的IP,如下所示:
Node1 | Node2 | 备注 | |
Bond0 | 192.168.1.1 | 192.168.1.2 | GRID启动前、启动后都存在的IP |
Bond0:1 | 169.254.220.75 | 169.254.106.133 | GRID启动后才存在的IP RAC和ASM通讯使用 |


从上图可以看到:
两个节点之间互相ping不通169.254这个实际的私网通讯地址!这就是为什么节点2的数据库实例加不到集群的原因!
到这里,我们不妨用一张表表格小结一下:
其中bond0是私网网卡,192.168是手工配置的,169.254这个IP是GRID起来后绑上去的:
Node1 | Node2 | ||
Bond0 | 192.168.1.1 | 192.168.1.2 | 可以互相ping通 |
Bond0:1 | 169.254.220.75 | 169.254.106.133 | 互相ping不通 |
这是什么情况呢?
其实很简单,别着急,问题原因就在后面,什么时候往下翻,由你决定…
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……
……
那是什么原因导致两个地址不通呢?
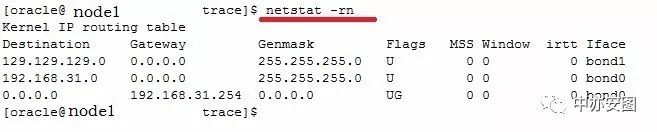
我们进一步检查两个节点的路由情况,发现了异常。如下所示
检查,发现节点1上的私网路由丢失,导致两个节点之间的私网无法正常通讯,继而无法正常加入集群。
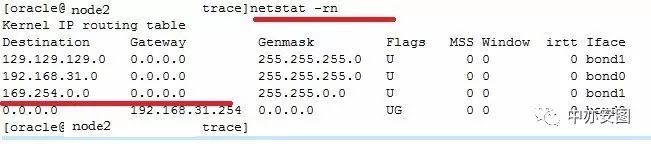
而节点2上是存在169.254这个路由的!
在节点1 即node1上使用root用户执行下列命令,补充丢失的路由即可
#route add -net 169.254.0.0 netmask 255.255.0.0 dev bond1 |
在节点1上实施该解决方案后,节点2数据库实例启动正常,问题得到解决。
到这里,有同学说,可以不可以把两个节点的GRID全部停掉,全部重启来恢复呢? 答案是yes ! |
因为重启GRID,会重新在bond0绑169.254这个IP,同时添加169.254.0.0这个路由 。
但是缺点也是显而易见的,两个节点停掉,业务不就停了么?
另外,万一节点1停了也起不来了呢?客户显然无法接受。
我们手工加路由其实和GRID加路由是一样的命令,理解本质了,变化会更多一些。
节点1到169.254这个网段的路由丢失,导致两个节点私网无法通讯。
这个路由和169.254的IP都是grid在启动的时候进行绑定IP和添加路由的。
首先,我们通过检查历史命令,排除了人为删除路由的可能。
继续检查节点1这个节点GRID的alert日志,可以看到:
在6月3日19点36分,出现了oraRootAgent将路由删除的日志,而当时这个设备是usb0!即IMM服务器管理口!
2016-06-02 23:05:47.457: [crsd(10403)]CRS-2772:Server 'node2' has been assigned to pool 'ora.RACDB'. 2016-06-03 19:36:48.517: [/oracle/app/11.2.0.3/grid/bin/orarootagent.bin(8641)]CRS-5018:(:CLSN00037:) Removed unused HAIP route: 169.254.95.0 255.255.255.0 0.0.0.0 usb0 2016-06-03 19:41:30.805: |
其次,操作系统/var/log/messages显示:
在路由被删除前,系统正在为usb0网卡通过DHCP动态申请IP,并最终在问题出现前的20秒左右,在usb0上分配了169.254.95.120这个IP:
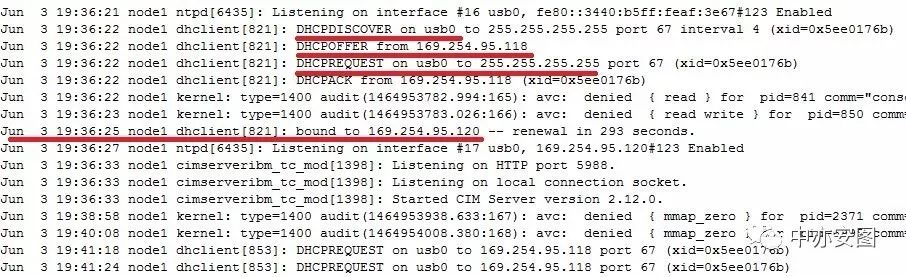
最终,节点2数据库数据库实例由于私网不通,IPC通讯超时,被驱逐出集群,日志如下
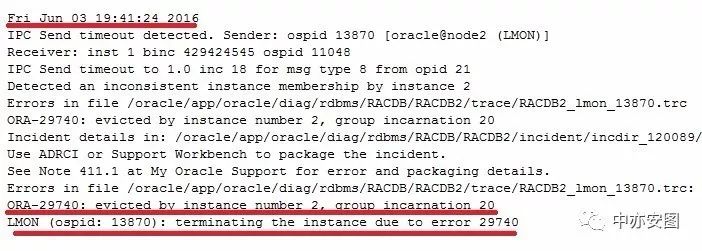
从上述分析不难发现,整个事情发生的顺序如下:
1) 19:36:25, 节点1 USB0网卡被分配169.254.95.120这个IP 2) 19:36:48, 节点1 orarootagent进程发现USB0上分配的169.254 IP与RAC集群通讯的IP冲突后删除169.254的路由 ,导致两个节点RAC无法通讯 3) 19:41:24, 节点2 报IPC 通讯超时,被驱逐出集群 4) 由于节点1的169.254的路由丢失,导致节点2 无法与节点1通讯,一直无法加入集群 5) 手工对节点1增加169.254的路由后,问题解决 |
不难看出来,这个行为是正常的行为!
我们以“Removed unused HAIProute: 169.254.95.0”作为搜索关键字,在METALINK上查找,MOS上的下面文章也介绍了这个行为,推测得到验证。
Oracle RAC H/A Failure Causes Oracle Linux Node Eviction On Server With IBM Integrated Management Module (IMM) (文档 ID 1629814.1) |
风险提示
在部署了ORACLE11.2.0.2或以上的版本中
由于集群的ASM和DB使用169.254.x.x作为集群私网通讯的IP
【GRID启动后在私网网卡绑定169.254.x.x这个IP并添加169.254.0.0的路由】
目前已知的情况中,IBM X86服务器装完操作系统后,存在USB0这样一块网卡,这个网卡是用来和IMM通讯的,IMM是服务器的管理口,通过USB网络的LAN进行硬件管理。
当USB0网卡被激活时,将分配169.265.95.120(118)这个IP,将导致RAC集群路由被破坏,继而导致DB/ASM无法通讯而重启/节点驱逐的故障, 并且由于路由丢失,导致RAC节点被驱逐出集群后,无法加入集群,需要人工介入处理。
不管是IBM/联想的X86服务器的IMM,还是其他品牌的服务器(例如DELL的iDRAC,或者是SUN的T系列),集群中的任何节点的任何网络设备都不应该分配169.254.x.x这个网段的IP【link local ip】,否则将导致RAC集群路由被破坏,导致节点驱逐的故障。
1)发出下列命令,检查系统是否曾经存在某个网卡动态分配过169.254这个网段的IIP
#cat /var/log/messages*|grep dhclient |grep "bound to 169.254" |
如有,则进入预防环节
2)发出下列命令,检查系统是否当前存在非RAC私有网卡被分配169.254这个网段的IP
# ifconfig -a .. usb0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XX inet addr:169.254.xx.xx Bcast:169.254.95.255 Mask:255.255.255.0 .. |
如有,则进入预防环节
修改这些网络设备如USB0口不采用DHCP,而是直接采用静态IP
##修改dhcp为static,并分配IP
# vi # BOOTPROTO=dhcp BOOTPROTO=static IPADDR=xxx.xxx.xxx.xxx |
##重启网卡,使改变生效
# sbin/ifdown usb0 # sbin/ifup usb0 # sbin/ifconfig usb0 |
数据库服务,就找中亦科技!
更多实战分享和风险提示,请关注“中亦安图”公众号!喜欢就转发吧,您的转发是我们持续分享的动力!也可以扫描下方的二维码,添加小y的微信,进微信群探讨技术;
联系我们:
电话:13701026113
邮箱:shadow.huang@ce-service.com.cn

技术人生系列(每周四首发)已经出到了四十一期,期间,很多读者咨询关于Oracle数据库实战培训的事情,于是,我们开始了第一期培训,帮助大家极致地使用数据库,而不是浅尝辄止,同时提升大家的职业价值(money)…
开课时间就在近期,重要的是:
两人以上报名,现在打六折!
下面是第一期的培训内容和报名方二维码,多多支持哦。


关注微信公众号,点击技术人生系列,浏览更多微信文章


关注公众号,回复数字查看精彩往期!
回复“030”第三十期:技术人生系列·我和数据中心的故事(第三十期)-一分钟查一个案例带你看看Oracle数据库到底有多牛逼
回复“031”第三十一期:技术人生系列·我和数据中心的故事(第三十一期)-【深度分析】一个你打死都想不到的死锁导致的应用异常
回复“032”第三十二期:技术人生系列·我和数据中心的故事(第三十二期)-看中国最美女DBA又一次奇葩问题的解决
回复“033”第三十三期:技术人生系列·我和数据中心的故事(第三十三期)-变更不重启,就是害自己!
回复“034”第三十四期:技术人生系列·我和数据中心的故事(第三十四期)-一个CASE看ORACLE新特性的本质
回复“035”第三十五期:技术人生系列·我和数据中心的故事(第三十五期)-从天而降的TRACE