




在很早很早那年,那一夜我成为了ORACLE DBA. 总监说某个页面比较慢,然后叫上JAVA和DBA说,你们去处理下.
发现JAVA发往ORACLE的SQL,没有什么性能问题,而且很快! 后来JAVA工程师发现,每次下一页都要执行SELECT COUNT(*)一次.为此显得比较慢!
然后说这个是从网上拿来的JAVA分页控件! 我以为是类似VB,DELPHI的组件!
2022年今天 过去了8年.在前后段分离编程年代,还有JAVA工程师利于网上的控件,来做分页! 稍微想一下,忽悠谁呢? 你JAVA不就是两个接口而已,一个统计总数的接口,另外一个是返回具体某页数据的接口. 顶多你们封装到类里而已.
我们来分析下分页动作,那怕我们不懂JAVA!
一个分页页面如下HR人事管理
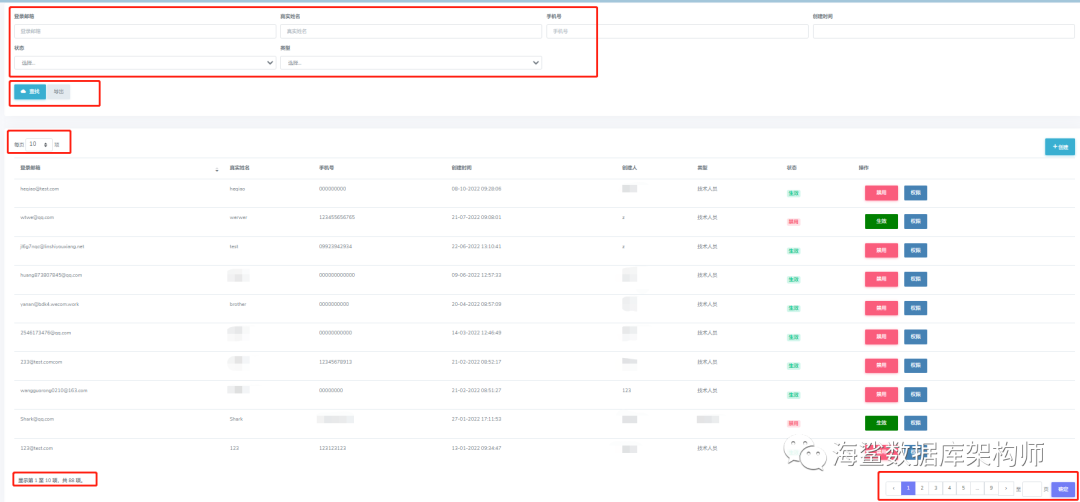
基本上是 条件区, 查找区,每页数量,导航区,显示总页区.
一般用户是怎么操作的呢?
无法就是,从条件区选择好了条件,然后点击查询按钮,然后数据库返回数据来,然后看看,没有的话,就点击导航条的下一页,这里是第2页具体页码.基本上点击10次下一页.
还是没有找到? 有这样的分流
1 点击到最后一页,
2 输入个具体页数进行跳转
3 更换默认的每页行数,基本放大100行每页
4 更换条件重新查找
什么情况下该重新查询呢?
这里意思是说什么情况下,自动代替用户重新查询,就是代替用按查找按钮
1 更换每页行数
2 点击不同的排序字段或者升变降
更换条件呢?
作为技术人员是非常不建议的,这里包含前端,后端和数据端工程师.
为什么呢? 因为每个条件变化下就自动查询一次,如果条件多余2个就变慢,比如说5个条件,用户要重新修改条件,要改4个条件,那么前3次重新查询显得非常没有必要. 而且速度不够快的话,会影响用户下个条件选择,让用户等待. 前端是刷新整个页面,还是局部区呢?
当然产品经理,老板和总监坚持的话, 就无所谓啦!
小结下,前端设计分页基本没有什么难度,无法就是条件选择, 每页行数选择,排序选择 这三个发生变化后才要重新拉一遍数据. 导航条上的四个按钮,和直接跳转某页,没有必要重新拉.
大约2个方法, 查找&重查方法和某页的方法.
查找&重查方法实现功能,把所有条件选择项,每页行数和排序字段打包成JSON 传给后端接口.
某页的方法,功能就是把条件也打包成JSON,并要求第几页到第几页,MYSQL要求算出第行到第几行来.
后端设计
其实也不难一个接口就能搞定, 不过我这里是两个接口.
第一个接口就是GetCount
另外个接口就是 ListPage
这样两前端 查找&重查方法同时请求两个接口,而某页的方法就请求ListPage接口.
Mybaits 设计
MySQL一般使用 LIMIT 实现分页。基本语句为:
SELECT *FROM articlesWHERE category_id = 123ORDER BY idLIMIT 50, 10 ;
深翻页
随着数据量的增加,页数会越来越多,查看后几页的SQL就可能类似下面这种:
SELECT *FROM articlesWHERE category_id = 123ORDER BY idLIMIT 10000, 10;
可以看出,越往后分页,LIMIT 语句的偏移量就会越大,速度也会明显变慢。
此时,网络大佬可以通过子查询的方式来提高分页效率:
SELECT *FROM articlesWHERE id >=(SELECT idFROM articlesWHERE category_id = 123ORDER BY id LIMIT 10000, 1)AND category_id = 123ORDER BY id LIMIT 10;
还可以通过 JOIN 方式来实现分页查询:
SELECT *FROM articles AS t1JOIN(SELECT idFROM articlesWHERE category_id = 123ORDER BY id LIMIT 10000, 1) AS t2WHERE t1.id >= t2.idAND t1.category_id = 123ORDER BY t1.id LIMIT 10;
实际可以利用类似策略模式的方式去处理分页,比如判断如果是一百页以内,就使用最基本的分页方式,大于一百页,则使用子查询的分页方式。
小仙我说,以上的情况你非常小概率碰到,实际上遇到的分页SQL如下
SELECT a.*FROM articles aleft join user b on a.id=b.idleft join Money c on b.id=c.idleft join Bank d on d.id=b.bank_idWHERE 1=1<if test=CateGoryId!=NULL>and category_id = 123</if><if test=.....>and c.mount >1000</if><if ......>ORDER BY<if....>a.create_time desc</if>....LIMIT 10000, 1
上面是JAVA MYBAITS文件组成动态SQL
以前文章说过 MYSQL的LEFT JOIN 会变成INNER JOIN.而INNER JOIN 会导致执行计划的改变,改变原本的驱动表!
因为是INNER JOIN 起到筛选主表的数据, 那么ID基本是无效了.网络上依旧主表ID排序 分页和深翻页技巧就不实际了.
再说排序字段 可能来之主表的不同字段,根据ID来排序就行不通了.
如何解决深翻页? 小仙我提供如下方案
方案一 限制深翻页
直接限制用点击最后一页,或者说固定100页,超过100页就说不行.
缺点就是 改变用户使用习惯,产品经理会比较反对
方案二 限制返回数据量
主表返回36万行数据,然后深翻到最一后页是很恐怖的.
其实很多时候用户仔细看每一笔数据,或者说36万数据都要看一眼,那是上帝.
很多用户只看1000行数据,我们顶多返回1万数据给前端.
select a.*from(SELECT x.*FROM articles xlimit 10000) aleft join user b on a.id=b.idleft join Money c on b.id=c.idleft join Bank d on d.id=b.bank_idwhere 1=1.....order by a.create_time desclimit 1000,10;
缺点是: 可能用户需要的数据在1万之外,通过各种条件组合还是在1万之外.
这样产品经理还是有点不同意
方案三 前端和后端分页
大意是 后端获取结果集ID 放入数组里面,
然后要第几行到第几行,直接从数组取走它们的ID,传给数据库,然后获得全部数据.
SELECT a.idFROM articles aleft join user b on a.id=b.idleft join Money c on b.id=c.idleft join Bank d on d.id=b.bank_idWHERE 1=1.....order by a.create_time desc
SELECT a.*,b.name,c.money,d.bank_nameFROM articles aleft join user b on a.id=b.idleft join Money c on b.id=c.idleft join Bank d on d.id=b.bank_idWHERE 1=1a.id in (....)
缺点是 不太经济,深翻页的人太少,概率不超过1%. 因为获取所有ID的SQL执行时间也很高,数量越大也越慢.
方案 四 先过滤再关联
select a.*,b.name,c.money,d.bank_namefrom(SELECT x.*FROM articles x<if test b表条件有则关联>left join user b on a.id=b.id<if test C表条件有则关联>left join Money c on b.id=c.id<if test D 表条件有则关联>left join Bank d on d.id=b.bank_idwhere 1=1....order by x.create_time desclimit 10000,10) aleft join user b on a.id=b.idleft join Money c on b.id=c.idleft join Bank d on d.id=b.bank_id
经测试 这样可以提高30%的性能, 如果Left join 变成
straight_join
