




在前面的文章中我们讲解了 Prometheus Operator 的使用以及有哪些CRD资源。但是在最近使用Prometheus Operator的过程中发现,没有对CRD资源做详细的了解,让自己在使用Prometheus Operator的过程中绕了很多弯路,接下来章节将会带来Prometheus Operator更详细的解读。
Prometheus Operator源码的地址为https://github.com/prometheus-operator/prometheus-operator,而kube-prometheus(Github地址为https://github.com/prometheus-operator/kube-prometheus)提供了快速部署Prometheus Operator、prometheus、Alertmanger、node-exporter、grafana等组件的方法。
同时,kube-Prometheus在部署以上组件的同时,内置了许多的监控规则、Grafana dashboards 以便于很方便地对K8S集群进行监控。
本节我们将详细地介绍kube-Prometheus,首先了解如何使用kube-Prometheus部署Prometheus Operator和其它其管理或使用的组件。
组件介绍
通过README我们知道,kube-Prometheus将包含以上组件的部署

其中Prometheus、Alertmanger、Node Exporter、Grafana为相对比较熟悉的组件。kube-prometheus将以Statefulset控制器的形式部署高可用的Prometheus、Alertmanger;以Daemonset控制器方式运行NodeExporter;以Deployment控制器运行Grafana。
Prometheus Operator
https://github.com/prometheus-operator/prometheus-operator
Prometheus Operator包括但不限于以下特征:
1. 使用k8sCRD部署管理prometheus、Alertmanger和其它相关的组件
2. 配置持久化、保留策略、副本数等Prometheus基础的配置
3.基于label条件,自动集成监控对象至Prometheus。
Prometheus Operator的Pod以Deployment的控制器方式运行在K8S里,通过读取Prometheus、Alertmanger等CRD资源的定义,动态的自动生成配置文件从而管理Prometheus、Alertmanger和其他的组件。
Prometheus Adapter for Kubernetes Metrics APIs
[Github: https://github.com/kubernetes-sigs/prometheus-adapter]
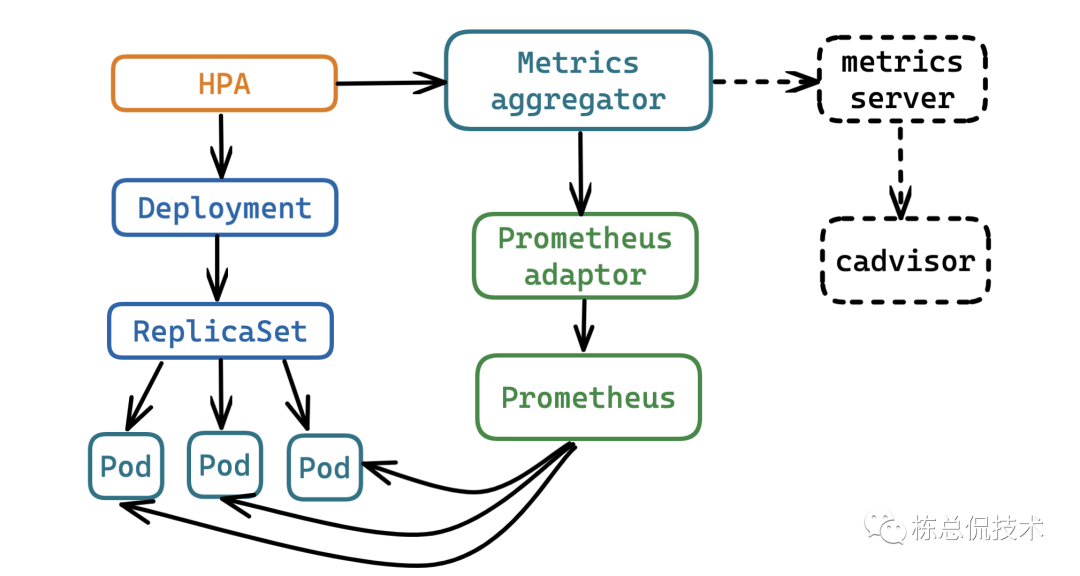
我们通过以下这张图来了解Prometheus adaptor的作用,可以将Prometheus采集到的各种自定义指标聚合至apiserver,供HPA(kubernetes 1.6+)使用。

kube-state-metrics
kube-state-metrics就是一个供Prometheus采集k8s资源的Exporter,其内部实现就是将k8s内部的资源数据,例如Pod重启了多少次、Pod占用内存、deploymentready状态的副本数等转化为Prometheus识别的metrics结构。
通过Prometheus adaptor访问Prometheus可以获取到通过kube-state-metrics采集到的k8s核心指标,这样可以完全取代metrics server。
快速使用
只需要将setup目录和manifests目录下的yaml文件对应的资源在k8s中部署即可。到这里已经根据默认的配置运行起来了Prometheus Operator和其他的组件。
kubectl apply --server-side -f manifests/setup
kubectl apply -f manifests/
生产环境使用
在README中特别强调在部署kube-prometheus到生产环境前,需要阅读以下内容。

Customizing kube-prometheus
这一节描述了如何通过编译自己需要的manifests文件来自定义kube-prometheus 。
kube-prometheus项目由一系列的jsonnet文件(https://jsonnet.org/)组成,通过build.sh将会使用jsonnet语法编译成对应的目标文件存放在manifests文件夹。
在docs\customizations目录介绍了需要自定义修改文件的指导,例如在alertmanager-configuration.md文件中告诉你如何自定义配置alertmanager的配置文件。
首先查看 alertmanager配置定义的文件,可以看到定义了默认的alertmanger配置,可以通过修改这个文件后重新运行build.sh来重新编译生成manifests下对应的alertmanager-secret.yaml文件。
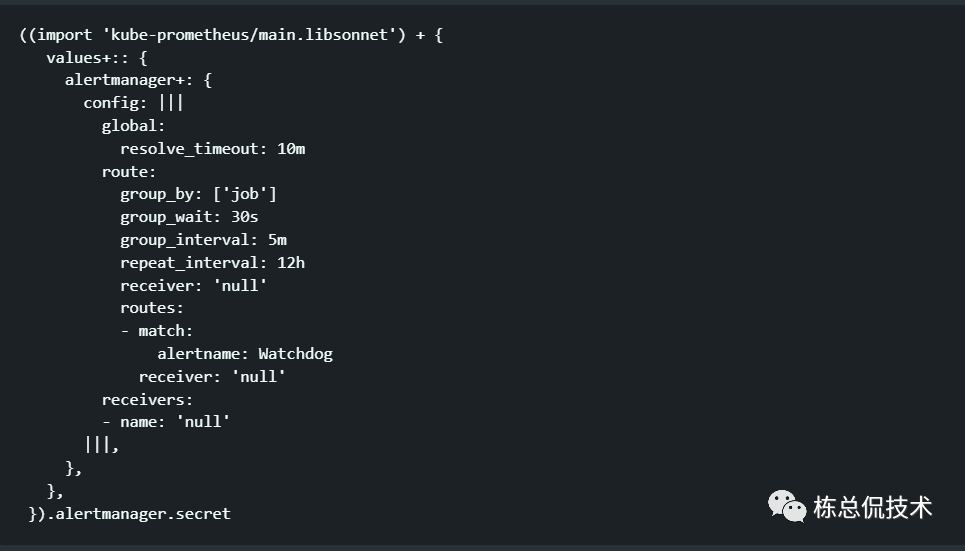
当然对manifests修改,也可以直接对yaml文件直接修改,这一节说明kube-prometheus仓库的组成,以及如何通过jsonnet语法方式组成。
Accessing Graphical User Interfaces
这一节告诉大家通过kubectl port-foward映射本地端口到指定的prometheus、alertmanager、grafana的service,能够方便的访问对应的UI界面
Troubleshooting kube-prometheus
这一节将会讲解常见的几种故障的原因,以及排除方法。
Error retrieving kubelet metrics
首先是无法从kubelet抓取metrics,这绝大部分原因是因为kubelete的权限问题。
我们可以通过Prometheus的targets页面可以看到无法正常访问/metrics接口的http 返回的code。如果是403,则在启动kubelet时增加启动参数。
--authentication-token-webhook=true
如果返回的是401,则设置启动参数
--authorization-mode=Webhook
kube-state-metrics resource usage
在一些环境中 kube-state-metrics需要额外的资源。集群内的命名空间过多或者很多其他的原因会导致kube-state-metrics占用过多资源。
kube-state-metrics的资源分配被addon-resizer管理(https://github.com/kubernetes/autoscaler/tree/master/addon-resizer),addon-resizer会watch其他的pod的资源占用,可以对deployment的副本数进行动态扩缩容。
kube-state-metrics的资源分配被其管理的addon-resizer的配置文件决定,默认的配置为
kubeStateMetrics+:: {
baseCPU: '100m',
cpuPerNode: '2m',
baseMemory: '150Mi',
memoryPerNode: '30Mi',
}
Error retrieving kube-proxy metrics
当无法从kube-proxy获取指标数据时,原因可能是kubeadm配置监听在127.0.0.1,需要修改监听地址为0.0.0.0。有以下两种方式修改配置:
在集群初始化之前,配置kubeadm 的配置项metricsBindAddress为 0.0.0.0:10249
如果k8s集群已经存在,则修改kube-system 命名空间下的configmap kube-proxy,设置metricsBindAddress 地址为0.0.0.0,然后使用命令kubectl -n kube-system rollout restart daemonset kube-proxy 重启kube-proxy。
这一节,我们对kube-prometheus的README整体阅读了一遍,了解了kube-prometheus的组成。
知道如何通过修改jsonnet修改配置,但是这种方式需要对jsonnet语法以及整改仓库的jsonnet组成比较了解,如果是修改使用的配置,对prometheus、alertmanger配置熟悉的同学可以直接修改yaml文件。
