




Table of Contents
一. 问题描述
需求:

卡在了reduce,只有一个reduce
MR job卡在了最后一个reduce,任务迟迟未运行成功

二. 解决方案
2.1 调整reduce个数
一般一个reduce处理的数据是1G,所以首先想能不能增加reduce的个数来调优上述Hive SQL。
-- 可以指定每个redcue处理的数据size,也可以直接指定reduce的个数
set hive.exec.reducers.bytes.per.reducer = 12000000;
经验证,调整了上述参数后,问题依旧没有得到解决。
2.2 SQL改写
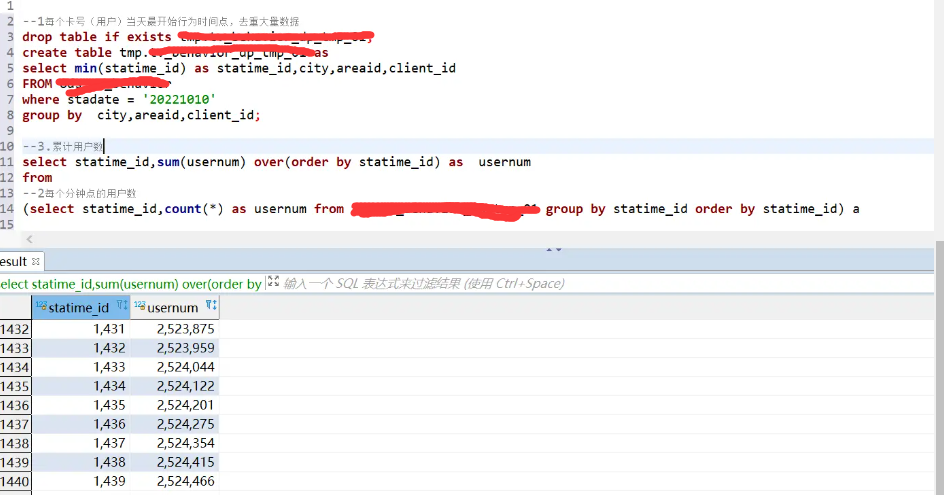
上述SQL所代表的业务逻辑是求截止当前每分钟的用户访问数(如出现多次,只算一次)
SQL也是因为 count(distinct)的存在,导致reduce数分配少了,进而出现数据性能问题。
所以首先我们想想能不能把count(distinct)去掉
因为本身是离线数据,此时可以借助临时表,首先把每个用户首次访问的时间记录下来,这样就可以将处理的数据大大减少,最后再通过开窗函数处理即可。
完美解决:
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
