





本文内容将围绕介绍铸就 Xtreme1 的倍赛科技的技术架构, Xtreme1 是倍赛SaaS平台的开源版,为了简化部署和使用,在架构和功能上做了适当简化。倍赛SaaS平台全面遵循云原生架构原则,以保证服务性能的可扩展性,部署规模的可弹性,以及在故障情况下的服务韧性。
以下为【开源秀】栏目嘉宾倍赛科技应用研发总监 王家军的演讲实录:
倍赛开源的 Xtreme1,是一个 MLOps 的AI 标注的训练数据平台架构,它是一个开源的产品,来源于倍赛的 SaaS 平台。不过在开源上面,为了去简化部署和使用,我们在架构和功能上适当做了一些简化。
倍赛 SaaS 平台全面遵循云原生架构的原则,保障服务性能的可扩展性,部署规模的可弹性,以及在故障情况下的服务韧性。作为一个SaaS,对性能、可弹性、韧性的要求是远远高于开源版本的。所以今天重点将分享 Xtreme1 背后的倍赛 SaaS 的架构。
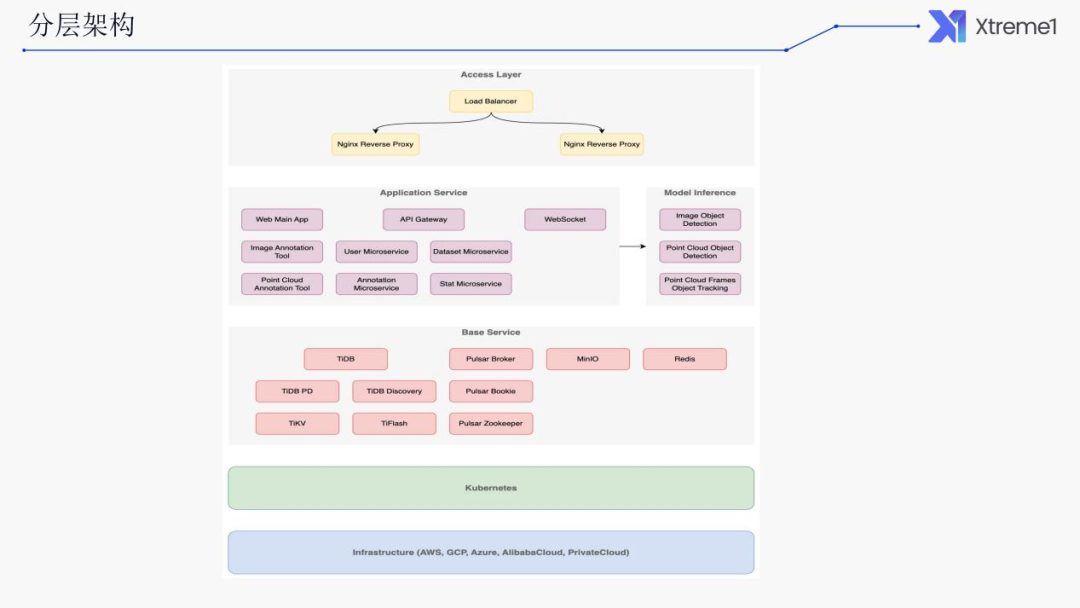
分层架构
首先我们看下整体架构,从上到下分为了五层,是一个分层的架构。第一层是接入层,其中包含了四层(TCP)和七层(HTTP)负载均衡。
接入层:只对外暴露少量服务,大量内部服务对外不可见。
应用服务层:前端和后端均按功能模块拆分了服务,各服务可单独升级。
基础服务层:均为开源软件,且都支持集群模式。
容器抽象层:通过 Kubernetes 提供一致的运行环境,屏蔽底层基础设施差异。
基础设施层:支持各大公有云、私有云,以及裸金属服务器。
结构化数据存储
该部分阐述结构化存储,此处首先结合所面临的技术挑战来看。
技术挑战
海量数据:按 1000 个租户,每个租户 100 万 Data,每个 Data 里有 30 个 Object,那么总的 Object 数量为 300 亿。按每个 Object 1KB 大小计算,则需要的存储空间为 30TB。
这里的 Objects 指的是一张图片或是一帧里有多少辆车或者人等事物。30 是一个比较保守的估计,一些大的高分辨率图片,有时在一张图片里会标出上百甚至几千辆车、几千个人。
数据类型多样且关系复杂:Dataset、Data、Scene、Object、Tracking Object、Class、Classification、Task、Model、Team、User。
在一个 SaaS 平台上,以上数据类型对于租户和用户必不可少。数据又具有复杂的关系,所以这里必须选择关系型的数据库。
统计维度多:Dataset、Task、Performance。
基于上述需求,我们最终选择了分布式关系数据库 TiDB。
解决方案
使用分布式关系数据库 TiDB。
纯分布式架构,拥有良好的扩展性,支持弹性扩缩容。
兼容 MySQL,大多数场景下可直接替换。
支持高可用,少数副本失效情况下能自动修复数据和转移故障。
支持 ACID 事务。
HTAP,同时支持 OLTP + OLAP。
丰富的工具链生态,覆盖部署、迁移、同步、备份等场景。
统计维度多的情况下,如果统计的计算量比较大,传统的方式是把关系性数据处理的数据同步到外部数据库,甚至是像大数据、Clickhouse、Doris 这些外部的分析型数据库里面去。
但这样就需要自己做数据同步,并且去保障数据同步的一致性,特别是在异常情况下一些数据的修复。这样比较复杂,也比较花精力。而TiDB同时支持 HTAP,其内部会完成TiKV 和TiFlash 之间的数据同步。我们知道是关系数据库,它底层的存储引擎,是一个键值对的存储,一个行式的存储。

而TiFlash 是为了分析型的计算做准备的,它采用的是列式存储。列式统计分析中,一般来说我们是对某一个字段进行全表的汇总计算。它更适合列式存储,性能在统计方面会更好。其内部会自己完成 TiKV 和 TiFlash 之间数据的同步。
默认所有表只会写入TiKV 的存储引擎里。如果需要同步到 TiFlash 存储引擎,需要显示对某张表去开启。大家可能只会默认用到它的关系型数据库。显示需要去做分析的部分,则可以开启自动同步。
另外就是它的工具链生态比较丰富,覆盖了部署(比如 K8S 提供了相关的 operator,可以完成自动的部署和升级)、迁移的工具、同步数据的工具备份等等。
上述所说的为结构化数据存储,下文阐述非结构化数据。
非结构化数据存储
技术挑战
数据类型多样:图片、点云、音频、视频、文本等。
数据量大:单个图片从几百 KB到几十 MB,单个点云从几十 MB 到几百 MB,单个租户的数据量就有几十 TB。
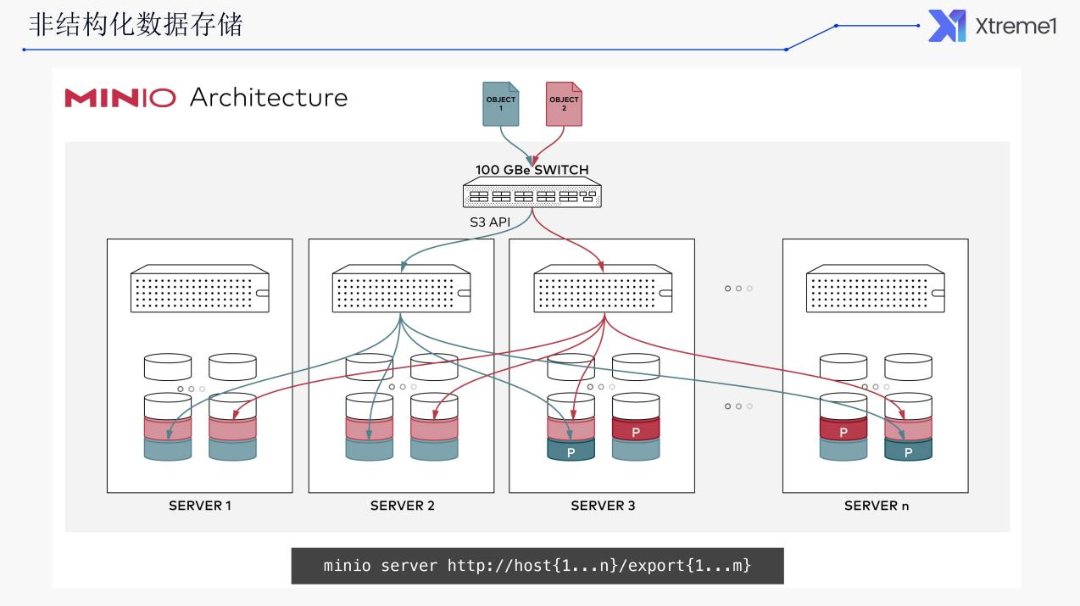
解决方案
使用 MinIO 对象存储。
兼容 S3 API,可无缝替换为各大公有云的对象存储服务。
使用可配置冗余度的纠错码来防止磁盘故障导致的数据丢失。
支持服务端数据加密。
持续复制能及时检测更新并快速复制,因此能支持大规模和跨数据中心场景。
支持跨地域的联邦集群,将多个集群的资源统一在一个命名空间下。
下文我们再看下半结构化数据存储。
半结构化数据存储
前面提到的一些标注物体的数据:2D 框、3D 框还有多边形等等,表述形式差别比较大,所以没办法使用固定的表结构来存储,因此只能以半结构化的 JSON 格式来存储。
挑战
存储挑战:即便是对TiDB这样新兴的分布式关系数据库,存储几百亿记录也是不小的挑战,或者说需要很强的运维团队,且成本很高。
读写挑战:对于连续帧,前端标注工具一次会加载几百个Data的几千个 Object,数据量从几 MB 到几百 MB,数据库存储方案很快就会遇到性能瓶颈。
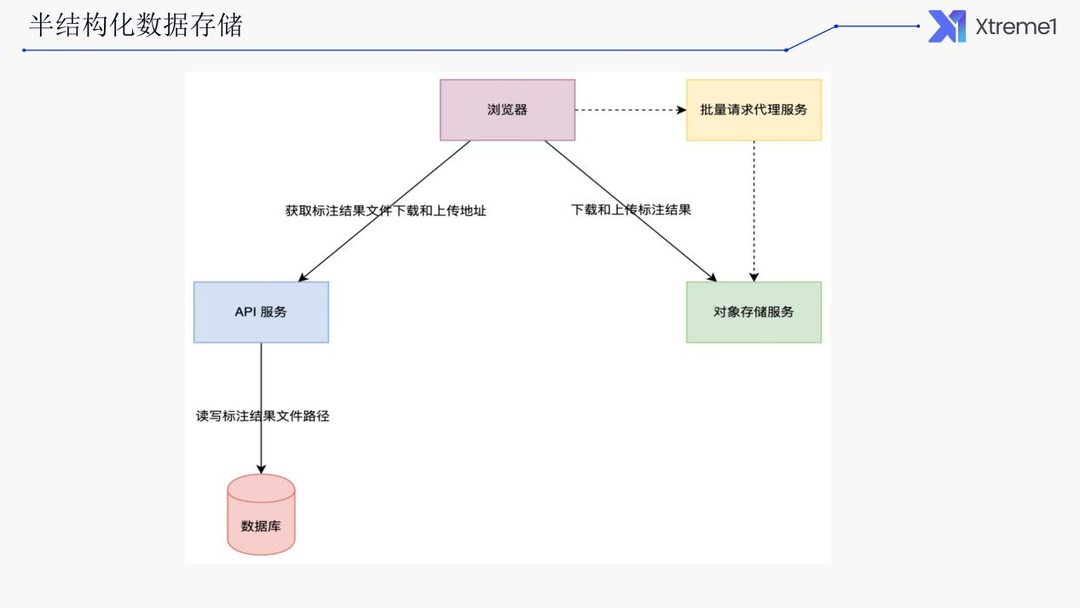
解决方案
我们的解决方案是采用文件存储,以 Data 为粒度存储其所有 Object到一个文件中。
将随机的数据库读写转变为顺序的文件读写。
将数据量最大的Object 从数据库里移走之后,其数据量会降低 1~2个数量级,使用成本大大降低。
如果使用公有云的对象存储服务,那么近乎拥有无限的存储空间和带宽,私有化场景可使用 MinIO 无缝替换。
浏览器直接读写对象存储服务,大大降低了API服务的压力。
上述就结构化、半结构化和非结化数据的存储加以阐述后,我们再看下我们的异步计算。
异步计算
挑战
多样的数据预处理需要异步完成,包括缩略图生成、点云压缩、点云渲染、点云切分、模型识别等。
消息量大,单个操作就会触发几十万的消息产生。
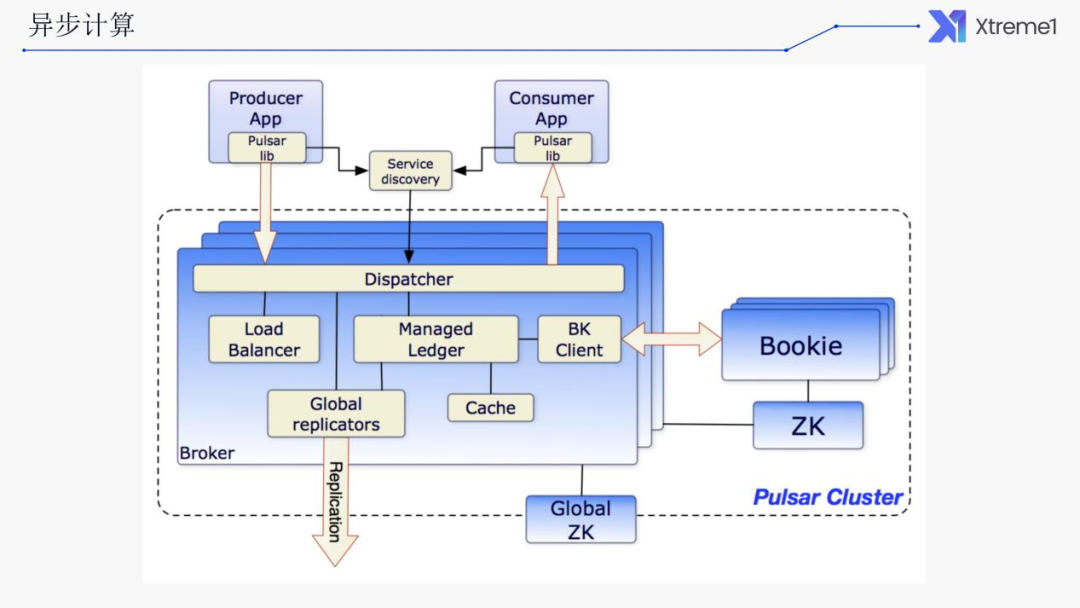
相应的解决方案,我们是采用的 Pulsar 来实现异步和流式的计算。为何要选择Pulsar?
解决方案
使用 Pulsar 消息队列来实现异步和流式计算
云原生友好,存算分离,可独立扩展存储和计算节点。
高性能,超低延时,轻松支持上百万 Topics。
同时支持队列和流两种消息处理模式。
支持共享、排他和故障转移等多种订阅模式。
保证消息不丢。
支持多租户。
通过轻量级的 Serverless 框架 Pulsar Functions 支持流原生的数据处理。
资源调度
再来看下资源调度,首先看下我们所面临的挑战。
挑战
多样化的部署环境:公有云/私有云/裸金属服务器,国内/国外,开发/测试/生产。
服务数量多,部署复杂:前端服务、后端服务、后端 Job、基础服务等累计上百个工作负载。
需要支持弹性扩缩容。
解决方案
Kubernetes + Rancher
使用 Kubernetes 统一部署方式,屏蔽底层基础设施差异。
使用 Rancher 统一管理多个集群,借助于其 UI,不熟悉 Kubernetes 的研发人员也可以部署和管理工作负载。
这么多的集群需要管理,需要一个统一的管理工具,否则在登录每一个集群的管理控制台进行管理,非常不方便。所以我们这里采用的 Kubernetes + Rancher的方案。
下图为架构图。Rancher 本身也是要部署在 K8S 集群里面的,本身也是一个分布式的系统,通过它可以管理多个Cluster。这里 Cluster 1 和 Cluster 2 同时会接入到 Rancher 里面。Rancher 本身也提供了UI,可以去管理它。
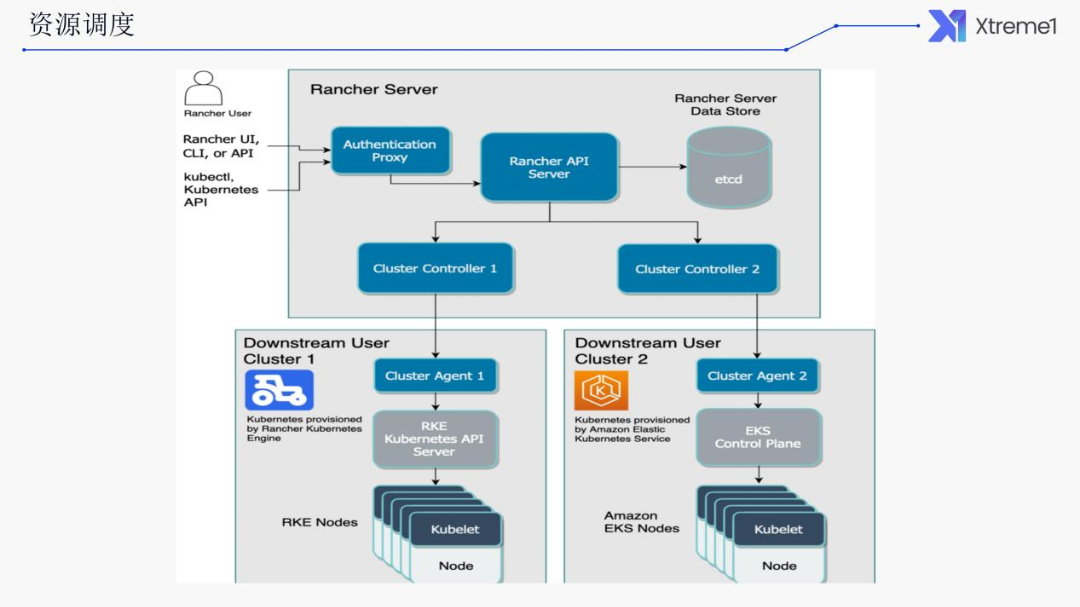
使用该种方案的好处是什么?首先我们使用 Kubernetes 统一部署方式屏蔽底层基础设施的差异。另外,使用 Rancher 可以统一管理多个集群,不用登录每个集群去单独操作。并且账号也是一体的,无需给每个开发人员在每个集群里开账号。
对于不熟悉 Kubernetes 的研发人员,我们也可以进行部署和管理。对工作负载简化了上手门槛,因为可能只有运维人员对 Kubernetes 的命令行操作比较熟悉,大部分的研发人员对Kubernetes 则不然,这也是其门槛比较高的原因所在。
以下是我们现在系统的一张截图,可以看到有多个集群,多个 Kubernetes 集群在某个集群里面的一些工作负载的情况。
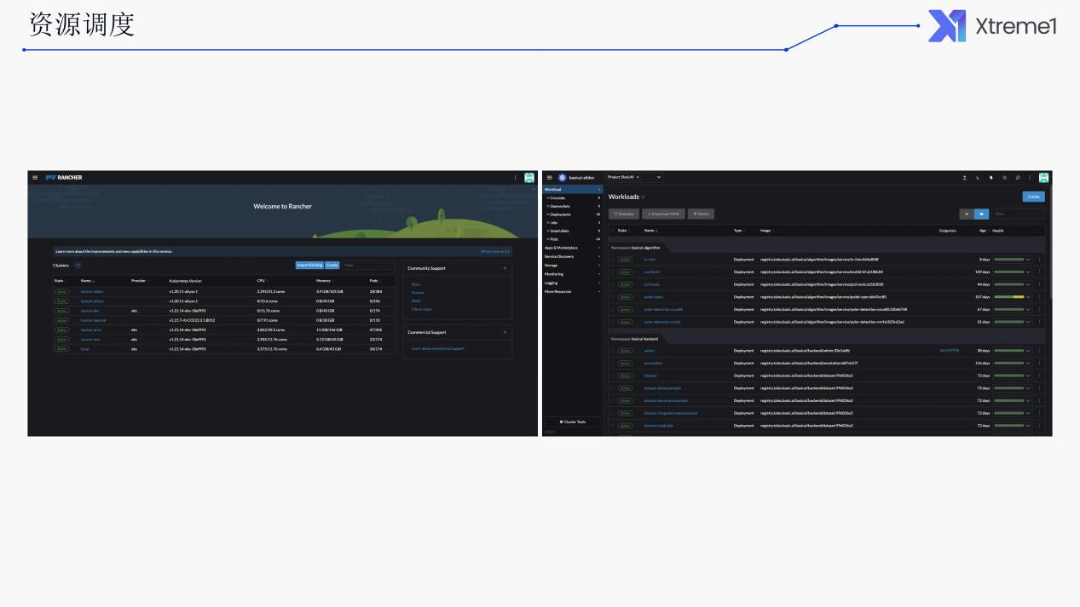
通过它的 UI我们可以重启某一个工作负载,或是重新部署,去调整其副本数等等一些操作。
指标/日志监控
首先看下我们面临的挑战。
挑战
需要监控的资源丰富多样:节点和工作负载资源使用情况、基础服务性能和稳定性、业务指标等。
统一指标和日志监控,方便研发人员查看。
尽量减少资源消耗。
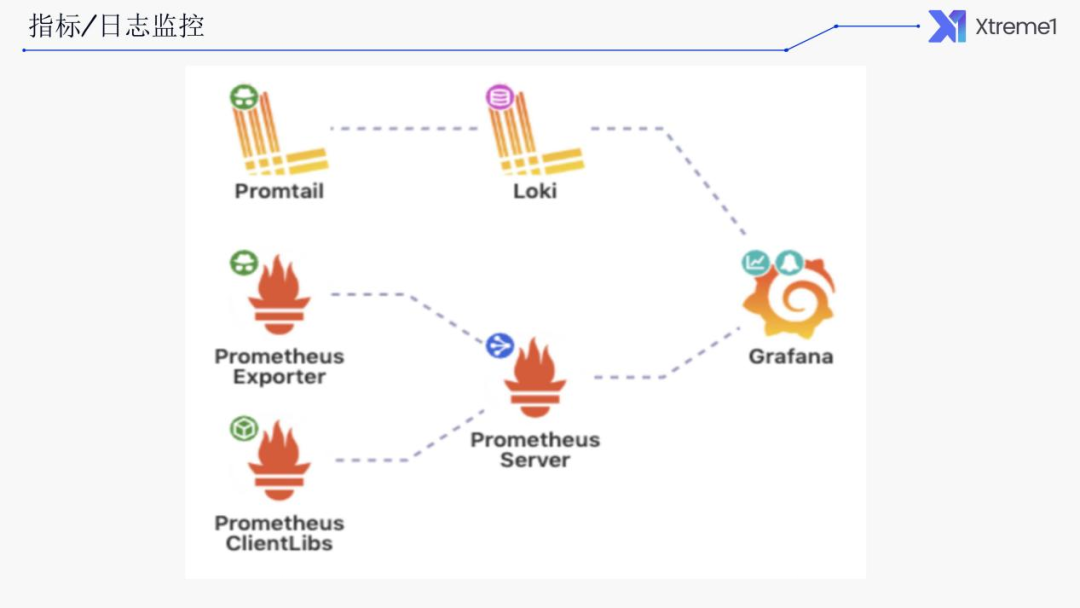
另外希望系统尽量轻量级,不想去采用这种传统的ELK 的一些比较重量级的方案。所以我们选择了 Prometheus + Loki + Grafana 的一套组合。Prometheus 基本上已经是云原生监控的一个标准了,它可以用来当作存储和提供查询的指标。Grafana 用来进行展示,可以将 Prometheus 中的一些数据查询出来做可视化展示。
解决方案
Prometheus + Loki + Grafana
使用 Prometheus 来存储和查询指标,基本上已是云原生监控标准。
使用 Loki 来存储和查询日志,轻量,提供了类似于 PromQL 的 LogQL,可与 Grafana 无缝集成。
使用 Grafana 来统一展示和查询指标和日志数据。
下图为整体架构的图片。所有通过 exporter 将我们的指标上报采集到 Prometheus Server 里面去。通过 Promtail 或是其他日志的采集组件将其采集到 Loki 里面去,然后再通过 Grafana 进行展示。
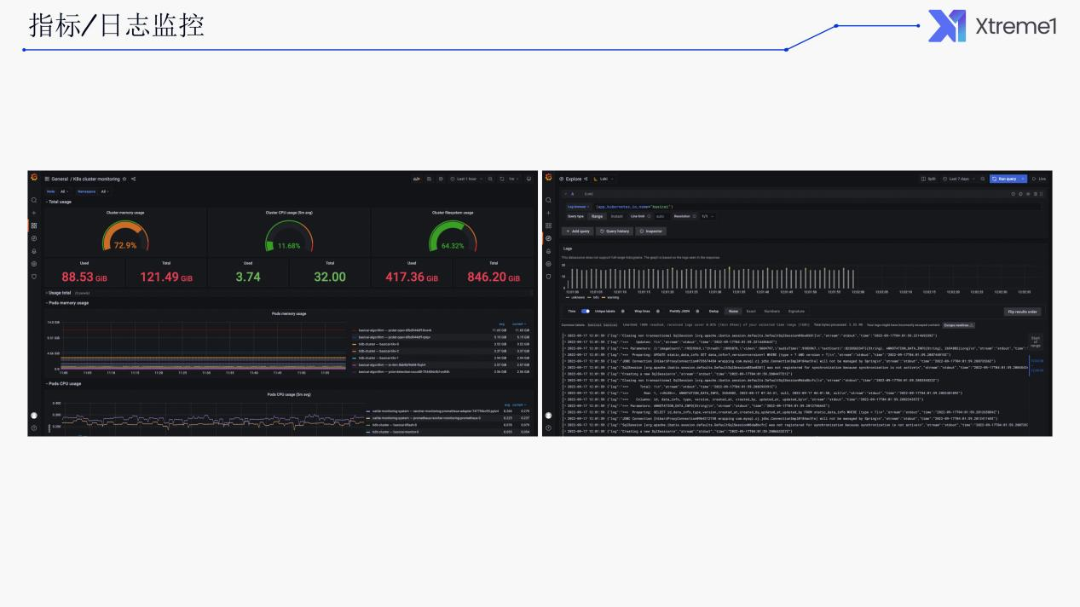
以下是目前系统大体上的一张截图。其中是 K8s 的一些监控指标,以及 local 的一些日志的展示,可以看到日志的上报的频率。近期的一些日志,可以滚动去查询、筛选、过滤。
感兴趣的朋友,可以访问 Xtreme1 在 GitHub 中的仓库:https://github.com/xtreme1-io/xtreme1,查看文档:docs.xtreme1.io,或者访问官网:xtreme1.io 了解更多信息。
|嘉宾介绍|

王家军
倍赛科技应用研发总监
本硕毕业于华中科技大学,曾任职于深圳腾讯、上海盛大、成都数联铭品,目前主要研究方向:微服务架构、云原生、Kubernetes,、DevOps。


